一、说明
![]()
自从稳定扩散风靡全球以来,人们一直在寻找更好地控制生成过程结果的方法。ControlNet提供了一个最小的界面,允许用户在很大程度上自定义生成过程。使用 ControlNet,用户可以轻松地使用不同的空间上下文(如深度图、分割图、涂鸦、关键点等)来调节生成!
我们可以将卡通图画变成具有令人难以置信的连贯性的逼真照片。
| 现实的洛菲女孩 |
|---|
|
|

甚至将其用作您的室内设计师。
| 以前 | 后 |
|---|---|
|
|
|


您可以将草图涂鸦变成艺术图画。
| 以前 | 后 |
|---|---|
|
|

此外,使一些著名的徽标栩栩如生。
| 以前 | 后 |
|---|---|
|
|
|


有了控制网,天空就是极限 🌠
在这篇博文中,我们首先介绍了StableDiffusionControlNetPipeline,然后展示了如何将其应用于各种控制条件。让我们开始控制吧!
二、控制网:TL;DR
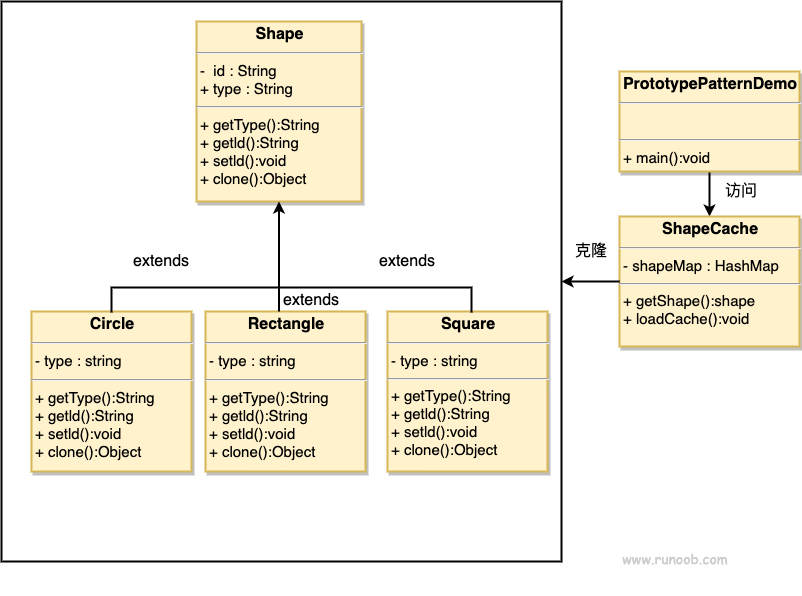
ControlNet是由Lvmin Zhang和Maneesh Agrawala在将条件控制添加到文本到图像扩散模型中引入的。 它引入了一个框架,允许支持各种空间上下文,这些上下文可以作为扩散模型(如稳定扩散)的附加条件。 扩散器实现改编自原始源代码。
训练控制网由以下步骤组成:
- 克隆扩散模型的预训练参数,例如稳定扩散的潜在UNet(称为“可训练副本”),同时单独维护预训练参数(“锁定副本”)。这样做是为了使锁定的参数副本可以保留从大型数据集中学到的大量知识,而可训练副本用于学习特定于任务的方面。
- 参数的可训练和锁定副本通过“零卷积”层连接(有关更多信息,请参阅此处),这些层作为 ControlNet 框架的一部分进行了优化。这是一种训练技巧,用于在训练新条件时保留冻结模型已经学习的语义。
从图形上看,训练 ControlNet 如下所示:
该图取自此处。
用于类似 ControlNet 的训练集的示例如下所示(通过边缘映射进行附加条件):
| 提示 | 原始图像 | 调节 |
|---|---|---|
| “鸟” |
|
|


Similarly, if we were to condition ControlNet with semantic segmentation maps, a training sample would be like so:
| Prompt | Original Image | Conditioning |
|---|---|---|
| “大房子” |
|
|


