121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4] 输出:5 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1] 输出:0 解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 10^50 <= prices[i] <= 10^4
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int maxProfit(vector<int>& prices) {int minPrice = INT_MAX;int maxProfit = 0;for(int i = 0; i < prices.size(); i++) {if(prices[i] < minPrice) {minPrice = prices[i];} else if(prices[i] - minPrice > maxProfit) {maxProfit = prices[i] - minPrice;}}return maxProfit;}
};int main() {vector<int> prices;int temp;while(cin >> temp) {prices.push_back(temp);if(cin.get() == '\n') break;}Solution solution;cout << solution.maxProfit(prices);return 0;
}122. 买卖股票的最佳时机Ⅱ
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4] 输出:7 解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。总利润为 4 + 3 = 7 。
示例 2:
输入:prices = [1,2,3,4,5] 输出:4 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。总利润为 4 。
示例 3:
输入:prices = [7,6,4,3,1] 输出:0 解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
提示:
1 <= prices.length <= 3 * 10^40 <= prices[i] <= 10^4
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;class Solution {public:int maxProfit(vector<int>& prices) {int n = prices.size();if(n <= 1) {return 0;}int maxProfit = 0;for(int i = 1; i < n; i++) {if(prices[i] > prices[i - 1]) {maxProfit += prices[i] - prices[i - 1];}}return maxProfit;}
};int main() {int tmp;vector<int> prices;while(cin >> tmp) {prices.push_back(tmp);if(cin.get() == '\n')break;}Solution solution;cout << solution.maxProfit(prices) << endl;return 0;
}123. 买卖股票的最佳时机Ⅲ
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:prices = [3,3,5,0,0,3,1,4] 输出:6 解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:
输入:prices = [1,2,3,4,5] 输出:4 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入:prices = [7,6,4,3,1] 输出:0 解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
示例 4:
输入:prices = [1] 输出:0
提示:
1 <= prices.length <= 10^50 <= prices[i] <= 10^5
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;class Solution {public:int maxProfit(vector<int>& prices) {int n = prices.size();if(n <= 1) {return 0;}int maxProfit = 0;vector<int> leftProfit(n, 0);vector<int> rightProfit(n, 0);int minPrice = prices[0];// 每一天左侧的最大利润 for(int i = 1; i < n; i++) {minPrice = min(minPrice, prices[i]);leftProfit[i] = max(leftProfit[i - 1], prices[i] - minPrice);}int maxPrice = prices[n - 1];// 每一天右侧的最大利润 for(int i = n - 2; i >= 0; i--) {maxPrice = max(maxPrice, prices[i]);rightProfit[i] = max(rightProfit[i + 1], maxPrice - prices[i]);}// 将左右两侧的最大利润相加,找出最大的利润值 for(int i = 0; i < n; i++) {maxProfit = max(maxProfit, leftProfit[i] + rightProfit[i]);}return maxProfit;}
};int main() {int tmp;vector<int> prices;while(cin >> tmp) {prices.push_back(tmp);if(cin.get() == '\n')break;}Solution solution;cout << solution.maxProfit(prices) << endl;return 0;
}124. 二叉树中的最大路径和
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:

输入:root = [1,2,3] 输出:6 解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:

输入:root = [-10,9,20,null,null,15,7] 输出:42 解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
提示:
- 树中节点数目范围是
[1, 3 * 104] -1000 <= Node.val <= 1000
#include<algorithm>
#include<iostream>
#include<queue>using namespace std;// Definition for a binary tree node
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:int maxPathSum(TreeNode* root) {int maxSum = INT_MIN;maxPathSumRecursive(root, maxSum);return maxSum;}int maxPathSumRecursive(TreeNode* node, int& maxSum) {if(node == NULL) {return 0;}int leftSum = max(0, maxPathSumRecursive(node->left, maxSum));int rightSum = max(0, maxPathSumRecursive(node->right, maxSum));int currentSum = node->val + leftSum + rightSum;maxSum = max(maxSum, currentSum);return node->val + max(leftSum, rightSum);}
};TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;cout << solution.maxPathSum(root) << endl;return 0;
}
125. 验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
示例 1:
输入: s = "A man, a plan, a canal: Panama" 输出:true 解释:"amanaplanacanalpanama" 是回文串。
示例 2:
输入:s = "race a car" 输出:false 解释:"raceacar" 不是回文串。
示例 3:
输入:s = " " 输出:true 解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。 由于空字符串正着反着读都一样,所以是回文串。
提示:
1 <= s.length <= 2 * 10^5s仅由可打印的 ASCII 字符组成
#include<iostream>
#include<cctype>
using namespace std;class Solution {public:bool isPalindrome(string s) {string processedStr = "";for(int i = 0; i < s.length(); i++) {if(isalnum(s[i])) {processedStr += tolower(s[i]);}}int left = 0, right = processedStr.length() - 1;while(left < right) {if(processedStr[left] != processedStr[right]) {return false;}left++;right--;}return true;}
};int main() {string str;cin >> str;Solution solution;cout << boolalpha << solution.isPalindrome(str);return 0;
}126. 单词接龙Ⅱ
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
- 每对相邻的单词之间仅有单个字母不同。
- 转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。 sk == endWord
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] 解释:存在 2 种最短的转换序列: "hit" -> "hot" -> "dot" -> "dog" -> "cog" "hit" -> "hot" -> "lot" -> "log" -> "cog"
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:[] 解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。
提示:
1 <= beginWord.length <= 5endWord.length == beginWord.length1 <= wordList.length <= 500wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有单词 互不相同
