公司捕获和存储的数据比以往任何时候都多,因为它们依赖数据来做出关键的业务决策、改进服务或产品,或为最终用户(客户)提供更好的服务。了解各种大数据存储技术对于为商业智能(BI)、数据分析和机器学习(ML)工作负载建立强大的数据存储管道至关重要。
为了维护这样的大数据,数据湖和数据仓库架构已被公司广泛使用。但这两种体系结构都有一定的局限性,我们将在博客的后面部分讨论这些局限性,从而发现一种称为Data Lakehouse的新体系结构。
然而,在深入研究Data Lakehouse架构的细节之前,重要的是首先了解Data Lake和Data Warehouse,其中的一些局限性,以及我们为什么首先需要它们?
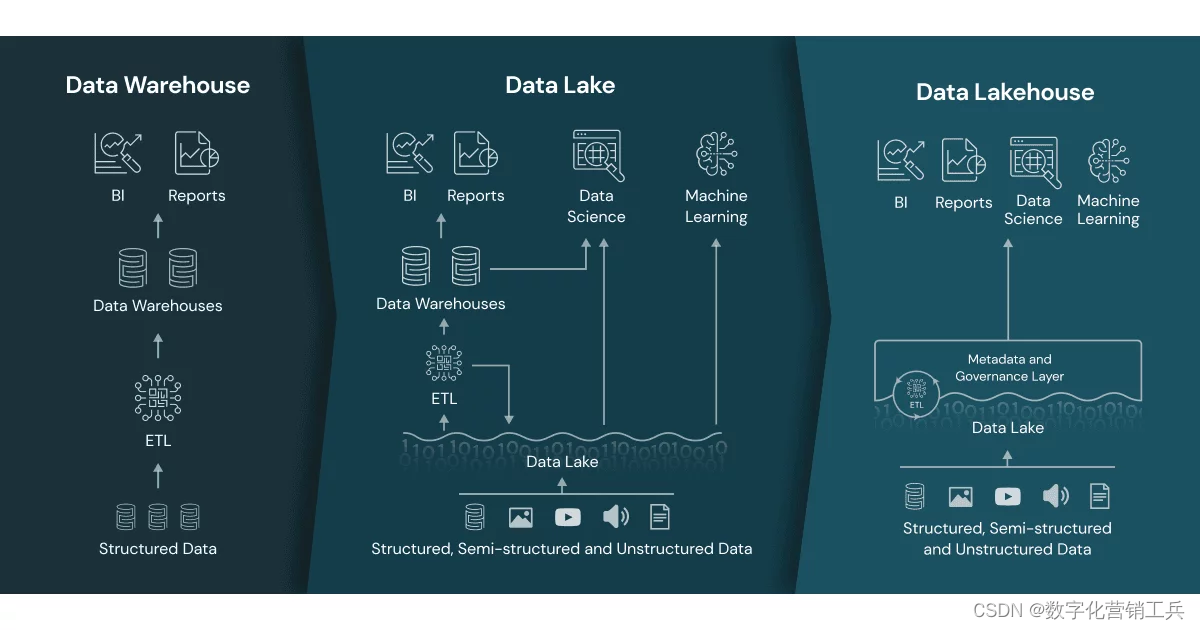
一、什么是Data Lake架构
数据湖是一个集中的系统或存储库,以自然/原始格式存储大数据,通常是对象、Blob或文件。您可以将任何类型的数据存储在任何结构中(结构化、非结构化、半结构化)。例如,文件、图像、音乐、视频、文本或表格。数据湖的主要目的是使不同来源的组织数据可供不同的最终用户访问。
Data Lake在加载之前不需要像数据仓库的ETL机制那样进行数据转换,因为它的模式是在用户加载数据时动态定义的,并且没有根据某些预定义的模式进行验证。
二、Data Lake架构的局限性
1. BI和报告记录不佳:在数据湖体系结构中,BI和报告具有挑战性,因为数据湖需要额外的工具来支持SQL查询。
2. 数据可靠性方面的妥协:由于数据没有以任何方式结构化,因此数据质量、完整性和可靠性成为该体系结构中的一个关键挑战。
3. 数据治理:由于异构结构无法以统一的方式获取数据,数据治理变得困难。
三、什么是数据仓库(Data Warehouse)?
