一、说明
在大型语言模型(LLM)领域,有各种各样的 训练机制,具有不同的手段,要求和目标。由于它们服务于不同的目的,因此重要的是不要将它们相互混淆,并了解它们适用的不同场景。
在本文中,我想概述一些最重要的训练机制,它们是预训练、微调、从人类反馈中强化学习 (RLHF) 和适配器。此外,我将讨论提示的作用,它本身不被视为一种学习机制,并阐明提示调优的概念,它在提示和实际训练之间架起了一座桥梁。
二、关于预训练

预训练是最基本的训练方式,等同于你可能知道的其他机器学习领域的训练。在这里,您从一个未经训练的模型(即具有随机初始化权重的模型)开始,并训练以在给定一系列先前令牌的情况下预测下一个令牌。为此,从各种来源收集了大量的句子,并以小块的形式提供给模型。
这里使用的训练模式称为自监督。从正在训练的模型的角度来看,我们可以说是一种监督学习方法,因为模型在做出预测后总是得到正确的答案。例如,给定我喜欢冰的序列... 该模型可能会将锥体预测为下一个单词,然后可能会被告知答案是错误的,因为实际的下一个单词是奶油色。最终,可以计算损失并调整模型权重以更好地预测下一次。将其称为自我监督(而不是简单地监督)的原因是,无需事先以昂贵的程序收集标签,但它们已经包含在数据中。给定句子我喜欢冰淇淋,我们可以自动将其拆分为我喜欢冰作为输入和奶油作为标签,这不需要人工努力。虽然它不是模型本身,但它仍然由机器自动执行,因此人工智能在学习过程中自我监督的想法。
最终,在大量文本上进行训练后,模型学会了对语言结构进行编码(例如,它学习,我喜欢的后面可以跟一个名词或分词)以及它看到的文本中包含的知识。例如,它了解到,乔·拜登(Joe Biden)这句话......经常被美国总统所跟随,因此代表了该知识。
其他人已经完成了此预训练,您可以使用开箱即用的 GPT 等模型。但是,为什么要训练类似的模型呢?如果您使用的数据具有类似于语言的属性,但这不是通用语言本身,则可能需要从头开始训练模型。乐谱可以举个例子,它的结构在某种程度上像一种语言。关于哪些部分可以相互跟随,有一些规则和模式,但是在自然语言上训练的LLM无法处理这种数据,因此您必须训练一个新模型。然而,LLM的架构可能是合适的,因为乐谱和自然语言之间有许多相似之处。
三、关于微调

尽管预训练的LLM由于其编码的知识,能够执行各种数量的任务,但它有两个主要缺点,即其输出的结构和缺乏未在数据中编码的知识首先。
如您所知,LLM 总是在给定之前一系列令牌的情况下预测下一个令牌。对于继续一个给定的故事,这可能很好,但在其他情况下这不是你想要的。如果您需要不同的输出结构,有两种主要方法可以实现。你可以以这样的方式编写提示,使模型预测下一个令牌的惰性能力解决你的任务(这称为提示工程),或者你更改最后一层的输出,使其反映你的任务,就像你在任何其他机器学习模型中所做的那样。考虑一个分类任务,其中有 N 个类。通过提示工程,您可以指示模型始终在给定输入后输出分类标签。通过微调,您可以将最后几层更改为具有 N 个输出神经元,并从激活率最高的神经元中得出预测的类别。
LLM的另一个限制在于它被训练的数据。由于数据源非常丰富,因此最著名的LLM编码了各种各样的常识。因此,他们可以告诉你,除其他外,关于美国总统,贝多芬的主要著作,量子物理学的基础和西格蒙德弗洛伊德的主要理论。但是,有些域模型不知道,如果您需要使用这些域,微调可能与您相关。
微调的想法是采用已经预训练的模型并使用不同的数据继续训练,并在训练期间仅更改最后几层的权重。这只需要初始培训所需资源的一小部分,因此可以更快地执行。另一方面,模型在预训练期间学习的结构仍然编码在第一层中,可以使用。假设你想教你的模型关于你最喜欢的,但鲜为人知的幻想小说,这些小说不是训练数据的一部分。通过微调,您可以利用模型对自然语言的一般知识,使其理解奇幻小说的新领域。
四、RLHF微调

