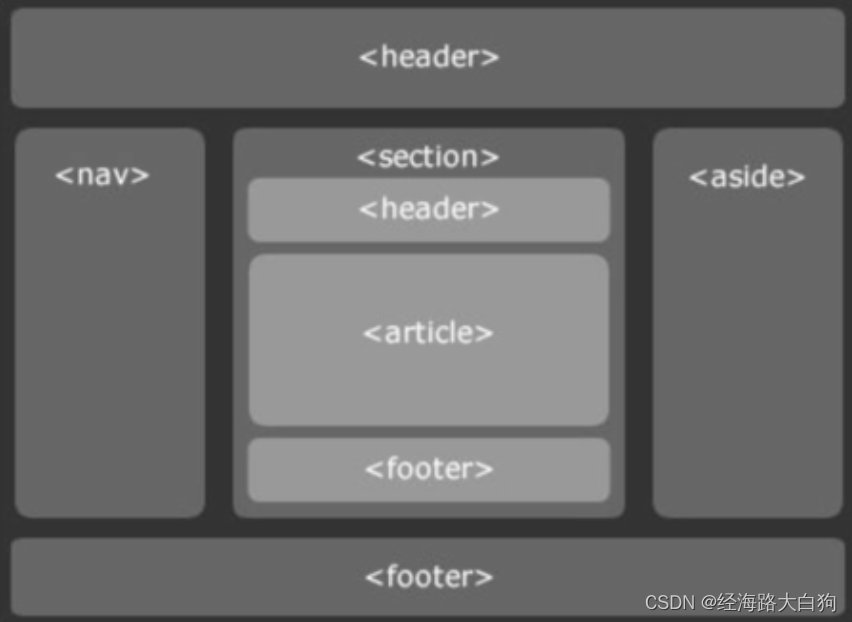
目录
一.选择排序
1.简单选择排序
2.堆排序
•建立大根堆
•基于大根堆进行排序
堆排序算法效率:
堆排序算法稳定性:
3.堆的插入和删除
•在堆中插入新元素
•在堆中删除元素
二.归并排序
归并排序算法效率:
归并排序算法的稳定性:
三.基数排序
基数排序的算法效率:
基数排序算法的稳定性:
下一篇博客会着重讲外部排序~
一.选择排序
每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序子序列。
1.简单选择排序
算法思想:每一趟在待排序元素中选取关键字最小的元素加入有序子序列。
算法过程:
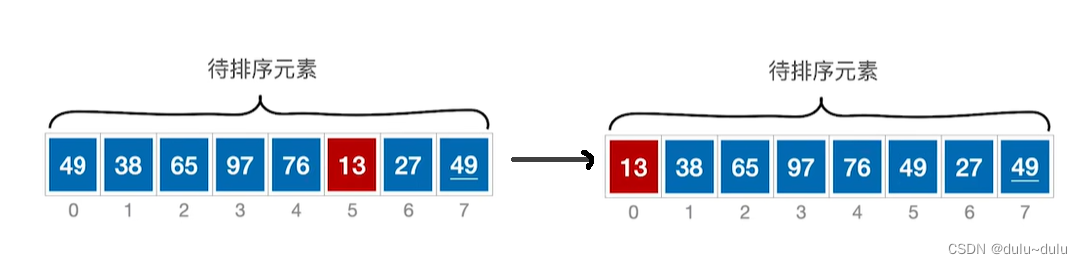
① 对待排序的序列从左往右扫描,将关键字最小的元素与第一个元素互换位置:
② 继续在待排序序列中找到关键字最小的元素,将他换到前面位置:
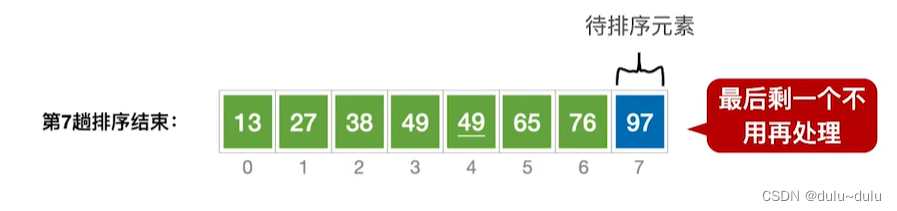
以此类推,最后一个元素不用处理,所以对n个元素的简单选择排序只需要n-1趟处理。

//交换
void swap(int &a,int …&b){int temp=a;a=b;b=temp;
}//简单选择排序
void SelectSort(int A[],int n){for(int i=0; i<n-l; i++){ //一共进行n-1趟int min=i; //记录最小元素位置for(int j=i+1; j<n; j++) //在A[i..n-1]中选择最小的元素if(A[j]<A[min]) min=j; //更新最小元素位置if(min!=i) swap(A[i],A[min]); //封装的swap()函数共移动元素3次}
