动手学机器学习15 实战kaggle比赛
- 1. 实战kaggle比赛:预测房价
- 代码
- 结果
- 2. 课程竞赛:加州2020年房价预测
- 3. QA
- 4. 用到的代码
- 1. hashlib.sha1()
- 2. sha1.update(data)
- 3. train_data.iloc
- 4. fillna(0)
- 5. pd.get_dummies()
- 6. nn.MSELoss()
- 7. torch.clamp() torch.sqrt()
- 8. 模型训练的代码逻辑
- 9. assert用法
- 10. 类型转换报错
- 11. 判断训练数据特征值是否是字符串类型
- 12. 训练数据特征值做标准化
- 13. 报错 rnumpy.core._exceptions._ArrayMemoryError: Unable to allocate 76.4 GiB for an array with shape (216160, 47439) and data type object
- 14. 根据列名选取数据
1. 实战kaggle比赛:预测房价
代码
import hashlib
import os
import tarfile
import zipfile
import requestsDATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('./', 'data')):"""下载一个DATA_HUB中的文件,返回本地文件名"""assert name in DATA_HUB, f"{name} 不存在于{DATA_HUB}"url, sha1_hash = DATA_HUB[name]os.makedirs(cache_dir, exist_ok=True)fname = os.path.join(cache_dir, url.split('/')[-1])if os.path.exists(fname):sha1 = hashlib.sha1()with open(fname, 'rb')as f:while True:data = f.read(1048576)if not data:breaksha1.update(data)if sha1.hexdigest() == sha1_hash:return fname # 命中缓存print(f'正在从{url}下载{fname}...')r = requests.get(url, stream=True, verify=True)with open(fname, 'wb')as f:f.write(r.content)return fnamedef download_extract(name, folder=None):"""下载并解压zip/tar文件"""fname = download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp.extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef download_all():"""下载DATA_HUB中的所有文件"""for name in DATA_HUB:download(name)# pip install pandas%matplotlib inline
import pandas as pd
import numpy as np
import torch
from torch import nn
from d2l import torch as d2lDATA_HUB['kaggle_house_train'] = (DATA_URL + 'kaggle_house_pred_train.csv', 'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
DATA_HUB['kaggle_house_test'] = (DATA_URL + 'kaggle_house_pred_test.csv', 'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
# 训练数据集包括1460个样本,每个样本80个特征和1个标签, 而测试数据集包含1459个样本,每个样本80个特征
print(train_data.shape) # (1460, 81)
print(test_data.shape) # (1459, 80)
# 索引器 基于整数位置(integer location)选择数据。它通常用于按照行和列的整数位置进行数据选择和切片操作。
# .iloc[行, 列] 看前四个和最后两个特征,以及相应标签(房价)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) # ID是pandas默认添加的序列号
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
print(all_features.shape) # (2919, 79)
# all_features = pd.concat((train_data.iloc[:, :-1], test_data.iloc[:, 1:]))# 4.10.4. 数据预处理
# # 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
# all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
print(all_features.shape) # (2919, 79)
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
print(all_features.shape) # (2919, 330) 1460+1459=2919 # 为什么老师的版本是(2919, 331)
