介绍 scikit-learn 估计器对象
每个算法都通过“Estimator”对象在 scikit-learn 中公开。 例如,线性回归是:sklearn.linear_model.LinearRegression
![]()
估计器参数:估计器的所有参数都可以在实例化时设置:

拟合数据
让我们用 numpy 创建一些简单的数据:

估计参数:当数据与估计器拟合时,根据手头的数据估计参数。 所有估计参数都是估计器对象的属性,以下划线结尾:

监督学习:分类和回归
在监督学习中,我们有一个由特征和标签组成的数据集。 任务是构建一个估计器,能够在给定特征集的情况下预测对象的标签。 一个相对简单的例子是根据一组鸢尾花的测量值来预测鸢尾花的种类。 这是一个相对简单的任务。
一些更复杂的例子是: 通过望远镜给出一个物体的多色图像,确定该物体是恒星、类星体还是星系。
给出一个人的照片,识别照片中的人。
给定一个人看过的电影列表以及他们对电影的个人评分,推荐他们想要的电影列表(所谓的推荐系统:一个著名的例子是Netflix 奖)。
提示:这些任务的共同点是,存在一个或多个与对象相关的未知量,需要根据其他观测到的量来确定。
监督学习进一步分为两类:分类和回归。
在分类中,标签是离散的,而在回归中,标签是连续的。 例如,在天文学中,确定一个物体是恒星、星系还是类星体的任务是一个分类问题:标签来自三个不同的类别。 另一方面,我们可能希望根据这样的观察来估计对象的年龄:这将是一个回归问题,因为标签(年龄)是一个连续量。
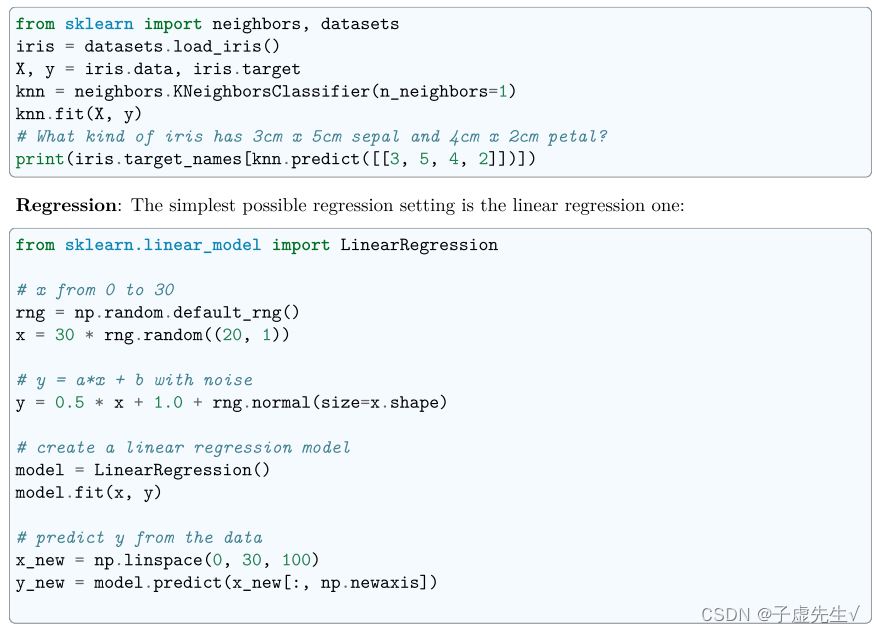