}算法效率:
简单选择排序的空间复杂度为O(1),只需要定义几个变量,所以空间复杂度为常数级。
时间复杂度:
无论待排序的序列是有序、逆序、还是乱序,一定需要 n-1 趟处理。
所以,总共需要对比关键字(n-1)+(n-2)+...+1 = 次,元素交换次数 <n-1。
所以时间复杂度为O(n^2)
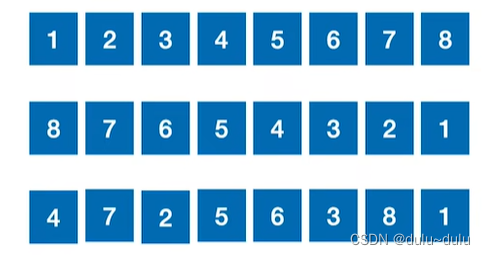
算法稳定性:
由下图的例子可以看出,2的相对位置变了,所以这个算法是不稳定的。
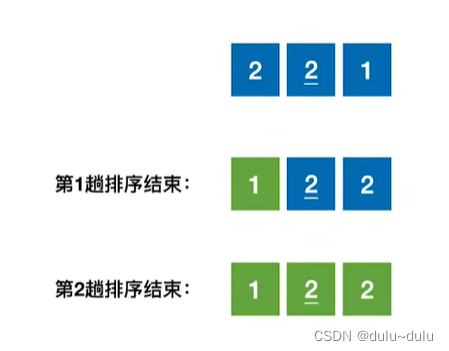
算法的适用性:
简单选择排序适用于顺序表也适用于链表。
逻辑和顺序表的简单选择排序相同:
// 定义链表节点结构体
struct ListNode {int val; // 存储整数值的成员变量ListNode* next; // 指向下一个节点的指针
};// 简单选择排序的链表实现
void SelectSort(ListNode* head) {ListNode* current = head;while (current != nullptr) {ListNode* minNode = current;ListNode* runner = current->next;while (runner != nullptr) {if (runner->val < minNode->val) {minNode = runner;}runner = runner->next;}if (minNode != current) {int temp = current->val;current->val = minNode->val;minNode->val = temp;}current = current->next;}
