前言:
在分布式系统中,数据的分布和负载均衡是至关重要的问题。一致性哈希算法是一种解决这些挑战的有效工具,它在分布式存储、负载均衡和缓存系统等领域得到了广泛应用。
随着互联网规模的不断扩大,传统的哈希算法在面对大规模数据时往往会遇到性能瓶颈和负载不均衡的问题。一致性哈希算法的出现填补了这一空白,它能够将数据分布到不同的节点上,同时保证在节点的增减时最小化数据迁移,从而提高了系统的可扩展性和稳定性。
目录
前言:
传统的Hash算法:
一致性Hash算法:
解决传统的Hash算法的问题:
应用场景:
总结:

无论是传统的Hash算法还是一致性Hash算法,解决的都是分布式缓存下 多节点 之间 的问题
传统的Hash算法:
我们直接用场景举例:当我们有多台缓存中间件来缓存数据的时候(比如Redis集群),当一个数据发送过来的时候,我们要面临一个问题:这个数据应该存到哪台服务器中?
我们用图片说明:
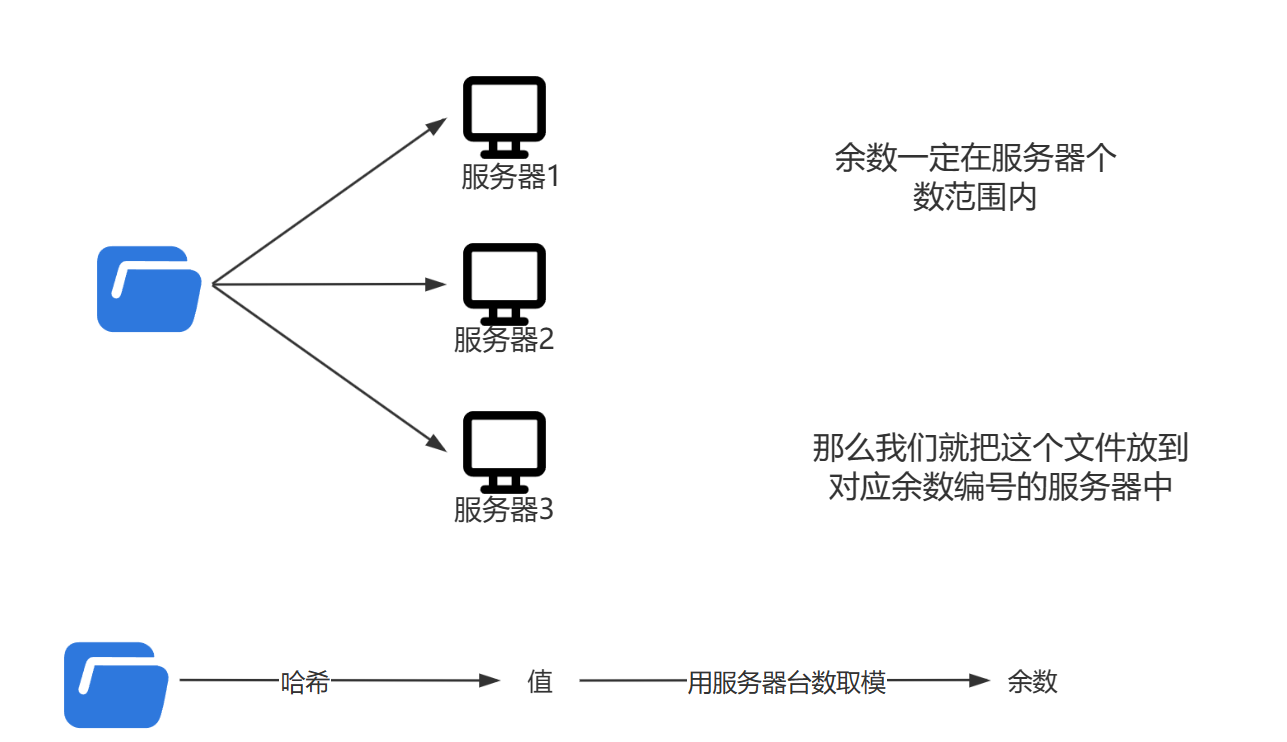
比如现在有一个文件,hash之后得到的值是7463322,然后我们用 服务器台数 取余。
7463323 % 3 = 1
那么我们就把这个文件放到编号为1的服务器中。