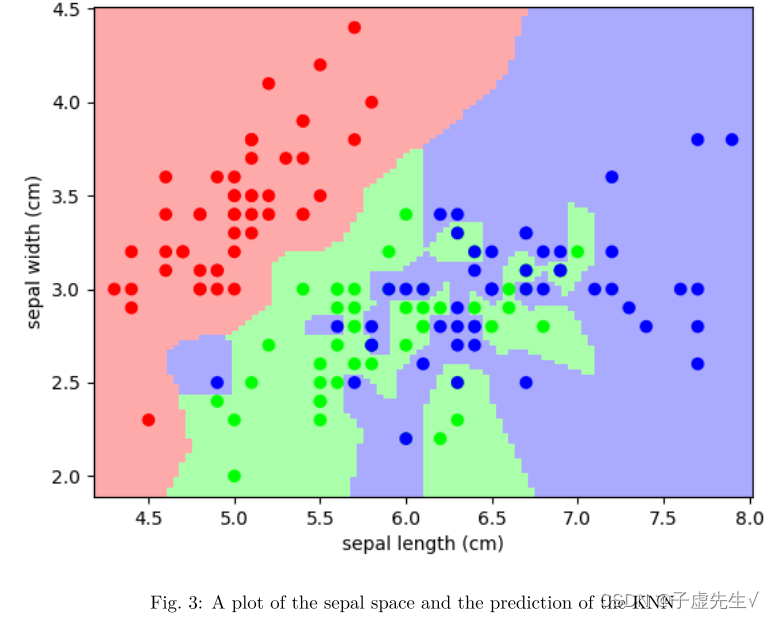
分类:K 最近邻 (kNN) 是最简单的学习策略之一:给定一个新的未知观察,在参考数据库中查找哪些具有最接近的特征并分配主要类别。 让我们尝试一下分类问题:
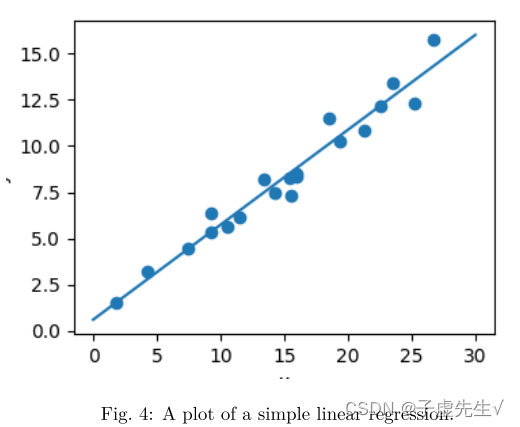
Scikit-learn估计器接口概述
Scikit-learn致力于在所有方法中提供统一的接口,我们将在下面看到这些示例。给定一个名为model的scikit-learn估计器对象,可以使用以下方法:
model.fit():拟合训练数据。对于监督学习应用程序,它接受两个参数:数据X和标签y(例如model.fit(X,y))。对于无监督学习应用程序,它只接受一个参数,即数据X(例如model.fit(X))。
model.predict():给定一个训练好的模型,预测一组新数据的标签。该方法接受一个参数,即新数据X_new(例如model。predict(X_new)),并返回数组中每个对象的学习标签。model.predict_proba():对于分类问题,一些估计器也提供了这种方法,它返回新观测具有每个分类标签的概率。在这种情况下,具有最高概率的标签由model.predict()返回。
model.score():对于分类或回归问题,大多数估计器实现评分方法。分数介于0和1之间,分数越大表示拟合度越好。model.transform():给定一个无监督模型,将新数据转换为新的基。这也接受一个参数X_new,并返回基于无监督模型的数据的新表示。
model.fit_transform():一些估计器实现了这种方法,它可以更有效地对相同的输入数据执行拟合和变换。