解法一:超出时间限制
#include<iostream>
#include<vector>
#include<queue>
#include<unordered_set>
using namespace std;class Solution {public:// 使用广度优先搜索(BFS)的方法,通过逐步转换单词并在转换过程中保持跟踪路径,// 直到找到最短转换序列或者无法转换为止vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {unordered_set<string> dict(wordList.begin(), wordList.end());vector<vector<string>> result;queue<vector<string>> q;q.push({beginWord});if(dict.find(endWord) == dict.end()) {return result;}bool found = false;while(!q.empty() && !found) {int size = q.size();unordered_set<string> visited;for(int i = 0; i < size; i++) {vector<string> path = q.front();q.pop();string word = path.back();for(int j = 0; j < word.length(); j++) {char originalChar = word[j];for(char c = 'a'; c <= 'z'; ++c) {if(c == originalChar) continue;word[j] = c;if(word == endWord) {path.push_back(word);result.push_back(path);found = true;}if(dict.find(word) != dict.end() && !found) {visited.insert(word);vector<string> newPath = path;newPath.push_back(word);q.push(newPath);}}word[j] = originalChar;}}for(const string& word : visited) {dict.erase(word);}}return result;}
};int main() {vector<string> wordList;string s;string beginWord, endWord;while(cin >> s) {wordList.push_back(s);if(cin.get() == '\n')break;}cin >> beginWord >> endWord;Solution solution;vector<vector<string>> result = solution.findLadders(beginWord, endWord, wordList);for (const std::vector<std::string>& path : result) {for (const std::string& word : path) {std::cout << word << " ";}std::cout << std::endl;}return 0;
}解法二:
#include<iostream>
#include<vector>
#include<queue>
#include<unordered_map>
#include<unordered_set>
#include<set>
using namespace std;class Solution {
public:vector<vector<string>> findLadders(string beginWord, string endWord, vector<string> &wordList) {vector<vector<string>> res;// 因为需要快速判断扩展出的单词是否在 wordList 里,因此需要将 wordList 存入哈希表,这里命名为「字典」unordered_set<string> dict = {wordList.begin(), wordList.end()};// 修改以后看一下,如果根本就不在 dict 里面,跳过if (dict.find(endWord) == dict.end()) {return res;}// 特殊用例处理dict.erase(beginWord);// 第 1 步:广度优先搜索建图// 记录扩展出的单词是在第几次扩展的时候得到的,key:单词,value:在广度优先搜索的第几层unordered_map<string, int> steps = {{beginWord, 0}};// 记录了单词是从哪些单词扩展而来,key:单词,value:单词列表,这些单词可以变换到 key ,它们是一对多关系unordered_map<string, set<string>> from = {{beginWord, {}}};int step = 0;bool found = false;queue<string> q = queue<string>{{beginWord}};int wordLen = beginWord.length();while (!q.empty()) {step++;int size = q.size();for (int i = 0; i < size; i++) {const string currWord = move(q.front());string nextWord = currWord;q.pop();// 将每一位替换成 26 个小写英文字母for (int j = 0; j < wordLen; ++j) {const char origin = nextWord[j];for (char c = 'a'; c <= 'z'; ++c) {nextWord[j] = c;if (steps[nextWord] == step) {from[nextWord].insert(currWord);}if (dict.find(nextWord) == dict.end()) {continue;}// 如果从一个单词扩展出来的单词以前遍历过,距离一定更远,为了避免搜索到已经遍历到,且距离更远的单词,需要将它从 dict 中删除dict.erase(nextWord);// 这一层扩展出的单词进入队列q.push(nextWord);// 记录 nextWord 从 currWord 而来from[nextWord].insert(currWord);// 记录 nextWord 的 stepsteps[nextWord] = step;if (nextWord == endWord) {found = true;}}nextWord[j] = origin;}}if (found) {break;}}// 第 2 步:回溯找到所有解,从 endWord 恢复到 beginWord ,所以每次尝试操作 path 列表的头部if (found) {vector<string> Path = {endWord};backtrack(res, endWord, from, Path);}return res;}void backtrack(vector<vector<string>> &res, const string &Node, unordered_map<string, set<string>> &from,vector<string> &path) {if (from[Node].empty()) {res.push_back({path.rbegin(), path.rend()});return;}for (const string &Parent: from[Node]) {path.push_back(Parent);backtrack(res, Parent, from, path);path.pop_back();}}
};int main() {vector<string> wordList;string s;string beginWord, endWord;while(cin >> s) {wordList.push_back(s);if(cin.get() == '\n')break;}cin >> beginWord >> endWord;Solution solution;vector<vector<string>> result = solution.findLadders(beginWord, endWord, wordList);for (const std::vector<std::string>& path : result) {for (const std::string& word : path) {std::cout << word << " ";}std::cout << std::endl;}return 0;
}127. 单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:5 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:0 解释:endWord "cog" 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
#include<iostream>
#include<vector>
#include<string>
#include<unordered_set>
#include<queue>using namespace std;class Solution {public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {unordered_set<string> dict(wordList.begin(), wordList.end());if(dict.find(endWord) == dict.end()) {return 0;}queue<string> q;q.push(beginWord);int level = 1;while(!q.empty()) {int size = q.size();for(int i = 0; i < size; i++) {string word = q.front();q.pop();if(word == endWord) {return level;}for(int j = 0; j < word.length(); j++) {char originalChar = word[j];for(char c = 'a'; c <= 'z'; c++) {word[j] = c;if(dict.find(word) != dict.end()) {q.push(word);dict.erase(word);}}word[j] = originalChar;}}level++;} return 0;}
};int main() {vector<string> wordList;string s;string beginWord, endWord;while(cin >> s) {wordList.push_back(s);if(cin.get() == '\n')break;}cin >> beginWord >> endWord;Solution solution;cout << solution.ladderLength(beginWord, endWord, wordList);return 0;
}
128. 最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
提示:
0 <= nums.length <= 10^5-10^9 <= nums[i] <= 10^9