print(all_features.iloc[-4:, -6:])n_train = train_data.shape[0]
print(n_train)
# 通过values属性,我们可以 从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练
# print(all_features[:n_train].values, type(all_features[:n_train].values,))
train_np = np.array(all_features[:n_train].values, dtype=np.float32)
train_features = torch.tensor(train_np, dtype=torch.float32)
test_np = np.array(all_features[n_train:].values, dtype=np.float32)
test_features = torch.tensor(test_np, dtype=torch.float32)
# TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)# 4.10.5 训练
loss = nn.MSELoss() # 计算均方误差
in_features = train_features.shape[1] # 输入特征维度
print("n_train, in_features", n_train, in_features)
def get_net():net = nn.Sequential(nn.Linear(in_features,1))return netdef log_rmse(net, features, labels):# 为了在取对数时进一步稳定该值,将小于1的值设置为1clipped_preds = torch.clamp(net(features), 1, float('inf'))rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))return rmse.item()def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size):train_ls, test_ls = [], []train_iter = d2l.load_array((train_features, train_labels), batch_size)# 这里使用的是Adam优化算法optimizer = torch.optim.Adam(net.parameters(),lr = learning_rate,weight_decay = weight_decay)for epoch in range(num_epochs):for X, y in train_iter:optimizer.zero_grad()l = loss(net(X), y)l.backward()optimizer.step()train_ls.append(log_rmse(net, train_features, train_labels))if test_labels is not None:test_ls.append(log_rmse(net, test_features, test_labels))return train_ls, test_ls# 4.10.6. K折交叉验证
def get_k_fold_data(k, i, X, y):"""k:表示将数据分成的折数,通常是一个大于1的整数。i:表示当前是第几折,取值范围是 0 到 k-1。X:表示输入特征数据,是一个形状为 (样本数, 特征数) 的张量或数组。y:表示对应的标签数据,是一个形状为 (样本数,) 的张量或数组。这个函数实现了将数据集分成 K 折,每次返回一组训练集和验证集的功能,用于进行 K 折交叉验证的训练和评估。"""# 这是一个断言语句,用于确保 k 的取值大于1,否则会触发 AssertionError 异常。assert k > 1# 计算每折的大小:根据样本数和折数 k,计算每折的大小,即每个验证集的样本数fold_size = X.shape[0] // kX_train, y_train = None, None# 分割数据:使用循环遍历每个折,根据当前折的索引 j 计算出当前折的索引范围,# 然后从输入的特征数据 X 和标签数据 y 中切片得到当前折的训练数据和验证数据for j in range(k):idx = slice(j * fold_size, (j + 1) * fold_size)X_part, y_part = X[idx, :], y[idx]if j == i:X_valid, y_valid = X_part, y_partelif X_train is None:X_train, y_train = X_part, y_partelse:X_train = torch.cat([X_train, X_part], 0)y_train = torch.cat([y_train, y_part], 0)# 返回数据:根据当前折的索引 i,将当前折的数据作为验证集(X_valid 和 y_valid),# 其余折的数据拼接起来作为训练集(X_train 和 y_train),最终返回训练集和验证集的特征数据和标签数据。return X_train, y_train, X_valid, y_validdef k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k):data = get_k_fold_data(k, i, X_train, y_train)net = get_net()train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size)train_l_sum += train_ls[-1]valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls], xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs], legend=['train', 'valid'], yscale='log')print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}', f'验证log rmse{float(valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / kk, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}', f'平均验证log rmse: {float(valid_l):f}')