每种新的调节类型都需要训练一个新的 ControlNet 权重副本。 本文提出了 8 种不同的调节模型,这些模型在扩散器中都支持!
为了进行推理,需要预先训练的扩散模型权重以及经过训练的 ControlNet 权重。例如,与仅使用原始的稳定扩散模型相比,将稳定扩散 v1-5 与 ControlNet 检查点一起使用需要大约 700 亿个参数,这使得 ControlNet 的内存成本更高。
由于预训练的扩散模型在训练期间被锁定,因此在使用不同的条件反射时只需切换 ControlNet 参数。这使得它相当简单 在一个应用程序中部署多个 ControlNet 权重,如下所示。
三、这StableDiffusionControlNetPipeline
在我们开始之前,我们要向社区贡献者Takuma Mori大声疾呼,感谢他领导了ControlNet与Diffusers ❤️的集成。
为了试验ControlNet,Diffusers公开了StableDiffusionControlNetPipeline,类似于 其他扩散器管道。该参数的核心是允许我们提供特定训练的 ControlNetModel 实例,同时保持预训练的扩散模型权重相同。StableDiffusionControlNetPipelinecontrolnet
我们将在这篇博文中探索不同的用例。我们将要介绍的第一个 ControlNet 模型是 Canny 模型 - 这是最受欢迎的模型之一,它生成了一些您在互联网上自由看到的惊人图像。StableDiffusionControlNetPipeline
我们欢迎您使用此 Colab 笔记本运行以下各节中显示的代码片段。
在开始之前,让我们确保已安装所有必要的库:
pip install diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
要根据所选的 ControlNet 处理不同的条件,我们还需要安装一些 其他依赖项:
- OpenCV
- controlnet-aux - ControlNet 预处理模型的简单集合
pip install opencv-contrib-python
pip install controlnet_aux
我们将使用名画“带珍珠的女孩”作为这个例子。所以,让我们下载图像并看一下:
from diffusers.utils import load_imageimage = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image

接下来,我们将图像通过精明的预处理器:
import cv2
from PIL import Image
import numpy as npimage = np.array(image)low_threshold = 100
high_threshold = 200image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image
如我们所见,它本质上是边缘检测:

现在,我们加载跑道爱我的生活/稳定扩散-v1-5以及用于精明边缘的ControlNet模型。 模型以半精度 () 加载,以实现快速且节省内存的推理。torch.dtype
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torchcontrolnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
我们没有使用稳定扩散的默认PNDMScheduler,而是使用当前最快的PNDMScheduler之一。 扩散模型调度器,称为UniPCMultistepScheduler。 选择改进的调度程序可以大大减少推理时间 - 在我们的例子中,我们能够将推理步骤的数量从 50 减少到 20,同时或多或少 保持相同的图像生成质量。有关调度程序的更多信息,请参阅此处。
from diffusers import UniPCMultistepSchedulerpipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
我们不是将我们的管道直接加载到 GPU,而是启用智能 CPU 卸载 可以通过enable_model_cpu_offload功能实现。
请记住,在推理扩散模型(如稳定扩散)期间,不仅需要一个模型组件,还需要多个按顺序运行的模型组件。 在ControlNet稳定扩散的情况下,我们首先使用CLIP文本编码器,然后使用扩散模型unet和控制网,然后使用VAE解码器,最后运行安全检查器。 大多数组件在扩散过程中只运行一次,因此不需要一直占用 GPU 内存。通过启用智能模型卸载,我们确保 每个组件仅在需要时加载到 GPU 中,以便我们可以显着节省内存消耗,而不会显着减慢 infenence。
注意:运行时,请勿使用 手动将管道移动到 GPU - 启用 CPU 卸载后,管道会自动处理 GPU 内存管理。enable_model_cpu_offload.to("cuda")
pipe.enable_model_cpu_offload()
最后,我们想充分利用惊人的FlashAttention/xformers注意力层加速,所以让我们启用它!如果此命令对您不起作用,则您可能没有正确安装。 在这种情况下,您可以跳过以下代码行。xformers
pipe.enable_xformers_memory_efficient_attention()
现在我们已经准备好运行 ControlNet 管道了!
我们仍然提供提示来指导图像生成过程,就像我们通常使用稳定扩散图像到图像管道所做的那样。但是,ControlNet 将允许对生成的图像进行更多控制,因为我们将能够使用我们刚刚创建的精明边缘图像控制生成图像中的确切构图。
看到一些当代名人为这幅 17 世纪完全相同的画作摆姿势的图像会很有趣。使用ControlNet真的很容易做到这一点,我们所要做的就是在提示中包含这些名人的名字!
让我们首先创建一个简单的帮助程序函数,将图像显示为网格。
def image_grid(imgs, rows, cols):assert len(imgs) == rows * colsw, h = imgs[0].sizegrid = Image.new("RGB", size=(cols * w, rows * h))grid_w, grid_h = grid.sizefor i, img in enumerate(imgs):grid.paste(img, box=(i % cols * w, i // cols * h))return grid
接下来,我们定义输入提示并设置可重现性的种子。
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]
最后,我们可以运行管道并显示图像!
output = pipe(prompt,canny_image,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,num_inference_steps=20,generator=generator,
)image_grid(output.images, 2, 2)