微调模型的一个特例是从人类反馈中强化学习(RLHF),这是GPT模型与Chat-GPT等聊天机器人之间的主要区别之一。通过这种微调,模型被训练为产生人类在与模型对话中最有用的输出。
主要思想如下:给定任意提示,为该提示生成模型的多个输出。人类根据他们发现的有用或适当程度对这些输出进行排名。给定四个样本 A、B、C 和 D,人类可能会决定 C 是最佳输出,B 稍差但等于 D,A 是该提示的最差输出。这将导致 C > B = D > A 的阶数。接下来,此数据用于训练奖励模型。这是一个全新的模型,它通过给予反映人类偏好的奖励来学习对LLM的产出进行评级。一旦奖励模型被训练,它就可以替代该产品中的人类。现在,模型的输出由奖励模型进行评级,并且该奖励作为反馈提供给LLM,然后进行调整以最大化奖励;一个与GAN非常相似的想法。
如您所见,对于这种训练,需要人工标记的数据,这需要相当多的努力。然而,所需的数据量是有限的,因为奖励模型的想法是从这些数据中泛化,以便一旦它学会了自己的部分,它就可以自己对LLM进行评级。 RLHF通常用于使LLM输出更像对话或避免不良行为,例如模型是平均的, 侵入性或侮辱性。
五、适配器
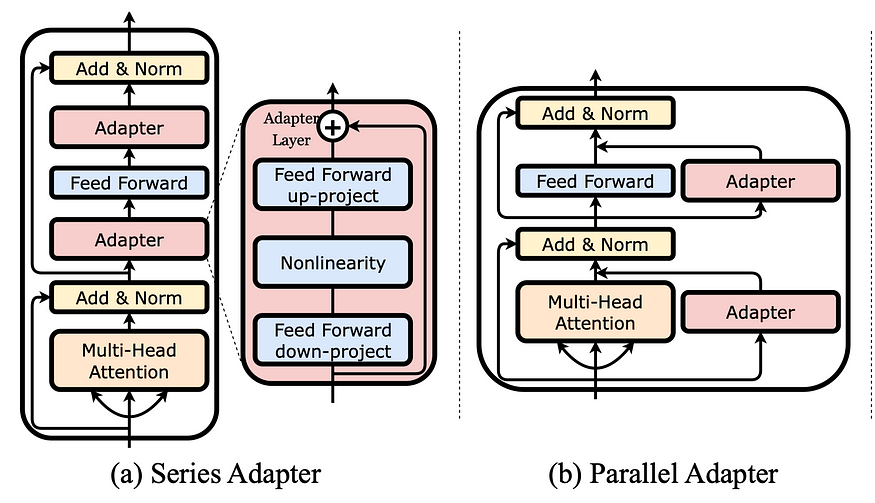
在前面提到的微调中,我们在最后几层调整模型的一些参数,而前几层中的其他参数保持不变。不过,还有另一种选择,它通过训练所需的更少参数来保证更高的效率,这称为dapters。
使用适配器意味着向已训练的模型添加其他层。在微调期间,仅训练这些适配器,而模型的其余参数根本不会更改。但是,这些层比模型附带的层小得多,这使得调整它们变得更加容易。此外,它们可以插入模型的不同位置,而不仅仅是在最后。在上图中,您看到两个示例;一个是以串行方式将适配器作为层添加的,另一个是将其并行添加到现有层。
六、促进

您可能想知道提示是否算作训练模型的另一种方式。提示意味着构造实际模型输入之前的指令,特别是如果您使用少数镜头提示,您可以在提示中向LLM提供示例,这与训练非常相似,后者也包括呈现给模型的示例。但是,提示比训练模型是有原因的。首先,从简单的定义来看,我们只在权重更新时才谈论训练,而在提示期间不会这样做。创建提示时,不会更改任何模型,不会更改权重,不会生成新模型,也不会更改模型中编码的知识或表示形式。提示应该被视为指导LLM并告诉它你想要从中得到什么的一种方式。以以下提示为例:
"""Classify a given text regarding its sentiment.Text: I like ice cream.
Sentiment: negativeText: I really hate the new AirPods.
Sentiment: positiveText: Donald is the biggest jerk on earth. I hate him so much!
Sentiment: neutralText: {user_input}
Sentiment:""" 我指示模型进行情绪分类,您可能已经注意到,我给模型的示例都是错误的!如果模型是用这些数据训练的,它会混淆正、负和中性的标签。现在,如果我让模型对我喜欢冰淇淋的句子进行分类,这是我示例的一部分,会发生什么?有趣的是,它将其归类为正数,这与提示相反,但在语义层面上是正确的。这是因为提示没有训练模型,也没有改变它所学内容的表示形式。提示只是告知模型我期望的结构,即我希望情绪标签(可以是正、负或中性)跟在冒号之后。
七、提示调整

虽然提示本身不是训练 llm,但有一种机制称为提示调整(也称为软提示),它与提示有关,可以看作是一种训练。
在前面的示例中,我们将提示视为提供给模型的自然语言文本,以便告诉它要做什么,并且先于实际输入。也就是说,模型输入变为<prompt><实例>,因此,例如,<将以下内容标记为正、负或中性:> <我喜欢冰淇淋>。 在自己创建提示时,我们说硬提示。在软提示中,将保留格式<prompt><实例>,但提示本身不是我们自己设计的,而是通过数据学习的。具体来说,提示由向量空间中的参数组成,这些参数可以在训练期间进行调整,以获得更小的损失,从而获得更好的答案。也就是说,在训练后,提示将是导致我们给定数据最佳答案的字符序列。但是,模型参数根本没有经过训练。
提示调优的一大优点是,您可以为不同的任务训练多个提示,但仍将它们用于同一模型。就像在硬提示中一样,您可以构造一个用于文本摘要的提示、一个用于情绪分析的提示和一个用于文本分类的提示,但将它们全部用于同一模型,您可以为此目的调整三个提示,并且仍然使用相同的模型。相反,如果您使用微调,您最终会得到三个模型,每个模型只服务于其特定任务。
八、总结
我们刚刚看到了各种不同的训练机制,所以让我们在最后做一个简短的总结。
- 预训练LLM意味着教它以自我监督的方式预测下一个令牌。
- 微调是在最后一层调整预训练LLM的权重,并可用于使模型适应特定的上下文。
- RLHF旨在调整模型的行为以符合人类的期望,并且需要额外的标记工作。
- 适配器允许更有效的微调方式,因为小层被添加到预训练的LLM中。
- 提示本身不被视为训练,因为它不会更改模型的内部表示。
- 提示优化是一种优化权重的技术,这些权重会产生提示,但不会影响模型权重本身。
当然,还有更多的训练机制,每天都有新的机制被发明出来。LLM可以做的不仅仅是预测文本,教他们这样做需要各种技能和技巧,其中一些我刚刚介绍给你。
多利安·德罗斯特