结果
正在从http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv下载./data/kaggle_house_pred_train.csv...
(1460, 81)
(1459, 80)Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
(2919, 79)
(2919, 79)
(2919, 330)SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family \
1455 False False False
1456 False False False
1457 False False False
1458 False False False SaleCondition_Normal SaleCondition_Partial SaleCondition_nan
1455 False False False
1456 False False False
1457 True False False
1458 True False False
1460
n_train, in_features 1460 330
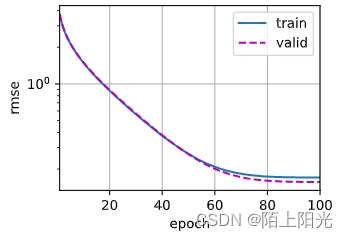
折1,训练log rmse0.170097 验证log rmse0.156521
5-折验证: 平均训练log rmse: 0.165441 平均验证log rmse: 0.171102
2. 课程竞赛:加州2020年房价预测
文本数据处理没整好 暂时先不写。
kaggle网址: https://www.kaggle.com/c/california-house-prices/data?select=train.csv
3. QA

30: 没什么用。
31: 都可以,后续会讲。特征维度多一点少一点没关系。
32:clip_preds没什么用
33:前面章节回顾
34:网络也是超参数,也是需要调的。可以挑取少量数据调。
4. 用到的代码
1. hashlib.sha1()
hashlib.sha1() 是 Python 中 hashlib 模块提供的一个哈希算法函数,用于计算数据的 SHA-1 哈希值。SHA-1(Secure Hash Algorithm 1)是一种常用的密码学哈希函数,通常用于生成数据的哈希值,用于验证数据的完整性或加密密码等安全应用。
这个函数通常的用法是将要计算哈希值的数据作为参数传递给 hashlib.sha1(),然后调用其 hexdigest() 方法获取十六进制形式的哈希值。以下是一个简单的示例:
import hashlib# 要计算哈希值的数据
data = b'Hello, world!'# 创建 SHA-1 哈希对象
sha1_hash = hashlib.sha1()# 更新哈希对象的内容
sha1_hash.update(data)# 获取十六进制形式的哈希值
hash_value = sha1_hash.hexdigest()print("SHA-1 哈希值:", hash_value)
在这个示例中,我们首先导入 hashlib 模块,然后创建一个 SHA-1 哈希对象 sha1_hash,并使用 update() 方法更新哈希对象的内容为要计算哈希值的数据 data。最后,使用 hexdigest() 方法获取计算得到的 SHA-1 哈希值的十六进制表示形式。
需要注意的是,哈希函数通常用于验证数据的完整性或进行简单的加密,并不适用于安全敏感的密码存储或加密场景,因为 SHA-1 已经被证明存在安全性问题,建议在安全敏感场景下使用更安全的哈希算法,如 SHA-256、SHA-512 等。
2. sha1.update(data)
sha1.update(data) 是 hashlib.sha1() 对象的方法,用于将数据 data 更新到 SHA-1 哈希对象中,以便后续计算哈希值。这个方法的作用是将要计算哈希值的数据添加到 SHA-1 哈希对象中,可以多次调用该方法来更新数据。
下面是一个简单的示例,演示了如何使用 sha1.update() 方法计算数据的 SHA-1 哈希值:
import hashlib# 要计算哈希值的数据
data1 = b'Hello, '
data2 = b'world!'# 创建 SHA-1 哈希对象
sha1_hash = hashlib.sha1()# 分别更新哈希对象的内容
sha1_hash.update(data1)
sha1_hash.update(data2)# 获取十六进制形式的哈希值
hash_value = sha1_hash.hexdigest()print("SHA-1 哈希值:", hash_value)
在这个示例中,我们首先导入 hashlib 模块,然后创建一个 SHA-1 哈希对象 sha1_hash。接着,我们分别使用 update() 方法将数据 data1 和 data2 更新到哈希对象中,然后使用 hexdigest() 方法获取计算得到的 SHA-1 哈希值的十六进制表示形式。
需要注意的是,update() 方法可以多次调用,每次调用都会将新的数据添加到哈希对象中,最终计算的哈希值是基于所有添加的数据计算得到的。
