大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
TimesFM是一种预测的基础模型,在包含1000亿个现实世界的大型时间序列语料库上进行了预训练,在来自不同领域和粒度的各种公共基准上显示了令人印象深刻的zero-shot的性能。

TimesFM
时间序列预测是一门艺术,尤其在金融和经济领域,当然在交通、健康、天气等其他领域应用也十分广泛。若能以高精度和高置信度的预测股票、基金、GDP、COVID-19病例就可以提前预判,然后进行更好的决策和优化资源调度。时间序列预测的分析涉及处理复杂且动态的模式,例如趋势、季节性、周期、异常值和噪音。同时时间序列模型需要大量数据和领域知识来针对特定任务和数据集的训练和模型微调。
统计和机器学习模型等传统方法通过分析时序的平稳性和ACF特征等,利用一些基本模型例如ARIMA,但是一般而言难以捕获时间序列数据中的长期依赖性和非线性关系。近期也有一些基于深度学习的方法,例如DeepAR、WaveNet等循环神经网络和卷积神经网络,可以提供更好的性能,计算成本也随之增加,同时还需要额外的大数据。
谷歌研究团队提出了一种设想,是否能够在任何时间序列数据集上实现准确的零样本预测,且不需要任何额外的领域知识。于是它们提出了TimesFM。
TimesFM是一种Decode-Only的基础模型,这个模型在大型且多样化的时间序列语料库上进行预训练,且可以为未见过的数据集生成可变长度的预测。它基于自注意力机制和传统的位置编码,提炼出数据中不同时间点之间的关系,以及捕获数据中的时间顺序的信息。最重要的是TimesFM 还具有可扩展性、可概括性和可解释性。

训练与推理模式
训练场景:
TimesFM中允许生成时序数据块(下文成为patch)长于比输入时序数据块。例如,假设输入patch长度为32,生成patch的长度为128。预训练过程中,模型会被按照:
-
前32个时间点来预测接下来的128个时间点进行训练。
-
前64个时间点来预测接下来的128个时间步,预测接下来的65-192
-
前96个时间点来预测接下来的128个时间步,预测接下来的97-224
-
……以此类推
推理场景:
在推理过程中,假设给模型一个长度为256的新时间序列,并负责预测未来的接下来 256 个时间步长。 因为输出的patch长度预设为128,所以:
-
利用256的新实践序列通过模型生成257-384(长度为128)的预测
-
利用256+第一次生成时序数据再次生成385-512(长度为128)的预测
若输出的patch的长度预设为32,那么对于刚才的任务需要执行8个自回归生成迭代,而不是之前的两步。patch size某种意义是个超参数,需要根据场景进行权衡。

架构概览
TimesFM是一种基于区块的decoder-only的模型,其灵感来自于 Vision Transformer (ViT) 和 Generative Pre-trained Transformer (GPT)。它由三个主要组件组成:输入编码器、解码器和输出解码器。
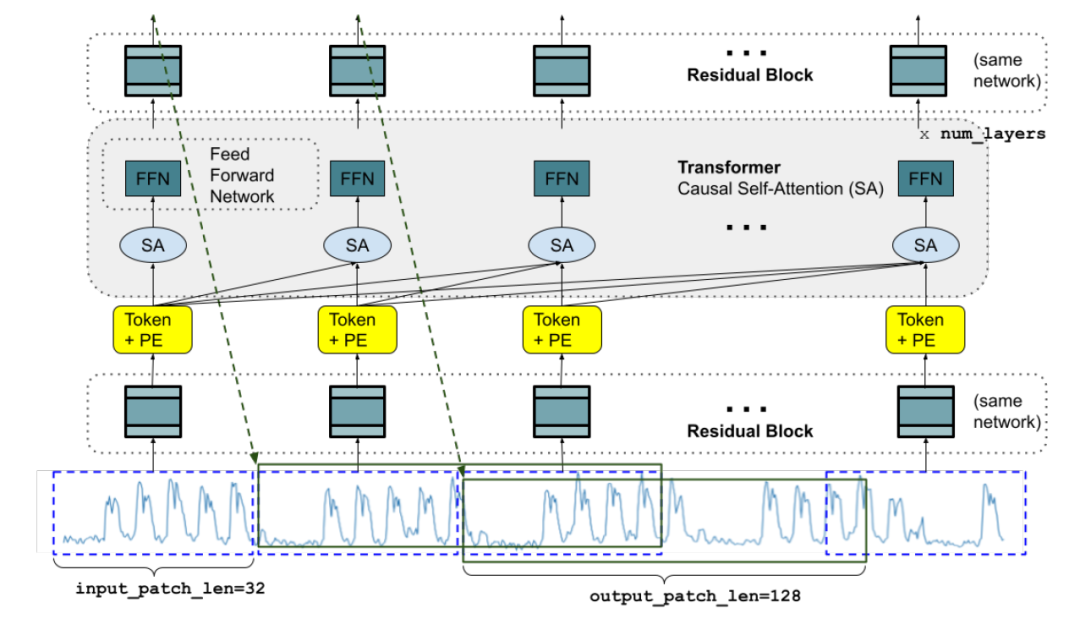
每个切分的时序数据块都由残差块(如模型定义中所定义)处理为Transformer层能够接收的向量,然后将向量添加到位置编码中并馈送到 nl个变压器层中。
SA指的是self-attention(这里使用的是多头因果注意力),FFN是transformer中的全连接层。 最后生成的Token通过残差块映射回输出
输入编码器负责将时间序列数据映射为Token,输入编码器首先将时间序列数据分割成相等长度的时序数据块,然后对每个时序数据块进行线性变化 进而得到Token。