#include<iostream>
#include<vector>
#include<unordered_set>
using namespace std;class Solution {public:int longestConsecutive(vector<int>& nums) {unordered_set<int> numSet(nums.begin(), nums.end());int longestStreak = 0;for(int num : numSet) {if(numSet.find(num - 1) == numSet.end()) {// 检查这个数字是否是序列的开头int currentNum = num;int currentStreak = 1;while(numSet.find(currentNum + 1) != numSet.end()) {currentNum++;currentStreak++;} longestStreak = max(longestStreak, currentStreak);}}return longestStreak;}
}; int main() {int tmp;vector<int> nums;while(cin >> tmp) {nums.push_back(tmp);if(cin.get() == '\n')break;}Solution solution;cout << solution.longestConsecutive(nums) << endl;return 0;
}129. 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:

输入:root = [1,2,3] 输出:25 解释: 从根到叶子节点路径 1->2,代表数字 12 从根到叶子节点路径 1->3,代表数字 13 因此,数字总和 = 12 + 13 = 25
示例 2:

输入:root = [4,9,0,5,1] 输出:1026 解释: 从根到叶子节点路径 4->9->5,代表数字 495 从根到叶子节点路径 4->9->1,代表数字 491 从根到叶子节点路径 4->0,代表数字 40 因此,数字总和 = 495 + 491 + 40 = 1026
提示:
- 树中节点的数目在范围
[1, 1000]内 0 <= Node.val <= 9- 树的深度不超过
10
#include<iostream>
#include<vector>
#include<queue>using namespace std;// Definition for a binary tree node
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:int sumNumbers(TreeNode* root) {return dfs(root, 0);}int dfs(TreeNode* node, int currentSum) {if(node == NULL) {return 0;}currentSum = currentSum * 10 + node->val;if(node->left == NULL && node->right == NULL) {return currentSum;}int leftSum = dfs(node->left, currentSum);int rightSum = dfs(node->right, currentSum);return leftSum + rightSum;}
};TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;cout << solution.sumNumbers(root) << endl;return 0;
}130. 被围绕的区域
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例 1:
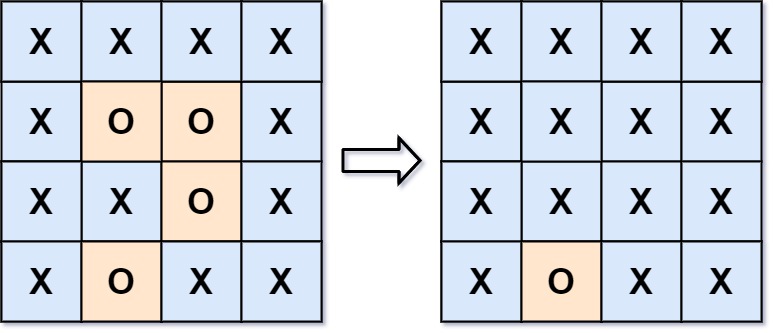
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] 输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] 解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
示例 2:
输入:board = [["X"]] 输出:[["X"]]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j]为'X'或'O'
#include<iostream>
#include<vector>
using namespace std;class Solution {public:void solve(vector<vector<char>>& board) {if(board.empty() || board[0].empty()) {return;}int m = board.size();int n = board[0].size();// mark '0' on the boundaries and connect to boundariesfor(int i = 0; i < m; i++) {markBoundary(board, i, 0);markBoundary(board, i, n - 1);}for(int j = 0; j < n; j++) {markBoundary(board, 0, j);markBoundary(board, m - 1, j);}// convert marked '0's back to '0' and unmarked '0's to 'X'for(int i = 0; i < m; i++) {for(int j = 0; j < n; j++) {if(board[i][j] == '0') {board[i][j] = 'X';} else if(board[i][j] == '#') {board[i][j] = '0';}}}}void markBoundary(vector<vector<char>>& board, int i, int j) {if(i < 0 || i >= board.size() || j < 0 || j >= board[0].size() || board[i][j] != '0') {return;}board[i][j] = '#';markBoundary(board, i - 1, j);markBoundary(board, i + 1, j);markBoundary(board, i, j - 1);markBoundary(board, i, j + 1);}
};int main() {int m, n;cin >> m >> n;vector<vector<char>> board(m, vector<char>(n));for(int i = 0; i < m; i++) {for(int j = 0; j < n; j++) {cin >> board[i][j];}}Solution solution;solution.solve(board);for(int i = 0; i < m; i++) {for(int j = 0; j < n; j++) {cout << board[i][j] << " ";}cout << endl;}return 0;
}131. 分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
示例 1:
输入:s = "aab" 输出:[["a","a","b"],["aa","b"]]
示例 2:
输入:s = "a" 输出:[["a"]]
提示:
1 <= s.length <= 16s仅由小写英文字母组成
#include<iostream>
#include<vector>
#include<string>
using namespace std;class Solution {public:vector<vector<string>> partition(string s) {vector<vector<string>> result;vector<string> current;backtrack(result, current, s, 0);return result;}void backtrack(vector<vector<string>>& result, vector<string>& current, string& s, int start) {if(start == s.length()) {result.push_back(current);return;}for(int i = start; i < s.length(); i++) {if(isPalindrome(s, start, i)) {string substring = s.substr(start, i - start + 1);current.push_back(substring);backtrack(result, current, s, i + 1);current.pop_back();}}}bool isPalindrome(string& s, int start, int end) {while(start < end) {if(s[start] != s[end]) {return false;}start++;end--;}return true;}
};int main() {string s;cin >> s;Solution solution;vector<vector<string>> result = solution.partition(s);cout << "[";for(int i = 0; i < result.size(); i++) {cout << "[";for(int j = 0; j < result[i].size(); j++) {if(j == result[i].size() - 1) {cout << result[i][j];} else {cout << result[i][j] << " ";}}if(i == result.size() - 1) {cout << "]";} else {cout << "], ";}} cout << "]";return 0;
}132. 分割回文串Ⅱ
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文串。
返回符合要求的 最少分割次数 。
示例 1:
输入:s = "aab" 输出:1 解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。
示例 2:
输入:s = "a" 输出:0
示例 3:
输入:s = "ab" 输出:1
提示:
1 <= s.length <= 2000s仅由小写英文字母组成
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int minCut(string s) {int n = s.size();vector<vector<bool>> isPalindrome(n, vector<bool>(n, false));vector<int> dp(n, 0);for(int i = 0; i < n; i++) {int minCut = i;for(int j = 0; j <= i; j++) {if(s[j] == s[i] && (i - j <= 2 || isPalindrome[j + 1][i - 1])) {isPalindrome[j][i] = true;minCut = (j == 0) ? 0 : min(minCut, dp[j - 1] + 1);}}dp[i] = minCut; // 将字符串s的前i+1个字符分割成回文子串的最少次数 }return dp[n - 1];}