3. train_data.iloc
train_data.iloc 是 Pandas DataFrame 对象的一个属性,用于基于整数位置(integer location)选择数据。它通常用于按照行和列的整数位置进行数据选择和切片操作。
具体来说,iloc 是 DataFrame 的索引器(indexer),用于通过整数位置来选择数据。它的一般用法是 DataFrame.iloc[row_indices, column_indices],其中 row_indices 和 column_indices 是用于选择行和列的整数位置或整数切片。
以下是一些示例用法:
-
选择单个元素:
element = train_data.iloc[0, 1] # 选择第一行、第二列的元素 -
选择多个元素:
elements = train_data.iloc[[0, 1], [1, 2]] # 选择第一行和第二行,第二列和第三列的元素 -
切片选择数据:
sliced_data = train_data.iloc[1:5, 2:4] # 选择第2行到第5行,第3列到第4列的数据
iloc 的参数可以是单个整数位置、整数位置列表、整数切片,可以用于选择单个元素、多个元素或切片数据,非常灵活和方便。值得注意的是,iloc 是基于整数位置进行选择的,与 .loc 属性不同,后者是基于标签进行选择的。
4. fillna(0)
fillna(0) 是 Pandas DataFrame 或 Series 对象的一个方法,用于将缺失值(NaN)替换为指定的值(这里是 0)。具体来说,fillna(0) 将 DataFrame 或 Series 中的所有缺失值用指定的值(0)进行填充。
示例用法如下:
- 对于 DataFrame:
import pandas as pd# 创建一个包含缺失值的 DataFrame df = pd.DataFrame({'A': [1, 2, None], 'B': [None, 4, 5]}) print("原始 DataFrame:") print(df)# 使用 fillna(0) 将缺失值填充为 0 df_filled = df.fillna(0) print("填充后的 DataFrame:") print(df_filled)
输出结果:
原始 DataFrame:A B
0 1.0 NaN
1 2.0 4.0
2 NaN 5.0填充后的 DataFrame:A B
0 1.0 0.0
1 2.0 4.0
2 0.0 5.0
- 对于 Series:
import pandas as pd# 创建一个包含缺失值的 Series series = pd.Series([1, None, 3, None, 5]) print("原始 Series:") print(series)# 使用 fillna(0) 将缺失值填充为 0 series_filled = series.fillna(0) print("填充后的 Series:") print(series_filled)
输出结果:
原始 Series:
0 1.0
1 NaN
2 3.0
3 NaN
4 5.0
dtype: float64填充后的 Series:
0 1.0
1 0.0
2 3.0
3 0.0
4 5.0
dtype: float64
在这个示例中,我们首先创建了一个包含缺失值的 DataFrame 或 Series,然后使用 fillna(0) 方法将缺失值替换为指定的值(0)。填充后的结果会生成一个新的对象,原始对象不会被修改。
5. pd.get_dummies()
pd.get_dummies() 是 Pandas 库中的一个函数,用于将分类变量(categorical variable)转换为哑变量(dummy variables)或独热编码(one-hot encoding)。这在机器学习和数据预处理中很常见,特别是在处理分类数据时。
具体来说,pd.get_dummies() 接受一个 Series 或 DataFrame,并将其中的分类变量(通常是字符串类型或分类类型)转换为哑变量或独热编码。对于每个分类变量,它会创建一个新的二进制列,其中包含了该变量可能的取值,每个取值对应一个新的二进制列,取值出现的位置上为1,其他位置为0。
以下是一个简单的示例:
import pandas as pd# 创建一个包含分类变量的 DataFrame
df = pd.DataFrame({'A': ['cat', 'dog', 'cat', 'bird', 'dog']})# 使用 get_dummies() 将分类变量转换为哑变量
df_dummies = pd.get_dummies(df['A'])print("原始 DataFrame:")
print(df)print("\n转换后的 DataFrame:")
print(df_dummies)
输出结果:
原始 DataFrame:A
0 cat
1 dog
2 cat
3 bird
4 dog转换后的 DataFrame:bird cat dog
0 0 1 0
1 0 0 1
2 0 1 0
3 1 0 0
4 0 0 1
在这个示例中,我们首先创建了一个包含分类变量的 DataFrame,并使用 pd.get_dummies() 将分类变量 ‘A’ 转换为哑变量。转换后的结果生成了一个新的 DataFrame df_dummies,其中的每个分类值都被转换为对应的二进制列。
pd.get_dummies(all_features, dummy_na=True) 中的 dummy_na=True 是指在转换分类变量为哑变量时,是否包含对缺失值的处理。
具体来说,当设置 dummy_na=True 时,pd.get_dummies() 会额外创建一个用于表示缺失值的哑变量列(dummy variable column)。这个哑变量列的取值为1表示原始数据中的值为缺失值(NaN),其他列的取值为0表示对应的值不是缺失值。
举个例子:
import pandas as pd# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({'A': ['cat', 'dog', None, 'bird', 'dog']})# 使用 get_dummies() 将分类变量转换为哑变量,并包含对缺失值的处理
df_dummies = pd.get_dummies(df['A'], dummy_na=True)print("原始 DataFrame:")
print(df)print("\n转换后的 DataFrame:")
print(df_dummies)
输出结果:
原始 DataFrame:A
0 cat
1 dog
2 None
3 bird
4 dog转换后的 DataFrame:bird cat dog NaN
0 0 1 0 0
1 0 0 1 0
2 0 0 0 1
3 1 0 0 0
4 0 0 1 0
在这个示例中,我们首先创建了一个包含缺失值的 DataFrame,并使用 pd.get_dummies() 将分类变量 ‘A’ 转换为哑变量,并设置 dummy_na=True。转换后的结果生成了一个新的 DataFrame df_dummies,其中的每个分类值都被转换为对应的二进制列,同时还包含了一个用于表示缺失值的哑变量列(‘NaN’ 列)。
6. nn.MSELoss()
nn.MSELoss() 是 PyTorch 中的一个损失函数,用于计算均方误差(Mean Squared Error,MSE)。均方误差是回归问题中常用的损失函数之一,用于衡量模型预测值与真实值之间的差异。
在 PyTorch 中,nn.MSELoss() 是一个类,通常与神经网络模型一起使用。它计算的是预测值与真实值之间每个元素差的平方的均值,公式如下:
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
其中, y i y_i yi 是真实值, y ^ i \hat{y}_i y^i 是模型预测值, n n n 是样本数量。
使用 nn.MSELoss() 的一般步骤如下:
-
定义模型:首先需要定义一个神经网络模型,并定义模型的输入和输出。
-
定义损失函数:使用
nn.MSELoss()创建一个均方误差损失函数对象。 -
计算损失:将模型的预测值和真实值作为参数传递给损失函数对象,调用该对象的方法计算均方误差损失。
示例代码如下所示:
import torch
import torch.nn as nn# 创建模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc = nn.Linear(10, 1) # 输入特征大小为10,输出大小为1def forward(self, x):x = self.fc(x)return x# 定义输入数据和真实标签
inputs = torch.randn(1, 10) # 输入数据,大小为1x10
targets = torch.randn(1) # 真实标签,大小为1# 创建模型和损失函数对象
model = Net()
criterion = nn.MSELoss()# 前向传播
outputs = model(inputs)# 计算损失
loss = criterion(outputs, targets)print("MSE损失:", loss.item())
在这个示例中,我们首先定义了一个简单的神经网络模型 Net,然后使用 nn.MSELoss() 创建了一个均方误差损失函数对象 criterion。接着,我们生成了模型的预测值 outputs,并将预测值和真实标签传递给损失函数对象 criterion,调用其方法计算均方误差损失。最后打印出计算得到的均方误差损失值。
7. torch.clamp() torch.sqrt()
这两个命令分别是 torch.clamp() 和 torch.sqrt() 函数的使用。
-
torch.clamp(net(features), 1, float('inf')):torch.clamp()函数用于将张量中的元素限制在指定范围内。它的语法是torch.clamp(input, min, max),其中input是输入张量,min和max分别是元素的下限和上限。- 在这个命令中,
net(features)表示使用神经网络net对特征features进行预测,然后将预测结果张量中的元素限制在 1 到正无穷大之间,即大于等于1的值保持不变,小于1的值被设为1。 - 这种操作通常用于处理预测结果中可能出现的非法或不合理的值,比如负数或极小的正数值。
-
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels))):torch.sqrt()函数用于计算张量元素的平方根。它的语法是torch.sqrt(input),其中input是输入张量。- 在这个命令中,
torch.log(clipped_preds)和torch.log(labels)分别是对预测结果和真实标签取对数。然后,这两个对数张量被传递给损失函数loss,并计算得到的结果取平方根,即得到了均方根误差(Root Mean Squared Error,RMSE)。 - RMSE 是用来衡量模型预测值与真实值之间的差异的常用指标,它对于损失函数中的值取对数是为了处理可能存在的数据范围较大或变化幅度较大的情况。
综合起来,这两个命令一起使用的目的是对神经网络模型的预测结果进行处理(限制在合理范围内),然后计算预测结果与真实标签之间的均方根误差。
8. 模型训练的代码逻辑
这几行代码是一个简单的训练循环,用于训练神经网络模型。下面我来解释这几行代码的执行逻辑:
-
for epoch in range(num_epochs)::这是外部循环,用于控制训练的轮数,num_epochs表示训练的总轮数。 -
for X, y in train_iter::这是内部循环,用于遍历训练数据集。train_iter是一个迭代器(iterator),每次迭代返回一个批次的训练样本和对应的标签。X是特征数据,y是标签数据。 -