TimesFM首先将输入切分成连续的不重叠的patch,每个patch的数据块会通过残差网络投影到长度为model_dim的向量。这个向量还有带有覆盖标识信息,例如mask1:L中的数值1代表着输入y1:L可以被忽略不给与处理。
|
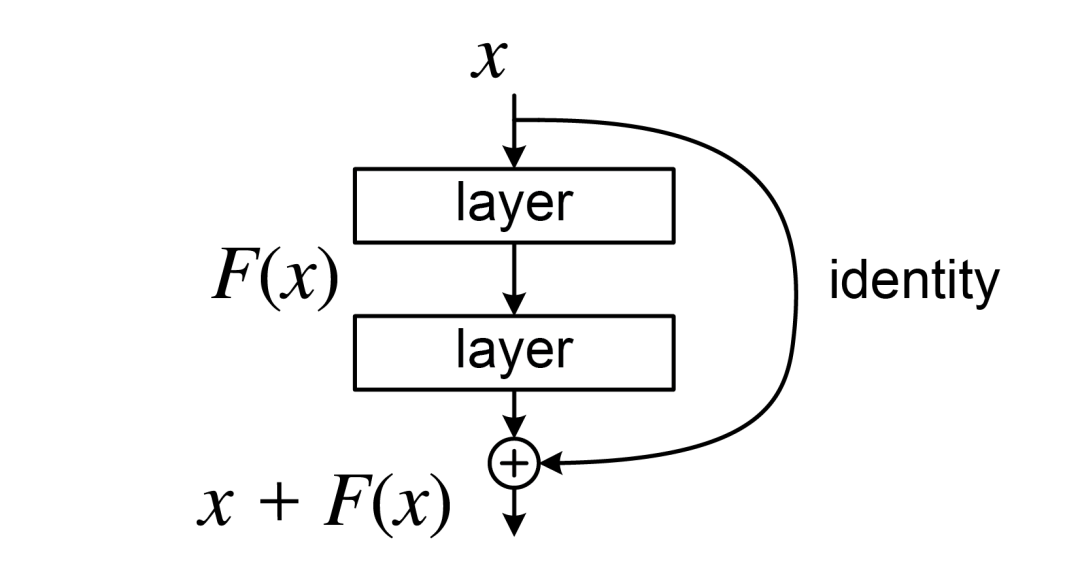
| 左图为残差块,输入为x,输出为F(x)+x。残差块很容易理解。在传统神经网络中,每一层都会馈送到下一层。要是具有残差块的网络中,每一层都会馈送到下一层,同时还会报送2-3跳之外的层进行相加。 |
那就意味着输入y1:L会被按照patch长度p切分成相应的块数。第j个patch 可以表示为˜yj = y[p(j−1)+1:pj]。对应的覆盖标识为˜mj = m[p(j−1)+1:pj]。那么残差网络的输入为˜yj ⊙(1-˜mj )。
![]()
解码器是模型的核心组件,其中应用了自注意力和位置编码机制。解码器由多层组成,每层都包含一个多头自注意力模块和一个前馈网络。自注意力模块允许模型学习序列中不同标记之间的依赖关系和关系,无论是在输入还是输出中。前馈网络允许模型学习标记的非线性变换。解码器还使用层归一化和残差连接来提高模型的稳定性和效率。
位置编码是一种将时间信息注入Token(令牌)序列的技术,因为自注意力模块没有任何固有的顺序或位置概念。在将令牌嵌入送入解码器之前,将位置编码添加到令牌嵌入中。位置编码可以是学习的,也可以是固定的,具体取决于模型的选择。在 TimesFM中,位置编码采用学习的模式,意味着模型可以适应数据中不同的时间粒度和频率。
输出解码器负责将输出Token映射到最终预测。输出解码器对每个输出Token应用线性投影以获得标量值,该标量值表示相应时间点的预测值。输出解码器还使用softmax函数对输出值进行归一化并确保它们在合理的范围内。

TimesFM的核心功能之一就是可以根据需求进行预测可变长度的输出。这意味着该模型可以预测任意数量的未来时间点,而不需要任何重新训练或微调。