};
aint main() {string s;cin >> s;Solution solution;cout << solution.minCut(s) << endl;return 0;
}133. 克隆图
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {public int val;public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:

输入:adjList = [[2,4],[1,3],[2,4],[1,3]] 输出:[[2,4],[1,3],[2,4],[1,3]] 解释: 图中有 4 个节点。 节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:

输入:adjList = [[]] 输出:[[]] 解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = [] 输出:[] 解释:这个图是空的,它不含任何节点。
提示:
- 这张图中的节点数在
[0, 100]之间。 1 <= Node.val <= 100- 每个节点值
Node.val都是唯一的, - 图中没有重复的边,也没有自环。
- 图是连通图,你可以从给定节点访问到所有节点。
#include<iostream>
#include<vector>
#include<unordered_map>
using namespace std;class Node {public:int val;vector<Node*> neighbors;Node() {val = 0;neighbors = vector<Node*>();}Node(int _val) {val = _val;neighbors = vector<Node*>();}Node(int _val, vector<Node*> _neighbors) {val = _val;neighbors = _neighbors;}
};class Solution {public:Node* cloneGraph(Node* node) {if(!node) {return NULL;}// 存储已经访问过的节点及其对应的克隆节点 unordered_map<Node*, Node*> visited;return cloneNode(node, visited);}// 对于每个节点,我们递归的克隆其邻居节点,并将克隆节点添加到当前节点的邻居列表中,最后返回克隆图的起始节点 Node* cloneNode(Node* node, unordered_map<Node*, Node*>& visited) {if(visited.find(node) != visited.end()) {return visited[node];}Node* newNode = new Node(node->val);visited[node] = newNode;for(Node* neighbor : node->neighbors) {newNode->neighbors.push_back(cloneNode(neighbor, visited));}return newNode;}
};int main() {// 从控制台输入测试用例vector<vector<int>> adjList = {{2, 4}, {1, 3}, {2, 4}, {1, 3}};// 创建图vector<Node*> nodes;for (int i = 0; i < adjList.size(); ++i) {nodes.push_back(new Node(i + 1));}for (int i = 0; i < adjList.size(); ++i) {for (int j = 0; j < adjList[i].size(); ++j) {nodes[i]->neighbors.push_back(nodes[adjList[i][j] - 1]);}}// 深度拷贝图Solution solution;Node* clonedNode = solution.cloneGraph(nodes[1]);// 输出克隆图的邻居节点值for (Node* neighbor : clonedNode->neighbors) {cout << neighbor->val << " ";}return 0;
}134. 加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2] 输出: 3 解释: 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 因此,3 可为起始索引。
示例 2:
输入: gas = [2,3,4], cost = [3,4,3] 输出: -1 解释: 你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 因此,无论怎样,你都不可能绕环路行驶一周。
提示:
gas.length == ncost.length == n1 <= n <= 10^50 <= gas[i], cost[i] <= 10^4
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {int total_tank = 0;int curr_tank = 0;int starting_station = 0;for(int i = 0; i < gas.size(); i++) {total_tank += gas[i] - cost[i];curr_tank += gas[i] - cost[i];if(curr_tank < 0) {starting_station = i + 1;curr_tank = 0;}}return total_tank >= 0 ? starting_station : -1; }
};int main() {vector<int> gas, cost;int tmp;while(cin >> tmp) {gas.push_back(tmp);if(cin.get() == '\n') {break;}}while(cin >> tmp) {cost.push_back(tmp);if(cin.get() == '\n') {break;}}Solution solution;cout << solution.canCompleteCircuit(gas, cost);return 0;
}135. 分发糖果
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
- 每个孩子至少分配到
1个糖果。 - 相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:
输入:ratings = [1,0,2] 输出:5 解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:ratings = [1,2,2] 输出:4 解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
提示:
n == ratings.length1 <= n <= 2 * 10^40 <= ratings[i] <= 2 * 10^4
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int candy(vector<int>& ratings) {int n = ratings.size();vector<int> candies(n, 1);for(int i = 1; i < n; i++) {if(ratings[i] > ratings[i - 1]) {candies[i] = candies[i - 1] + 1;}}for(int i = n - 2; i >= 0; i--) {if(ratings[i] > ratings[i + 1]) {candies[i] = max(candies[i], candies[i + 1] + 1);}}int total = 0;for(int candy : candies) {total += candy;}return total;}
};int main() {vector<int> ratings;int tmp;while(cin >> tmp) {ratings.push_back(tmp);if(cin.get() == '\n') {break;}}Solution solution;cout << solution.candy(ratings) << endl;return 0;
}136. 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1] 输出:1
示例 2 :
输入:nums = [4,1,2,1,2] 输出:4
示例 3 :
输入:nums = [1] 输出:1
提示:
1 <= nums.length <= 3 * 10^4-3 * 10^4 <= nums[i] <= 3 * 10^4- 除了某个元素只出现一次以外,其余每个元素均出现两次。
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int singleNumber(vector<int>& nums) {int result = 0;for(int i = 0; i < nums.size(); i++) {result ^= nums[i]; // 相同为0,相异为1 }return result;}
};int main() {int temp;vector<int> nums;while(cin >> temp) {nums.push_back(temp);if(cin.get() == '\n')break;}Solution solution;cout << solution.singleNumber(nums);return 0;
}#include<iostream>
#include<vector>
#include<numeric>
using namespace std;class Solution {public:int singleNumber(vector<int>& nums) {return accumulate(nums.begin(),nums.end(),0,bit_xor<int>());}
};int main() {int temp;vector<int> nums;while(cin >> temp) {nums.push_back(temp);if(cin.get() == '\n')break;}Solution solution;cout << solution.singleNumber(nums);return 0;
}137. 只出现一次的数Ⅱ
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。
示例 1:
输入:nums = [2,2,3,2] 输出:3
示例 2:
输入:nums = [0,1,0,1,0,1,99] 输出:99
提示:
1 <= nums.length <= 3 * 10^4-2^31 <= nums[i] <= 2^31 - 1nums中,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次
#include<iostream>
#include<vector>
using namespace std;class Solution {public:int singleNumber(vector<int>& nums) {int seen_once = 0;int seen_twice = 0;for(int num : nums) {seen_once = ~seen_twice & (seen_once ^ num); // 当前元素num出现的次数为1次 seen_twice = ~seen_once & (seen_twice ^ num); // 当前元素num出现的次数为2次 }return seen_once;}