optimizer.zero_grad():这一行代码用于清除优化器中之前的梯度信息,因为在 PyTorch 中,梯度是累积的。每次更新模型参数之前,需要先清除之前的梯度信息,避免对新的梯度信息造成影响。 -
l = loss(net(X), y):这一行代码用于计算模型对当前批次数据的预测结果并计算损失。net(X)表示将特征数据X输入到神经网络模型中进行前向传播,得到模型的预测结果。然后,将预测结果和真实标签y一起传递给损失函数loss,计算得到当前批次数据的损失值l。 -
l.backward():这一行代码用于反向传播计算梯度。通过调用l.backward()方法,PyTorch 会自动计算损失函数关于模型参数的梯度,并将梯度信息保存在各个参数的.grad属性中。 -
optimizer.step():这一行代码用于更新模型参数。调用optimizer.step()方法会根据优化器的设置,使用梯度信息来更新模型的参数,从而使模型在当前批次数据上的损失尽量减小。
整体来说,这几行代码的执行逻辑是:在每个训练轮次中,遍历训练数据集的每个批次数据,对模型进行前向传播计算损失,然后进行反向传播计算梯度,并使用优化器更新模型参数,以使模型逐渐收敛到最优解。
9. assert用法
assert 是 Python 中的一个关键字,用于断言条件是否为真。它通常用于在开发过程中进行调试和测试,可以帮助检查代码中的假设是否成立。assert 的语法如下:
assert expression, message
其中,expression 是一个条件表达式,如果表达式为假(False),则会触发 AssertionError 异常;message 是可选的,用于在触发异常时输出自定义的错误消息。
例如,我们可以使用 assert 来检查变量是否符合预期的条件,如果条件不满足,则触发 AssertionError 异常。示例代码如下:
def divide(a, b):assert b != 0, "除数不能为0"return a / b# 调用 divide 函数进行除法运算
result = divide(10, 2)
print("结果:", result)# 尝试除以0,触发 AssertionError 异常
try:divide(10, 0)
except AssertionError as e:print("错误信息:", e)
输出结果:
结果: 5.0
错误信息: 除数不能为0
在这个示例中,我们定义了一个 divide 函数,用于进行除法运算。在函数中,我们使用 assert 来检查除数是否为0,如果除数为0,则触发 AssertionError 异常,并输出自定义的错误消息。这样可以帮助我们在开发过程中及时发现并修复代码中的问题。
10. 类型转换报错
train_features = torch.tensor(data_np, dtype=torch.float32)
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
# 要先有一个变量接收pandas转成numpy的数据类型, numpy数据类型有torh不接受的,就先转成float32
train_np = np.array(all_features[:n_train].values, dtype=np.float32)
train_features = torch.tensor(train_np, dtype=torch.float32)
test_np = np.array(all_features[n_train:].values, dtype=np.float32)
test_features = torch.tensor(test_np, dtype=torch.float32)
这个错误表明你的 NumPy 数组中包含了无法被 Torch 接受的数据类型,通常是由于数组中包含了字符串、对象或混合类型的数据。为了解决这个问题,你需要确保将 NumPy 数组转换为 Torch Tensor 时,数组中的数据类型是 Torch 支持的数据类型之一。支持的数据类型包括 float64、float32、float16、complex64、complex128、int64、int32、int16、int8、uint8 和 bool。
首先,你可以检查一下你的 NumPy 数组的数据类型,使用 dtype 属性查看数组的数据类型。然后,根据数据类型的情况,可以采取以下几种解决方法之一:
-
**检查数据类型:**确保 NumPy 数组中的数据类型是 Torch 支持的数据类型之一。如果发现数组中包含了不支持的数据类型(如字符串或对象类型),需要将其转换为 Torch 支持的数据类型。
-
**转换数据类型:**可以使用 NumPy 的
.astype()方法将数组转换为 Torch 支持的数据类型。例如,将 float64 转换为 float32。 -
**处理特殊数据:**如果数组中包含了特殊的数据类型或对象,需要根据具体情况进行处理。例如,将对象转换为字符串或数字形式,然后再进行转换和处理。
下面是一个示例,演示了如何将 NumPy 数组中的数据类型转换为 Torch 支持的数据类型:
import numpy as np
import torch# 示例数据,包含不支持的数据类型
data_np = np.array(['hello', 1, 2.5])# 尝试转换数据类型
try:data_tensor = torch.tensor(data_np, dtype=torch.float32)
except TypeError as e:print("转换错误:", e)# 将数据类型转换为支持的类型
data_np_fixed = np.array([1, 2, 3], dtype=np.float32)
data_tensor_fixed = torch.tensor(data_np_fixed, dtype=torch.float32)print("转换后的 Torch 张量:", data_tensor_fixed)