我们也可以毫不费力地将控制网络与微调相结合!例如,我们可以用DreamBooth微调一个模型,并使用它来将自己渲染成不同的场景。
在这篇文章中,我们将以我们心爱的土豆头先生为例,展示如何将ControlNet与DreamBooth一起使用。
我们可以使用相同的控制网。但是,我们将不使用稳定扩散 1.5,而是将马铃薯头先生模型加载到我们的管道中 - 马铃薯头先生是一个稳定扩散模型,使用 Dreambooth 🥔 对马铃薯头先生概念进行了微调
让我们再次运行上述命令,保持相同的控制网!
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionControlNetPipeline.from_pretrained(model_id,controlnet=controlnet,torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
现在让我们让土豆先生为约翰内斯·维米尔摆姿势!
generator = torch.manual_seed(2)
prompt = "a photo of sks mr potato head, best quality, extremely detailed"
output = pipe(prompt,canny_image,negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",num_inference_steps=20,generator=generator,
)
output.images[0]
值得注意的是,土豆头先生不是最佳人选,但他尽力了,在捕捉一些精髓🍟方面做得很好。

ControlNet 的另一个独家应用是,我们可以从一个图像中取出一个姿势,并重复使用它来生成具有完全相同姿势的不同图像。因此,在下一个示例中,我们将教超级英雄如何使用Open Pose ControlNet进行瑜伽!
首先,我们需要获得一些人们做瑜伽的图像:
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url) for url in urls
]image_grid(imgs, 2, 2)

现在,让我们使用 OpenPose 预处理器提取瑜伽姿势,这些预处理器可通过 .controlnet_aux
from controlnet_aux import OpenposeDetectormodel = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
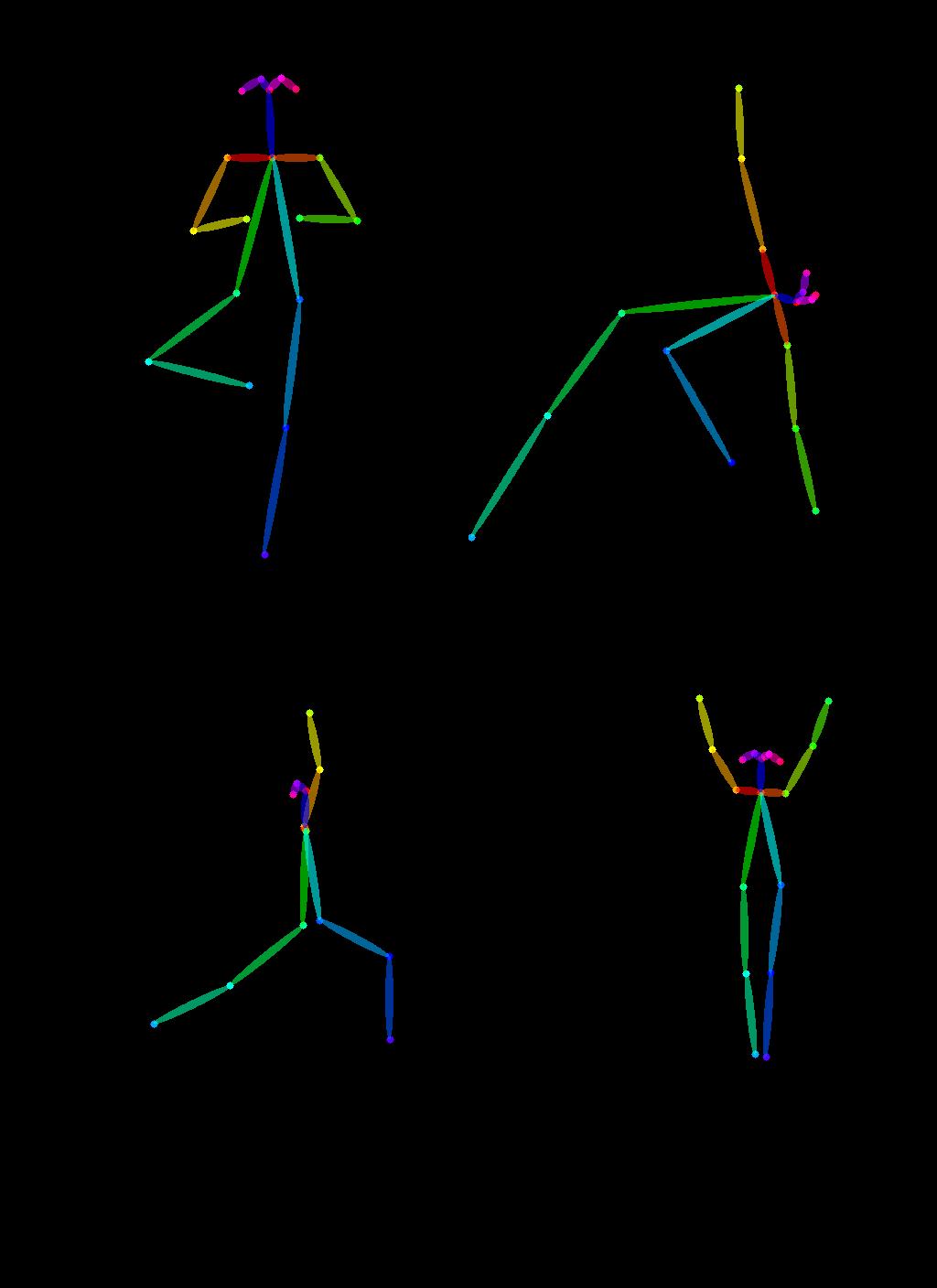
要使用这些瑜伽姿势来生成新图像,让我们创建一个开放的姿势控制网。我们将生成一些超级英雄图像,但在上面显示的瑜伽姿势中。我们走吧 🚀
controlnet = ControlNetModel.from_pretrained("fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(model_id,controlnet=controlnet,torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
现在是瑜伽时间!
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe([prompt] * 4,poses,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,generator=generator,num_inference_steps=20,
)
image_grid(output.images, 2, 2)