};int main() {vector<int> nums;int tmp;while(cin >> tmp) {nums.push_back(tmp);if(cin.get() == '\n')break;}Solution solution;cout << solution.singleNumber(nums);return 0;
}138. 随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-10^4 <= Node.val <= 10^4Node.random为null或指向链表中的节点。
#include<iostream>
#include<unordered_map>
using namespace std;// Definition for a node
class Node {public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};class Solution {public:Node* copyRandomList(Node* head) {if(!head) {return NULL;}unordered_map<Node*, Node*> nodeMap;Node* cur = head;// 第一遍循环,复制每个结点的值并创建新结点while(cur) {nodeMap[cur] = new Node(cur->val);cur = cur->next;} cur = head;// 第二遍循环,连接新结点的next和random指针while(cur) {nodeMap[cur]->next = nodeMap[cur->next];nodeMap[cur]->random = nodeMap[cur->random];cur = cur->next;} return nodeMap[head];}
};/*
Node* createList() {Node* head = NULL;Node* current = NULL;int val;while(cin >> val) {Node* newNode = new Node(val);if(head == NULL) {head = newNode;current = newNode;} else {current->next = newNode;current = current->next;}if(cin.get() == '\n') {break;} }return head;
}*/int main() {Node* node1 = new Node(7);Node* node2 = new Node(13);Node* node3 = new Node(11);Node* node4 = new Node(10);Node* node5 = new Node(1);node1->next = node2;node2->next = node3;node3->next = node4;node4->next = node5;node1->random = NULL;node2->random = node1;node3->random = node5;node4->random = node3;node5->random = node1;Solution solution;Node* copiedHead = solution.copyRandomList(node1);return 0;
}139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅由小写英文字母组成wordDict中的所有字符串 互不相同
#include<iostream>
#include<vector>
#include<unordered_set>
using namespace std;class Solution {public:bool wordBreak(string s, vector<string>& wordDict) {unordered_set<string> dict(wordDict.begin(), wordDict.end());int n = s.size();// dp[i]表示s的前i个字符是否可以被拆分成字典中的单词vector<bool> dp(n + 1, false);dp[0] = true;for(int i = 1; i <= n; i++) {for(int j = 0; j < i; j++) {if(dp[j] && dict.count(s.substr(j, i - j))) {dp[i] = true;break;}}}return dp[n];}
};int main() {string s, tmp;vector<string> wordDict;cin >> s;while(cin >> tmp) {wordDict.push_back(tmp);if(cin.get() == '\n') break;}Solution solution;cout << boolalpha << solution.wordBreak(s, wordDict) << endl;return 0;
}140. 单词拆分Ⅱ
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例 1:
输入:s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"] 输出:["cats and dog","cat sand dog"]
示例 2:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"] 输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"] 解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:s = "catsandog", wordDict = ["cats","dog","sand","and","cat"] 输出:[]
提示:
1 <= s.length <= 201 <= wordDict.length <= 10001 <= wordDict[i].length <= 10s和wordDict[i]仅有小写英文字母组成wordDict中所有字符串都 不同
#include<iostream>
#include<vector>
#include<unordered_set>
using namespace std;class Solution {public:vector<string> wordBreak(string s, vector<string>& wordDict) {unordered_set<string> dict(wordDict.begin(), wordDict.end());vector<string> result;backtrack(s, 0, wordDict, dict, "", result);return result;}void backtrack(string s, int start, vector<string>& wordDict, unordered_set<string>& dict, string path, vector<string>& result) {if(start == s.length()) {result.push_back(path);return;}for(int i = start; i < s.length(); i++) {string word = s.substr(start, i - start + 1);if(dict.count(word)) {string newPath = path.empty() ? word : path + " " + word;backtrack(s, i + 1, wordDict, dict, newPath, result);}}}
};int main() {string s, tmp;vector<string> wordDict;cin >> s;while(cin >> tmp) {wordDict.push_back(tmp);if(cin.get() == '\n') break;}Solution solution;vector<string> result = solution.wordBreak(s, wordDict);cout << "[";for(int i = 0; i < result.size(); i++) {if(i == result.size() - 1) {cout << "\"" << result[i] << "\"";} else {cout << "\"" << result[i] << "\", ";}}cout << "]";return 0;
}141. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
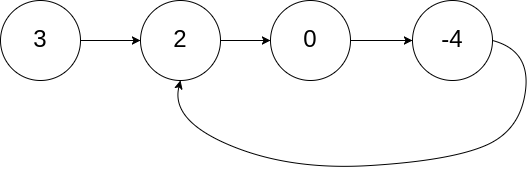
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
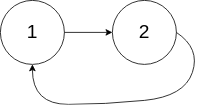
输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 10^4] -10^5 <= Node.val <= 10^5pos为-1或者链表中的一个 有效索引 。
#include<iostream>
#include<cctype>
using namespace std;struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};class Solution {public:bool hasCycle(ListNode *head) { // 快慢指针法ListNode *slow = head;ListNode *fast = head;while(fast != NULL && fast->next != NULL) {slow = slow->next;fast = fast->next->next;if(slow == fast) return true;}return false;}
};ListNode* buildLinkedList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {if(head == NULL) {head = new ListNode(val);current = head;} else{current->next = new ListNode(val);current = current->next;}if(cin.get() == '\n') break;}return head;
}int main() {ListNode* head = buildLinkedList();;Solution solution;cout << boolalpha << solution.hasCycle(head);return 0;
}142. 环形链表Ⅱ
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
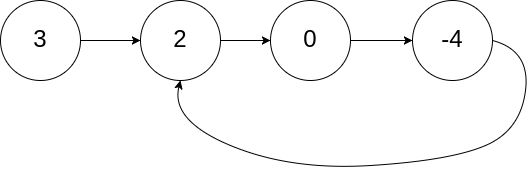
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -10^5 <= Node.val <= 10^5pos的值为-1或者链表中的一个有效索引
进阶:你是否可以使用 O(1) 空间解决此题?