在这个示例中,我们首先创建了一个包含不支持的数据类型的 NumPy 数组 data_np,然后尝试将其转换为 Torch 张量,由于包含了不支持的数据类型,会触发 TypeError。接着,我们创建了一个符合要求的 NumPy 数组 data_np_fixed,并将其成功转换为 Torch 张量 data_tensor_fixed,以演示正确的转换方法。
11. 判断训练数据特征值是否是字符串类型
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
这条命令是针对 Pandas 数据框(DataFrame)的操作,用于获取所有数值型特征的列索引。
让我们逐步解释这条命令:
-
all_features.dtypes:dtypes属性用于获取数据框中每一列的数据类型。这个属性返回一个 Series 对象,其中索引是数据框的列名,值是对应列的数据类型。 -
[all_features.dtypes != 'object']:这是一个布尔索引操作,它对数据框中的每一列进行判断,如果列的数据类型不是'object'(即非字符串类型),则返回True,否则返回False。这样就得到了一个布尔类型的 Series,其中值为True的位置表示对应列是数值型特征。 -
.index:最后,.index属性用于获取布尔 Series 中值为True的索引,即数值型特征的列索引。
因此,整个命令的作用是获取数据框 all_features 中所有数值型特征的列索引,并将这些索引保存在变量 numeric_features 中。这样一来,您就可以通过 numeric_features 来访问数据框中的数值型特征,进行进一步的处理或分析。
12. 训练数据特征值做标准化
这条命令是对数据框 all_features 中的所有数值型特征进行标准化(即将数据转换为均值为0,标准差为1的分布)。让我们逐步解释这条命令:
-
all_features[numeric_features]:这部分表示从数据框all_features中选取数值型特征,其中numeric_features是之前获取到的数值型特征的列索引。 -
.apply(lambda x: (x - x.mean()) / (x.std())):这部分是对选取到的数值型特征应用函数。其中,lambda x: (x - x.mean()) / (x.std())是一个匿名函数,用于计算每列数据的标准化值。具体步骤如下:x.mean():对每列数据取均值,即计算每列数据的平均值。x.std():对每列数据取标准差,即计算每列数据的标准差。(x - x.mean()) / (x.std()):对每列数据进行标准化处理,即用每个数据减去该列数据的均值,再除以该列数据的标准差。
这样就完成了对数值型特征的标准化处理,使得每列数据都符合均值为0,标准差为1的标准正态分布。这种处理通常有助于提高机器学习模型的性能,特别是对于基于距离或者梯度的模型来说。
13. 报错 rnumpy.core._exceptions._ArrayMemoryError: Unable to allocate 76.4 GiB for an array with shape (216160, 47439) and data type object
(79065, 216160)
这个报错是由于尝试分配过大的内存给数组导致的。报错中显示尝试分配 76.4 GiB 的内存给一个形状为 (216160, 47439) 的数组,且数据类型为 object。这意味着您在进行某个操作时,系统无法分配这么大的内存来存储这个数组。
可能的原因和解决方法包括:
-
**内存不足:**您的系统内存可能不足以分配给这么大的数组。您可以尝试释放其他占用大量内存的进程或程序,或者考虑在更高内存的环境中运行程序。
-
**数据类型问题:**数组的数据类型为 object,这通常表示数组中的元素是 Python 对象而不是基本数据类型(如整数、浮点数等)。这种情况下,数组的内存消耗会更大。如果可能的话,尝试使用更小的数据类型来存储数据,如 float64 替代 object。
-
**数组大小优化:**考虑是否可以通过分块处理数据或者使用稀疏数据结构来减少数组的大小,以降低内存消耗。
-
**优化代码逻辑:**检查代码是否存在不必要的内存占用或者重复计算,优化代码逻辑可以减少内存消耗。
-
**分布式计算:**如果数据量过大无法在单机上处理,考虑使用分布式计算框架(如Dask、Spark等)来处理数据,以利用多台机器的资源。
在解决这个问题时,需要根据具体情况采取相应的措施,如增加系统内存、优化数据结构或算法、分布式计算等。
14. 根据列名选取数据
您可以使用 Pandas 的 loc 或 iloc 方法根据列名选取指定的列,并组成新的 DataFrame 或 Series。下面是使用这两种方法的示例:
- 使用
loc方法选取指定列名的列,然后将这些列组成新的 DataFrame:
import pandas as pd# 示例数据
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)# 选取列名为'A'和'C'的列组成新的 DataFrame
new_df = df.loc[:, ['A', 'C']]
print(new_df)
- 使用
iloc方法根据列的索引位置选取列,然后将这些列组成新的 DataFrame 或 Series:
import pandas as pd# 示例数据
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)# 选取索引位置为0和2的列组成新的 DataFrame
new_df = df.iloc[:, [0, 2]]
print(new_df)
在这两个示例中,loc 和 iloc 方法的第一个参数表示行的选取方式,使用 : 表示选取所有行;第二个参数是列的选取方式,使用列名或列的索引位置列表来指定要选取的列。选取完成后,可以将选取的列组成新的 DataFrame 或 Series,根据需要进行进一步的操作。