数据仓库是一个集中的存储库,用于存储从不同来源积累的数据。这种情况下的数据是结构化的,并根据预定义的模式进行验证。它依赖于ETL(提取-转换-加载)机制,在该机制中,数据需要在加载前进行转换。数据仓库的目的是生成报告、将数据提供给BI工具、预测趋势和训练机器学习模型。ETL(提取-加载-转换)过程用于存储来自多个来源的数据,如API、数据库、云存储等。
数据仓库体系结构的局限性
1. 数据处理不灵活:在数据仓库架构中只能处理结构化数据。
2. 成本高昂的存储:管理大量数据需要更高的成本。
3. 无法处理复杂数据:仓库架构通常不适合处理机器学习的复杂数据。
四、什么是Data Lakehouse Architecture?
Data Lakehouse体系结构是两种体系结构的结合——Data Lake和Data Warehouse,两者融合了最好的元素。它既支持数据仓库体系结构的ACID事务功能,也支持数据湖体系结构的可扩展性、灵活性和成本效益。
五、是什么促使企业需要创建Data Lakehouse
使用两层架构;数据湖和数据仓库同时导致了巨大的成本,并且很难管理,因为数据必须在具有两种不同结构的两个不同位置进行维护和同步。
由于上述两种架构的挑战和局限性,许多组织认为有必要将这两种架构组合成一个系统(两层架构),以便团队能够拥有可用于数据科学、机器学习和业务分析的最完整和最新数据。
Data bricks的专家在2021年的创新数据系统研究会议上介绍了这种架构,Data Lakehouse从此成为官方的数据管理架构。
(图片来源:https://databricks.com/)
通过以下元素,Data Lakehouse架构解决了Data Warehouse和DataLake架构的缺点:
1. 减少数据冗余:当一个组织使用数据仓库和lake的多个数据源时,它可以统一数据并减少数据重复。
2. 降低运营成本:由于数据没有存储在多个系统上,因此持续的运营成本将降低。
3. 更好的数据组织:它通过强制执行模式来更好地组织数据湖中的数据。
4. 在数据分析、BI和ML中的有效使用:它不仅有助于存储大量数据并降低成本,而且有助于有效地将数据用于分析、BI、报告和机器学习。
因此,与多个解决方案系统相比,单个数据Lakehouse提供了几个优势,包括减少了数据移动和冗余,简化了模式和数据治理,以及减少了管理时间和精力。分析工具的直接数据访问和低成本的数据存储。
六、专业人的干专业的事 - 雇佣专门的后端开发人员
如果您想从当前的数据库体系结构迁移或切换到Datalake House,以获得数据的最大价值,请考虑雇佣专业人员将数据库架构到Data Lake House.




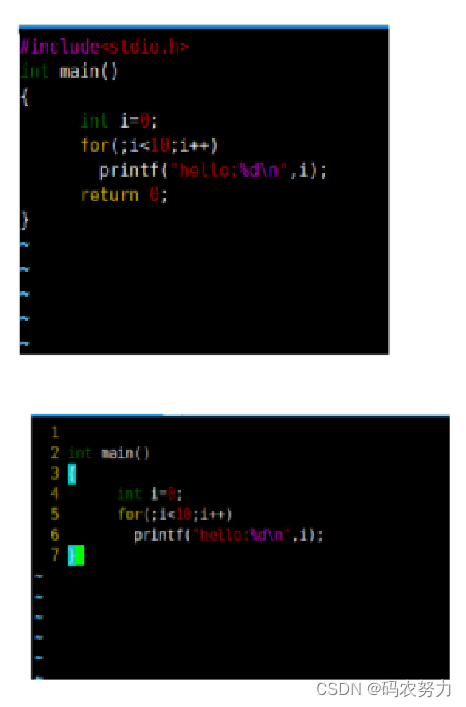
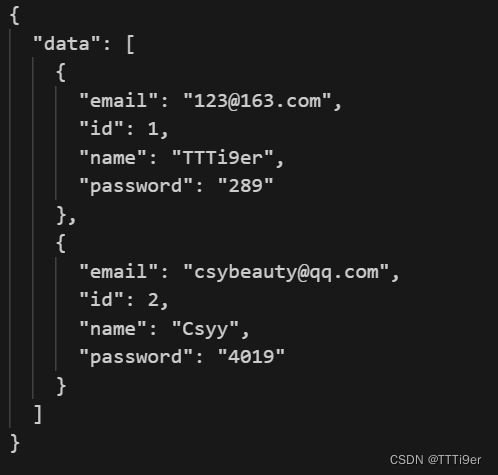
![[笔试强训day08]](https://img-blog.csdnimg.cn/direct/d5a37aee67a047399e3caf311611a278.png)