#include<iostream>
#include<cctype>
using namespace std;struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};class Solution {public:ListNode *detectCycle(ListNode *head) {if(head == NULL || head->next == NULL) {return NULL;}ListNode *slow = head;ListNode *fast = head;while(fast != NULL && fast->next != NULL) {slow = slow->next;fast = fast->next->next;if(slow == fast) {ListNode *slow2 = head;while(slow2 != slow) {slow = slow->next;slow2 = slow2->next;}return slow;}}return NULL;}
};ListNode* buildLinkedList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {if(head == NULL) {head = new ListNode(val);current = head;} else{current->next = new ListNode(val);current = current->next;}if(cin.get() == '\n') break;}return head;
}int main() {ListNode* head = buildLinkedList();;Solution solution;ListNode *cycleStart = solution.detectCycle(head);if(cycleStart != NULL) cout << cycleStart->val;elsecout << "null";return 0;
}143. 重排链表
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln - 1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:
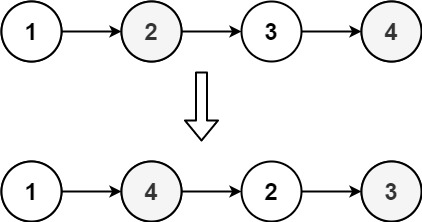
输入:head = [1,2,3,4] 输出:[1,4,2,3]
示例 2:

输入:head = [1,2,3,4,5] 输出:[1,5,2,4,3]
提示:
- 链表的长度范围为
[1, 5 * 10^4] 1 <= node.val <= 1000
#include<iostream>
#include<vector>
using namespace std;// definition for singly-linked list
struct ListNode {int val;ListNode *next;ListNode() : val(0), next(NULL) {}ListNode(int x) : val(x), next(NULL) {}ListNode(int x, ListNode *next) : val(x), next(next) {}
};class Solution {public:void reorderList(ListNode* head) {if(head == NULL || head->next == NULL) return;vector<ListNode*> nodes;ListNode* current = head;while(current != NULL) {nodes.push_back(current);current = current->next;}int left = 0; int right = nodes.size() - 1;while(left < right) {nodes[left]->next = nodes[right];left++;if(left == right) break;nodes[right]->next = nodes[left];right--;}nodes[left]->next = NULL;}
};ListNode* buildLinkedList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {if(head == NULL) {head = new ListNode(val);current = head;} else{current->next = new ListNode(val);current = current->next;}if(cin.get() == '\n') break;}return head;
}int main() {ListNode* head = buildLinkedList();;Solution solution;solution.reorderList(head);ListNode *current = head;while(current != NULL) {cout << current->val << " ";current = current->next;}return 0;
}144. 二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
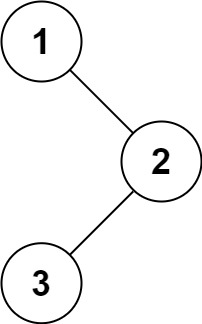
输入:root = [1,null,2,3] 输出:[1,2,3]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:

输入:root = [1,2] 输出:[1,2]
示例 5:

输入:root = [1,null,2] 输出:[1,2]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶:递归算法很简单,你可以通过迭代算法完成吗?
解法一:递归
#include<iostream>
#include<vector>
#include<queue>
using namespace std;//Definition for a binary tree node.
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:vector<int> preorderTraversal(TreeNode* root) {vector<int> result;if(root == NULL)return result;vector<int> left = preorderTraversal(root->left);vector<int> right = preorderTraversal(root->right);result.push_back(root->val);result.insert(result.end(), left.begin(), left.end());result.insert(result.end(), right.begin(), right.end());return result;}
};// Function to create a binary tree from user input
TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;if(rootVal == -1)return NULL;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;vector<int> result = solution.preorderTraversal(root);cout << "[";for(int i = 0; i < result.size() - 1; i++) {cout << result[i] << ", ";}cout << result[result.size() - 1];cout << "]";return 0;
}解法二:迭代
#include<iostream>
#include<vector>
#include<stack>
#include<queue>
using namespace std;// Definition for a binary tree node
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:vector<int> preorderTraversal(TreeNode* root) {vector<int> result;if(root == NULL)return result;stack<TreeNode*> st;st.push(root);while(!st.empty()) {TreeNode* curr = st.top();st.pop();result.push_back(curr->val);if(curr->right != NULL) { // 后进先出 st.push(curr->right);} if(curr->left != NULL) {st.push(curr->left);}}return result;}
};// Function to create a binary tree from user input
TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;if(rootVal == -1)return NULL;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;vector<int> result = solution.preorderTraversal(root);cout << "[";for(int i = 0; i < result.size() - 1; i++) {cout << result[i] << ", ";}cout << result[result.size() - 1];cout << "]";return 0;
}145. 二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
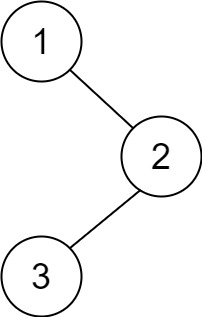
输入:root = [1,null,2,3] 输出:[3,2,1]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点的数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶:递归算法很简单,你可以通过迭代算法完成吗?