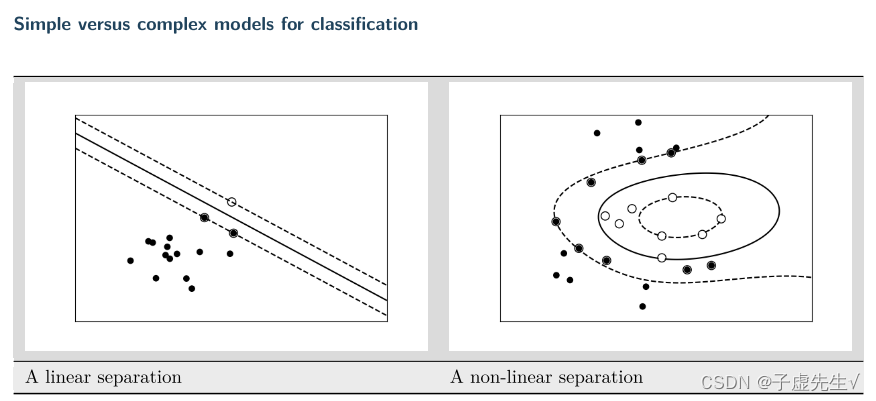
正规化:它是什么以及为什么它是必要的
简单的模型
训练误差
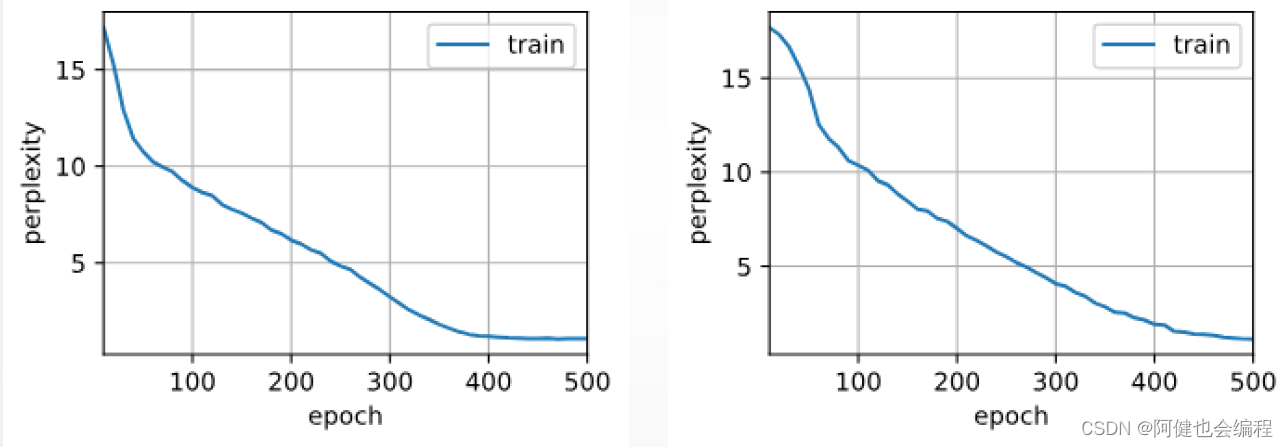
假设您正在使用1-最近邻估计量。你希望你的火车上有多少错误?·训练集误差不是预测性能的良好衡量标准。你需要去掉一个测试集。·一般来说,我们应该接受火车上的错误。
正则化的一个例子
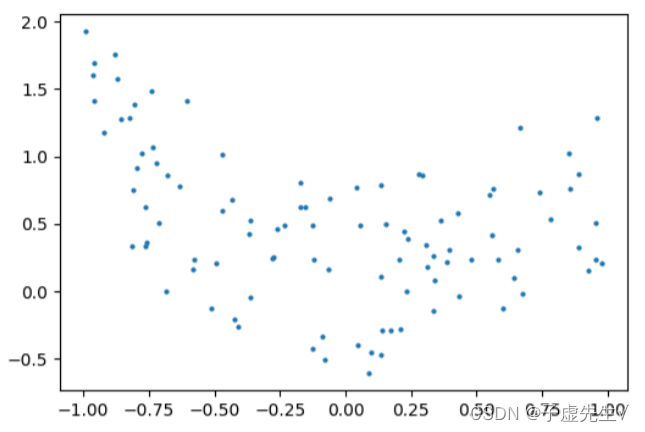
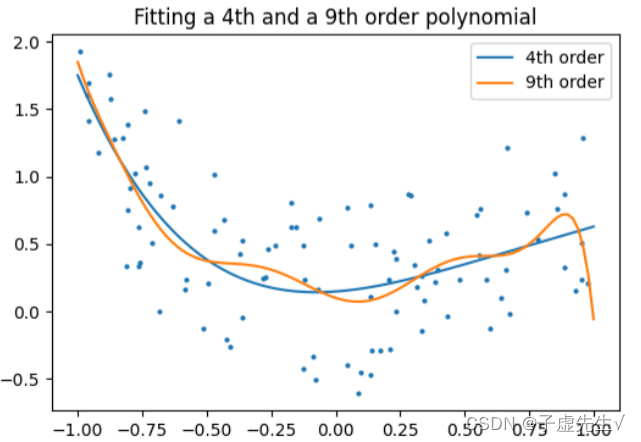
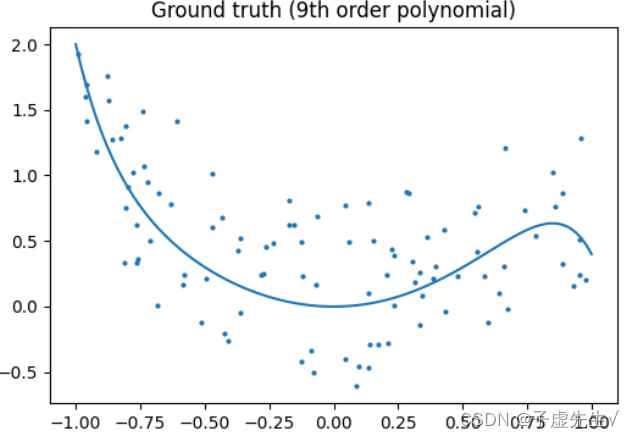
正则化背后的核心思想是,对于“更简单”的某种定义,我们将更喜欢更简单的模型,即使它们会导致训练集上更多的错误。作为一个例子,让我们生成一个9阶多项式,带噪声:现在,让我们将一个4阶和一个9阶多项式拟合到数据中。用你的肉眼,你更喜欢哪种型号,四阶的还是九阶的?让我们看看地面真相:
提示:正则化在机器学习中无处不在。大多数scikit-learn估计器都有一个参数来调整正则化的数量。例如,对于k-NN,它是“k”,即用于做出决策的最近邻居的数量。k=1相当于没有正则化:训练集上的0错误,而大k将在特征空间中推向更平滑的决策边界。


![ES 深度分页问题及针对不同需求下的解决方案[ES系列] - 第509篇](https://img-blog.csdnimg.cn/img_convert/de9dbf52fee84ed2aeeef803d166404e.png)