因为对同一个文件做相同的hash时,得到的hash值时不变的,所以当需要访问图片的时候,我们可以再次Hash,找到目标服务器读取文件。
这种算法就是Hash算法,但是这种Hash算法有两个明显的缺点:
1.Hash算法散列度不够,导致单个服务器堆积多个文案

2. 变化服务器台数之后,原文件可能无法在正确的服务器中获得文件。

这样就导致缓存系统无法起到替代数据库分担一部分访问压力的作用,可能会导致大量的请求直接打到数据库,导致数据库崩溃。
通过简单的介绍,我们看到了传统的Hash算法的弊端,那么在不断的改进之下:一致性Hash算法 横空出世。
一致性Hash算法:
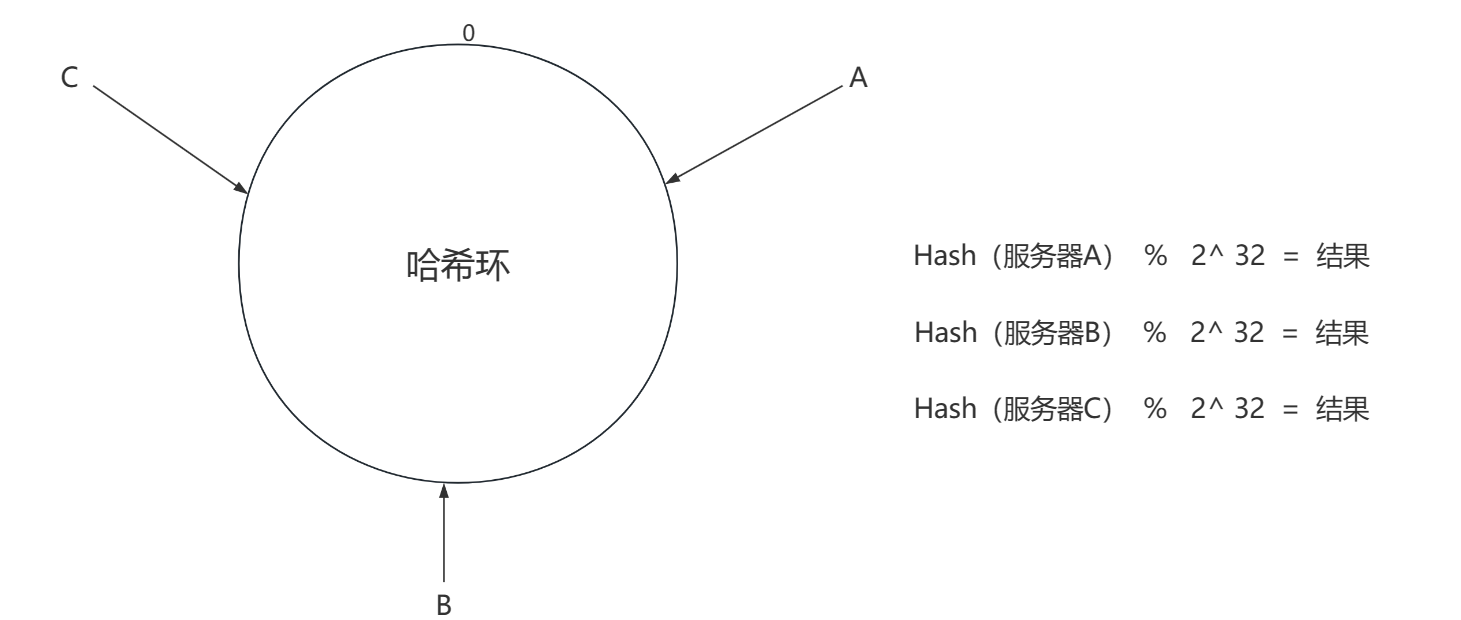
我们可以构想现在有一个 2^32个点所组成的圆环,我们把它叫做Hash环

圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1,我们把这个由 2^32 个点组成的圆环称为hash环。
假设我们现在有三台缓存服务器 服务器A, 服务器B , 服务器C 。现在我们可以将这三台服务器编号Hash值 与 2 ^ 32 次方进行取余。得到的结果可以 映射 在 我们设计的这个Hash环 上
当我们在选择把文件存储到哪一个缓存服务器中的时候,采用以下算法:

1.对文件Hash值用 2 ^ 32 次方进行取余。得到的结果也能在当前Hash环中有一个映射点。
2.我们选择从顺时针触发, 把文件存储在 距离当前结果映射点 最近的服务器。
比如 当前文件结果映射点距离 B 缓存服务器最近,那么我们就把文件存储在B服务器上。
解决传统的Hash算法的问题:
1.传统Hash算法在添加服务器后,缓存失效的场景
假设我们的A 和 B 缓存服务器中,新增了一个 缓存服务器D:
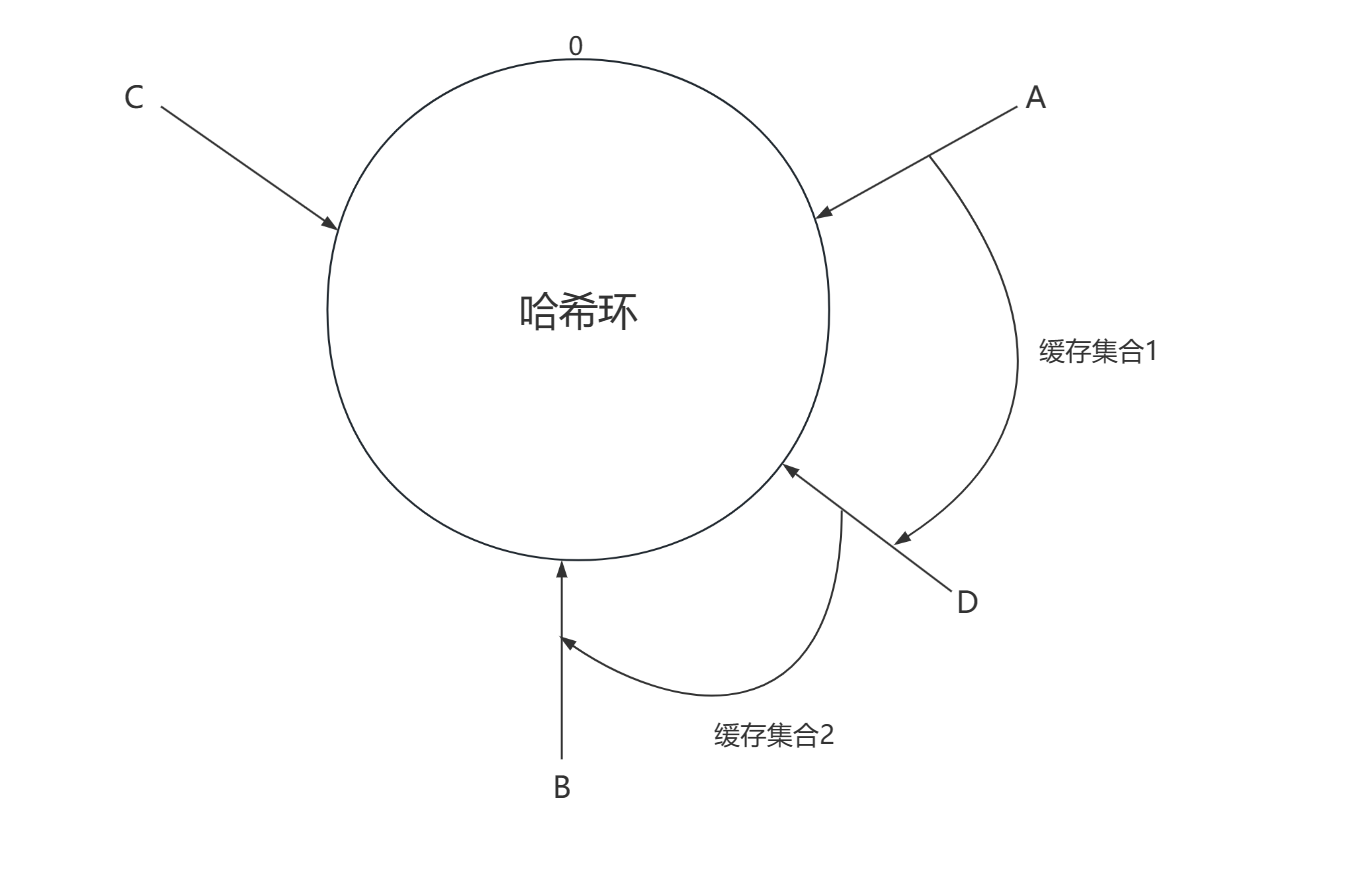
之前我们A-B这段这段范围的所有缓存映射点的缓存,本来都是存储在缓存B服务器的 ,但是由于新增的缓存服务器D 插进了A和B之间,导致缓存集合1 会 映射到 缓存服务器D中,但是我们的缓存集合2仍然是可用,它依然会被映射到缓存服务器B中。
这样可以减少新增服务器所带来的缓存失效波及范围。通过Hash环的设计,我们在新增缓存服务器的时候,仍然保存了部分可用文件。
也就是说:使用Hash环之后,当我们新增服务器的时候,不会导致所有的缓存失效,而是部分缓存失效
而原生的Hash环并不能够解决大量资源堆积在同一个缓存服务器的场景,这是因为在实际缓存服务器映射的时候,并不一定会像我们理想化的三分Hash环。