解法一:递归
#include<iostream>
#include<vector>
#include<stack>
#include<queue>
using namespace std;// Definition for a binary tree node
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:vector<int> postorderTraversal(TreeNode* root) {vector<int> result;if(root == NULL)return result;vector<int> left = postorderTraversal(root->left);vector<int> right = postorderTraversal(root->right);result.insert(result.end(), left.begin(), left.end());result.insert(result.end(), right.begin(), right.end());result.push_back(root->val);return result;}
};// Function to create a binary tree from user input
TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;if(rootVal == -1)return NULL;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;vector<int> result = solution.postorderTraversal(root);cout << "[";for(int i = 0; i < result.size(); i++) {if(i == result.size() - 1) {cout << result[i];} else{cout << result[i] << ", ";}}cout << "]";return 0;
}解法二:迭代
#include<iostream>
#include<vector>
#include<stack>
#include<queue>
using namespace std;// Definition for a binary tree node
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(NULL), right(NULL) {}TreeNode(int x) : val(x), left(NULL), right(NULL) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {public:vector<int> postorderTraversal(TreeNode* root) {vector<int> result;if(root == NULL)return result;stack<TreeNode*> st;st.push(root);stack<int> output; // 用于存储后序遍历的结果 while(!st.empty()) {TreeNode* curr = st.top();st.pop();output.push(curr->val); // 将节点值存入output栈 if(curr->left != NULL) { st.push(curr->left);} if(curr->right != NULL) {st.push(curr->right);}}// 从output栈中将结果取出,即为后序遍历的倒序结果 while(!output.empty()) {result.push_back(output.top());output.pop();}return result;}
};// Function to create a binary tree from user input
TreeNode* createBinaryTree() {cout << "Enter the value of the root node: ";int rootVal;cin >> rootVal;if(rootVal == -1)return NULL;TreeNode* root = new TreeNode(rootVal);queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* curr = q.front();q.pop();cout << "Enter the left child of '" << curr->val << "' (or -1 if none): ";int leftVal;cin >> leftVal;if (leftVal != -1) {curr->left = new TreeNode(leftVal);q.push(curr->left);}cout << "Enter the right child of '" << curr->val << "' (or -1 if none): ";int rightVal;cin >> rightVal;if (rightVal != -1) {curr->right = new TreeNode(rightVal);q.push(curr->right);}}return root;
}int main() {TreeNode *root = createBinaryTree();Solution solution;vector<int> result = solution.postorderTraversal(root);cout << "[";for(int i = 0; i < result.size(); i++) {if(i == result.size() - 1) {cout << result[i];} else{cout << result[i] << ", ";}}cout << "]";return 0;
}146. LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 10^5- 最多调用
2 * 10^5次get和put
#include<iostream>
#include<unordered_map>
#include<list>
using namespace std;class LRUCache {private:int capacity;unordered_map<int, pair<int, list<int>::iterator>> cache; // key -> (value, iterator)list<int> keys; // 保存所有的key,最近使用的在前面public:LRUCache(int capacity) {this->capacity = capacity;} int get(int key) {if(cache.find(key) == cache.end()) {return -1;}// 将当前访问的key移动到keys的最前面keys.erase(cache[key].second);keys.push_back(key);cache[key].second = keys.begin();return cache[key].first; }void put(int key, int value) {if(cache.find(key) != cache.end()) {// key已存在,更新value并将其移动到keys的最前面keys.erase(cache[key].second); } else {if(cache.size() >= capacity) {// 缓存已满,移除最近最少使用的keyint leastUsedKey = keys.back();keys.pop_back();cache.erase(leastUsedKey); }}keys.push_front(key);cache[key] = {value, keys.begin()};}
};int main() {LRUCache* obj = new LRUCache(2);obj->put(1, 1);obj->put(2, 2);cout << obj->get(1) << endl;obj->put(3, 3);cout << obj->get(2) << endl;obj->put(4, 4);cout << obj->get(1) << endl;cout << obj->get(3) << endl;cout << obj->get(4) << endl;return 0;
}147. 对链表进行插入排序
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
示例 1:

输入: head = [4,2,1,3] 输出: [1,2,3,4]
示例 2:

输入: head = [-1,5,3,4,0] 输出: [-1,0,3,4,5]
提示:
- 列表中的节点数在
[1, 5000]范围内 -5000 <= Node.val <= 5000
#include<iostream>
using namespace std;// definition for singly-linked list
struct ListNode {int val;ListNode *next;ListNode() : val(0), next(NULL) {}ListNode(int x) : val(x), next(NULL) {}ListNode(int x, ListNode* next) : val(x), next(next) {}
};class Solution {public:ListNode* insertionSortList(ListNode* head) {if(!head || !head->next) {return head;}ListNode* dummy = new ListNode(0);dummy->next = head;ListNode* cur = head; // 当前节点ListNode* prev = dummy; // 当前节点的前一个节点while(cur) {if(cur->next && cur->next->val < cur->val) {// 如果下一个节点的值小于当前节点的值,则需要将下一个节点插入到合适的位置while(prev->next && prev->next->val < cur->next->val) {prev = prev->next;} // 将下一个节点插入到合适的位置ListNode* temp = prev->next;prev->next = cur->next;cur->next = cur->next->next;prev->next->next = temp;prev = dummy; // 重置prev为虚拟头节点 } else {// 下一个节点的值不小于当前节点的值,则继续向后遍历 cur = cur->next;} } return dummy->next; }
};ListNode* createList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {ListNode* newNode = new ListNode(val);if(head == NULL) {head = newNode;current = newNode;} else {current->next = newNode;current = current->next;}if(cin.get() == '\n') {break;} }return head;
}int main() {ListNode* head = createList();Solution solution;ListNode* res = solution.insertionSortList(head);while(res) {cout << res->val << " ";res = res->next;}return 0;
}148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3] 输出:[1,2,3,4]
示例 2:

输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]
示例 3:
输入:head = [] 输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 10^4]内 -10^5 <= Node.val <= 10^5