3.1 结合多种条件
可以组合多个 ControlNet 条件来生成单个图像。将 ControlNet 列表传递给管道的构造函数,并将相应的条件列表传递给 。__call__
组合条件反射时,屏蔽条件以使它们不重叠是有帮助的。在示例中,我们遮罩了姿势条件反射所在的精明地图的中间。
改变 s 以强调一个条件反射而不是另一个条件也会有所帮助。controlnet_conditioning_scale
3.2 精明调理
原始图像

3.2.1 准备调理
from diffusers.utils import load_image
from PIL import Image
import cv2
import numpy as np
from diffusers.utils import load_imagecanny_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)low_threshold = 100
high_threshold = 200canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)# zero out middle columns of image where pose will be overlayed
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image)

3.3 开姿势条件反射
原始图像

3.3.1 准备调理
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_imageopenpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")openpose_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image)
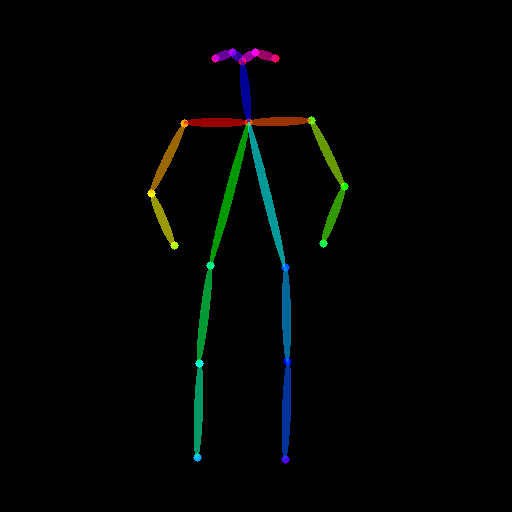
3.3.2 运行具有多种条件的控制网
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torchcontrolnet = [ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
]pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"generator = torch.Generator(device="cpu").manual_seed(1)images = [openpose_image, canny_image]image = pipe(prompt,images,num_inference_steps=20,generator=generator,negative_prompt=negative_prompt,controlnet_conditioning_scale=[1.0, 0.8],
).images[0]image.save("./multi_controlnet_output.png")

在整个示例中,我们探索了StableDiffusionControlNetPipeline的多个方面,以展示它通过扩散器使用ControlNet是多么容易和直观。但是,我们并没有涵盖 ControlNet 支持的所有类型的条件反射。要了解有关这些的更多信息,我们建议您查看相应的模型文档页面:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
- lllyasviel/sd-controlnet-canny
我们欢迎您结合这些不同的元素并与@diffuserslib分享您的结果。请务必查看 Colab 笔记本 以上述一些示例为例!
我们还展示了一些技术,通过使用快速调度程序、智能模型卸载和 .结合这些技术,V3 GPU 上的生成过程只需 ~100 秒,单个图像⚡️仅消耗 ~4 GB 的 VRAM。 在Google Colab等免费服务上,默认GPU(T5)的生成大约需要4秒,而原始实现需要17秒才能创建相同的结果!组合工具箱中的所有部分是真正的超能力 💪xformersdiffusers
四、结论
我们一直在使用StableDiffusionControlNetPipeline,到目前为止,我们的体验很有趣!我们很高兴看到社区在此管道之上构建的内容。如果您想查看扩散器中支持的其他允许受控生成的管道和技术,请查看我们的官方文档。