我们把这种缺陷叫做Hash偏斜。

当出现Hash偏斜的时候,大量的文件仍然会存储在服务器A中。而一致性Hash算法给出的解决方案是:虚拟节点。
虽然物理节点只有三台,但是我们可以映射出很多虚拟节点,当前待存储的文件距离哪一个虚拟节点最近,就把数据存储到哪一个虚拟节点对应的物理节点中。
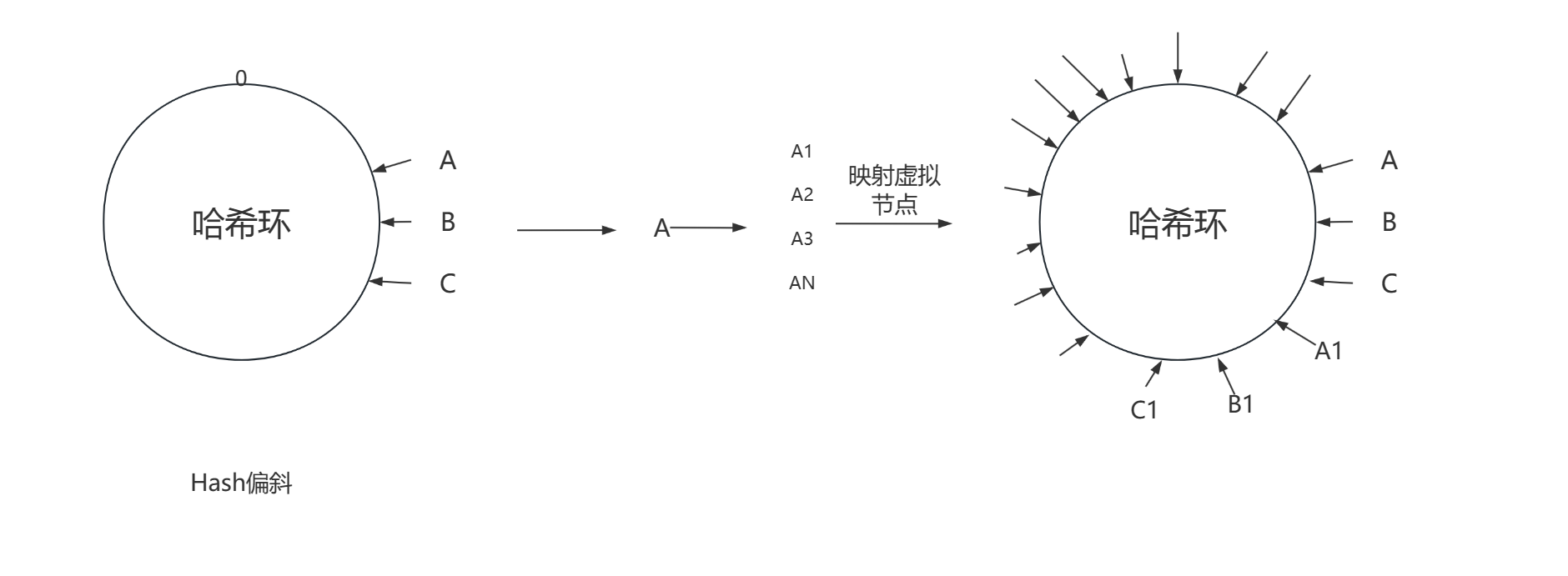
其实Hash偏斜的解决方案可以简单总结为:创建虚拟节点 尝试均分 Hash环,虚拟节点越多,我们的映射就越均匀。
应用场景:
-
分布式缓存: 一致性哈希算法常用于分布式缓存系统中,例如在Memcached和Redis等分布式缓存系统中。通过一致性哈希,可以将缓存数据均匀地分布到不同的缓存节点上,提高缓存系统的扩展性和容错性。
-
分布式数据库: 大规模分布式数据库系统也会使用一致性哈希算法来实现数据分片和负载均衡。例如,Cassandra、MongoDB等数据库系统都利用一致性哈希来实现数据的分布存储和查询路由。
-
分布式消息队列: 一致性哈希算法可以用于分布式消息队列系统,确保消息能够被均匀地发送到不同的消息队列节点,提高系统的吞吐量和可用性。比如Kafka等消息队列系统可以使用一致性哈希来确定消息的存储位置和消费者组的分布。
-
分布式文件系统: 在分布式文件系统中,一致性哈希算法可以用于确定文件块的存储位置和访问路由,例如Hadoop的HDFS(Hadoop Distributed File System)和GlusterFS等。
-
负载均衡: 一致性哈希算法也可以用于负载均衡,将请求分布到多个服务器上,保证系统的稳定性和性能。
-
分布式计算: 在分布式计算中,一致性哈希算法可以用于任务调度和数据分片,例如MapReduce任务的分布式计算框架。
总的来说,一致性哈希算法在分布式系统中的应用非常广泛,能够有效地解决数据分布、负载均衡和容错性等问题,提高系统的可扩展性和可靠性。
总结:
总的来说,一致性哈希算法是一种用于分布式系统中的数据分布和负载均衡的重要技术。通过将数据映射到一个固定范围的哈希空间,并将节点映射到同样的空间,一致性哈希算法能够保证在节点的增减或者网络分区等情况下,最小化数据迁移并保持系统的平衡性。该算法已经在多个领域得到实际应用,包括分布式缓存、分布式数据库、分布式消息队列、分布式文件系统、负载均衡以及分布式计算等方面。通过了解一致性哈希算法,我们可以更好地设计和构建高可用、高性能的分布式系统。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!