过程回放
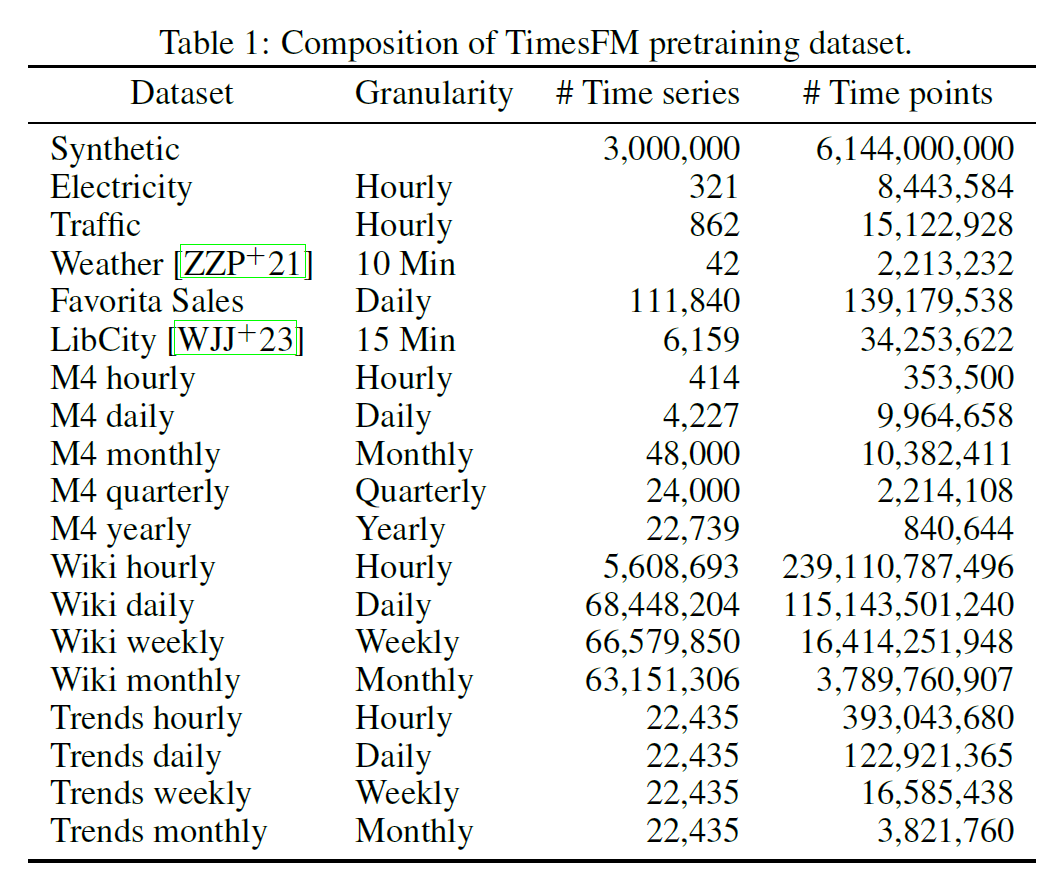
TimesFM在现实世界的海量时间序列语料库上进行了预训练,这些时间序列语料库源自维基百科和谷歌搜索趋势以及合成数据。
用于预训练的数据集多种多样且异构,涵盖不同的领域、时间粒度和噪声水平。其中一些领域包括金融、经济、健康、天气、体育、娱乐等。一些时间粒度包括每小时、每天、每周、每月和每年。一些噪音级别包括低、中和高。合成数据是通过使用具有不同参数和噪声水平的正弦函数、线性函数和随机函数的不同组合来生成的。合成数据用于增强现实世界数据并增加预训练语料库的多样性和复杂性。
训练使用80%的真实数据和20%的合成数据进行采样,每小时 + 每小时、每日、每周和每月数据集有相同的权重。只要时间序列的长度允许,就使用最大上下文长度512进行训练。对于每周粒度,因为没有足够长的时间序列,所以使用最大上下文长度256。在≥月粒度则使用最大上下文长度64。同时每个输入的时间序列采用第一个输入数据块的均值和标准差进行缩放。

性能
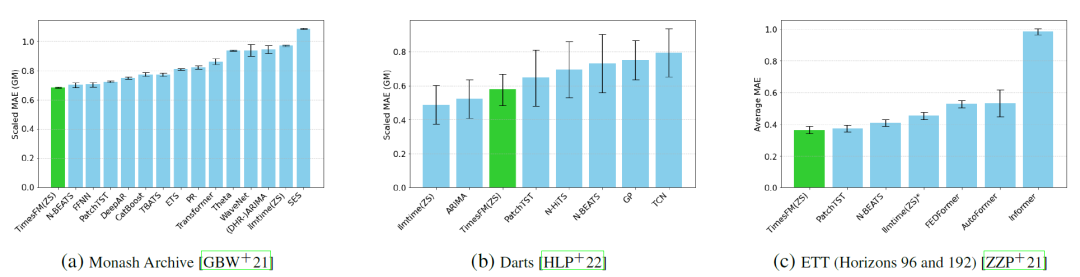
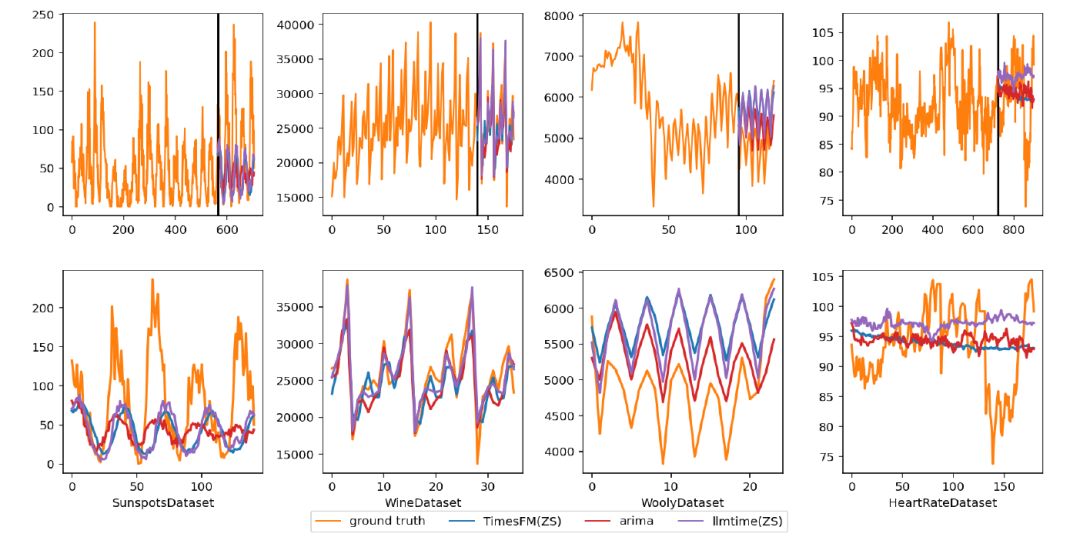
TimesFM 在大多数基准和指标上都优于其他最先进的方法,上图中的指标越低越好。下图为主流算法的可视化图拟合图。
TimesFM还有局限性的,TimesFM 可以处理大型和高维时间序列数据,得益于其可变长度输出解码器,然而TimesFM需要大量的计算资源和内存来训练和运行,特别是对于长而复杂的时间序列数据。
由于其学习的位置编码,它可以适应不同的时间粒度和频率。然而,TimesFM也可能会遇到一些域偏移和分布不匹配的问题,特别是对于与预训练数据有很大不同或信噪比非常低的数据集。
值得注意的是TimesFM依靠自注意力机制和输出解码器可以为其预测生成提供可解释性。