进阶:你可以在 O(nlogn) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
解法一:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;// definition for singly-linked list
struct ListNode {int val;ListNode *next;ListNode() : val(0), next(NULL) {}ListNode(int x) : val(x), next(NULL) {}ListNode(int x, ListNode* next) : val(x), next(next) {}
};class Solution {public:ListNode* sortList(ListNode* head) {// 将链表的值提取到一个vector中,对其进行排序,然后再构建一个新的排好序的链表 if(!head || !head->next) {return head;}vector<int> values;ListNode* current = head;while(current) {values.push_back(current->val);current = current->next;}sort(values.begin(), values.end());ListNode* newHead = new ListNode(values[0]);ListNode* temp = newHead;for(int i = 1; i < values.size(); i++) {temp->next = new ListNode(values[i]);temp = temp->next;}return newHead;}
};ListNode* createList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {ListNode* newNode = new ListNode(val);if(head == NULL) {head = newNode;current = newNode;} else {current->next = newNode;current = current->next;}if(cin.get() == '\n') {break;} }return head;
}int main() {ListNode* head = createList();Solution solution;ListNode* res = solution.sortList(head);while(res) {cout << res->val << " ";res = res->next;}return 0;
}解法二:合并排序
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;// definition for singly-linked list
struct ListNode {int val;ListNode *next;ListNode() : val(0), next(NULL) {}ListNode(int x) : val(x), next(NULL) {}ListNode(int x, ListNode* next) : val(x), next(next) {}
};class Solution {public:ListNode* sortList(ListNode* head) {if(!head || !head->next) {return head;}ListNode *middle = findMiddle(head);ListNode* secondHalf = middle->next;middle->next = NULL;ListNode* sortedFirstHalf = sortList(head);ListNode* sortedSecondHalf = sortList(secondHalf);return merge(sortedFirstHalf, sortedSecondHalf);}ListNode* findMiddle(ListNode* head) {// 快慢指针法 ListNode* slow = head;ListNode* fast = head->next;while(fast && fast->next) {slow = slow->next;fast = fast->next->next;}return slow;}ListNode* merge(ListNode* l1, ListNode* l2) {ListNode dummy(0);ListNode* current = &dummy;while(l1 && l2) {if(l1->val < l2->val) {current->next = l1;l1 = l1->next;} else {current->next = l2;l2 = l2->next;}current = current->next;}// 处理剩下的节点 current->next = l1 ? l1 : l2;return dummy.next;}
};ListNode* createList() {ListNode* head = NULL;ListNode* current = NULL;int val;while(cin >> val) {ListNode* newNode = new ListNode(val);if(head == NULL) {head = newNode;current = newNode;} else {current->next = newNode;current = current->next;}if(cin.get() == '\n') {break;} }return head;
}int main() {ListNode* head = createList();Solution solution;ListNode* res = solution.sortList(head);while(res) {cout << res->val << " ";res = res->next;}return 0;
}149. 直线上最多的点
给你一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
示例 1:

输入:points = [[1,1],[2,2],[3,3]] 输出:3
示例 2:
输入:points = [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] 输出:4
提示:
1 <= points.length <= 300points[i].length == 2-10^4 <= xi, yi <= 10^4points中的所有点 互不相同
#include<iostream>
#include<vector>
#include<unordered_map>
#include<algorithm>
using namespace std;class Solution {public:int maxPoints(vector<vector<int>>& points) {int n = points.size();if(n <= 2) {return n;}int maxPointsOnLine = 2;for(int i = 0; i < n; i++) {unordered_map<string, int> slopeCount;int duplicatePoints = 0;int localMaxPoints = 1;for(int j = i + 1; j < n; j++) {int dx = points[j][0] - points[i][0];int dy = points[j][1] - points[i][1];if(dx == 0 && dy == 0) {// 重复的点duplicatePoints++;continue;}int gcdValue = gcd(dx, dy);// 斜率// (计算斜率时,要考虑斜率的精度问题,因为浮点数计算可能会导致精度误差,为了解决这个问题,我们可以使用最大公约数来表示斜率,以避免精度误差)string slope = to_string(dx / gcdValue) + "_" + to_string(dy / gcdValue);// 斜率相同,即在同一条直线上slopeCount[slope]++;localMaxPoints = max(localMaxPoints, slopeCount[slope] + 1);}maxPointsOnLine = max(maxPointsOnLine, localMaxPoints + duplicatePoints);}return maxPointsOnLine;}int gcd(int a, int b) {return b == 0 ? a : gcd(b, a % b);}
};int main() {vector<vector<int>> points;int x, y;while(cin >> x) {cin >> y;points.push_back({x, y});if(cin.get() == '\n') {break;}}Solution solution;cout << solution.maxPoints(points) << endl;return 0;
}150. 逆波兰表达式求值
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。 - 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 1:
输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入:tokens = ["4","13","5","/","+"] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] 输出:22 解释:该算式转化为常见的中缀算术表达式为:((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
提示:
1 <= tokens.length <= 104tokens[i]是一个算符("+"、"-"、"*"或"/"),或是在范围[-200, 200]内的一个整数
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 )。 - 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * )。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + *也可以依据次序计算出正确结果。 - 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
#include<iostream>
#include<vector>
#include<stack>
#include<string>
using namespace std;class Solution {public:int evalRPN(vector<string>& tokens) {stack<int> st;for(string token : tokens) {if(token == "+" || token == "-" || token == "*" || token == "/") {int num2 = st.top();st.pop();int num1 = st.top();st.pop();if(token == "+") {st.push(num1 + num2);} else if(token == "-") {st.push(num1 - num2);} else if(token == "*") {st.push(num1 * num2);} else if(token == "/") {st.push(num1 / num2);}} else {st.push(stoi(token));}}return st.top();}
}; int main() {vector<string> tokens;string s;while(cin >> s) {tokens.push_back(s);if(cin.get() == '\n') {break;}}Solution solution;cout << solution.evalRPN(tokens) << endl;return 0;
}