简介:
RAG(Retrieval-Augmented Generation)系统是一种结合了检索(Retrieval)和生成(Generation)的机制,用于提高大型语言模型(LLMs)在特定任务上的表现。随着技术的发展,RAG系统经历了几个阶段的演变,包括Naive RAG、Advanced RAG和Modular RAG。
流程图
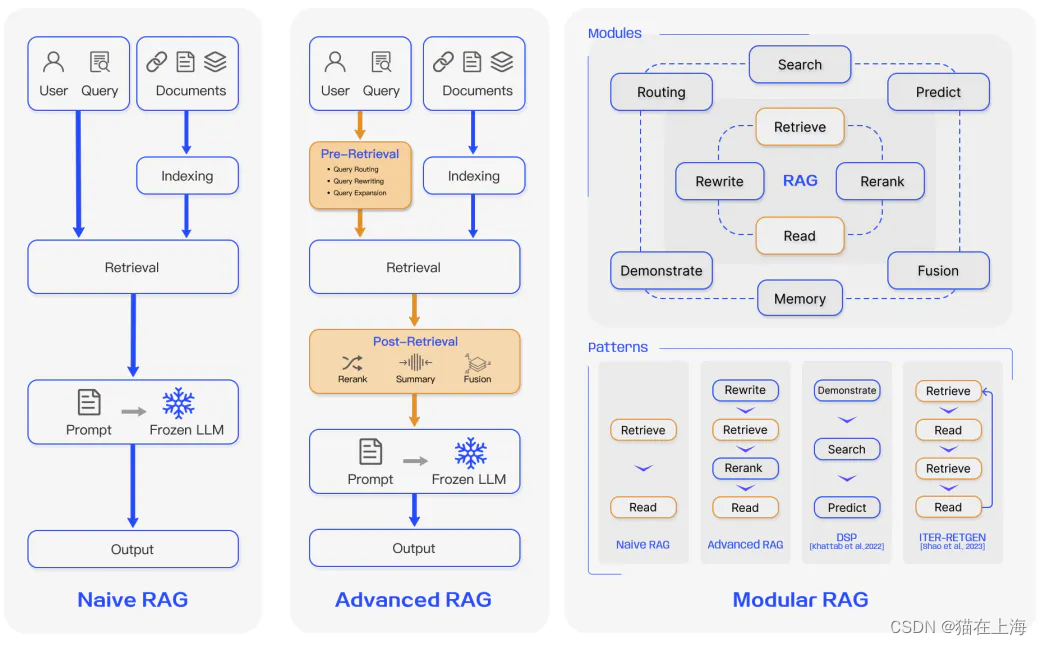
Naive RAG:
Naive RAG是RAG系统的初级阶段,它通常涉及一个简单的“检索-阅读”过程。
在这个范式中,系统首先根据用户的问题检索相关信息,然后使用检索到的信息生成答案。
Naive RAG面临的挑战包括检索的相关性、生成的连贯性以及如何有效利用检索到的信息等问题。
Advanced RAG:
Advanced RAG是在Naive RAG的基础上进行的改进,它通过更精细化的数据处理来提高检索生成的质量。
这种范式可能会引入预检索和检索后的处理,如优化数据索引、使用滑动窗口、细粒度分割和元数据等方法。
Advanced RAG还可能包括多次j检索或迭代检索,以及对检索到的文档进行重排序(reranking)来提高生成文本的相关性和准确性。
Modular RAG:
Modular RAG代表了RAG系统的更高级阶段,它通过引入新的模块来丰富RAG过程,并提供更多的灵活性。
这种范式允许模块的替换或重新配置,可以根据特定问题上下文动态地组织RAG过程。
Modular RAG结合了微调等其他技术,并且可能包括自适应检索、多答案融合和主动学习等高级功能。
区别:
Naive RAG是最基本的RAG实现,它通常只涉及简单的检索和生成步骤,没有太多复杂的优化。
Advanced RAG在Naive RAG的基础上增加了更多的策略和优化,如索引优化、迭代检索和检索后处理,以提高系统的性能。
Modular RAG则进一步发展,提供了更高的灵活性和可定制性,允许通过引入不同的模块和调整模块间的流程来适应各种复杂的任务和需求。
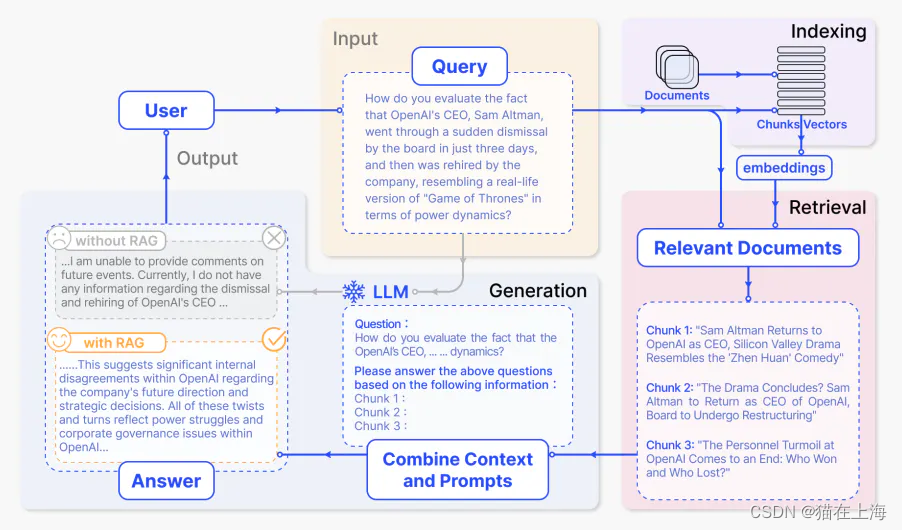
工作流程:
- 输入: LLM系统响应的问题称为输入。如果没有使用RAG,则直接使用LLM来回答问题。
- 索引:如果使用 RAG,则首先对一系列相关文档进行分块,生成块的嵌入,然后将它们索引到向量存储中,从而对它们进行索引。在推理时,查询也以类似的方式嵌入。
- 检索:通过将查询与索引向量进行比较来获得相关文档,也表示为“相关文档”。
- 生成:相关文档与原始提示相结合作为附加上下文。然后将组合的文本和提示传递到模型以生成响应,然后将其准备为系统向用户的最终输出。
经典的流程图
以上是文本的全部内容感谢阅读。