}
2.堆排序
算法思想:每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序子序列。
什么是"堆(Heap)"?
若n个关键字序列L[1....n]满足下面某一条性质,则称为堆(Heap):
① 若满足:L(i)>L(2i) 且 L(i)>L(2i+1)
----大根堆(大顶堆)
② 若满足:L(i)≤L(2i) 且 L(i)≤L(2i+1)
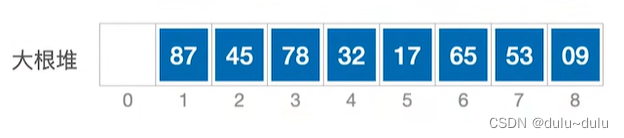

用二叉树更容易理解。如下图所示,是完全二叉树的顺序存储:
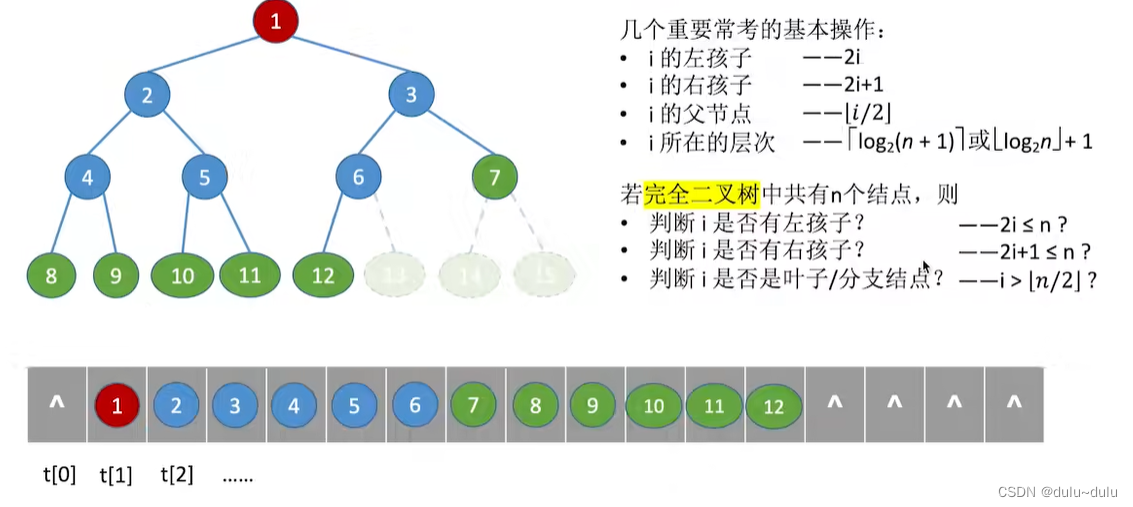
堆在逻辑上可以理解为顺序存储的完全二叉树,编号为1的结点就是这棵二叉树的根节点,编号为i的节点,其左孩子的编号应为2i,右孩子编号应为2i+1。
当i n/2,时这一点一定是一个分支节点:
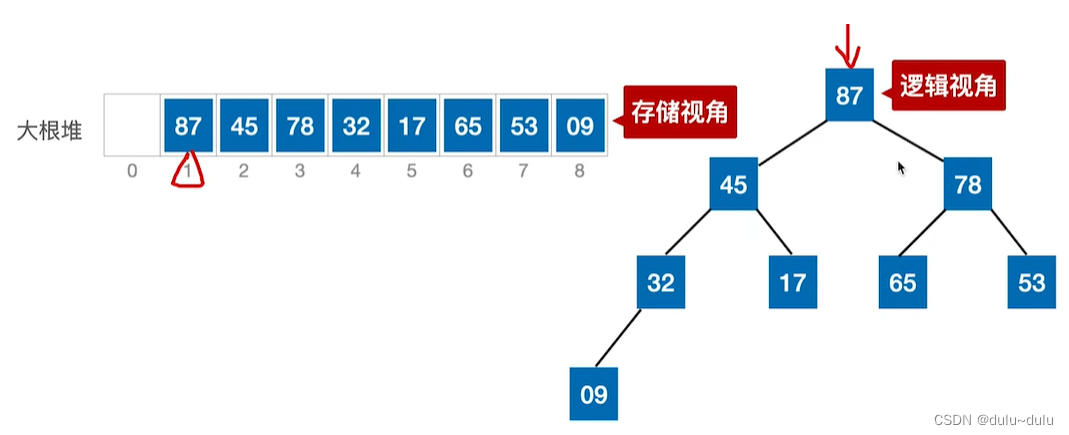
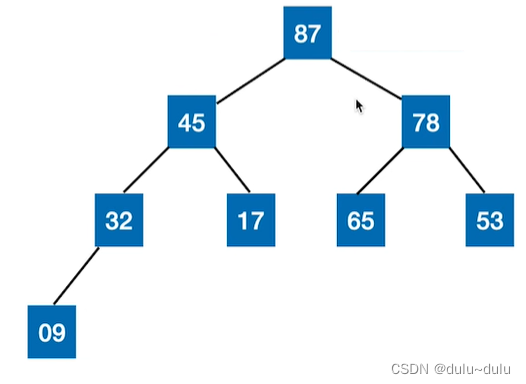
所以大根堆就是:在完全二叉树中,如果所有子树的根节点 他的左,右孩子的值,那么这样的一棵顺序存储的完全二叉树就是一个大根堆。例如下图,就是一个大根堆:
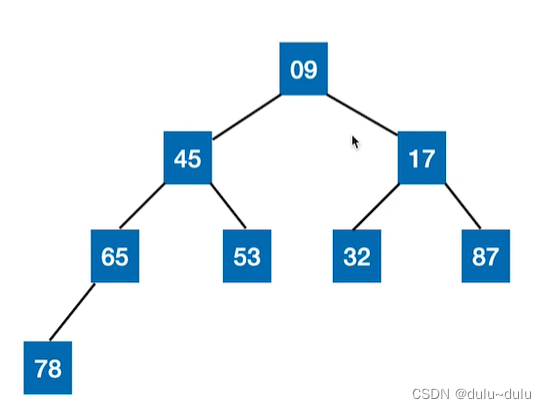
同理,小根堆就是 所有子树的根节点 左,右孩子的值 的完全二叉树:
选择排序算法的思想就是每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序子序列。若待排序序列是大根堆或者小根堆,那么这个算法的实现就很简单了。
所以首先将原始的序列建立为大根堆/小根堆,在进行选择排序。
•建立大根堆
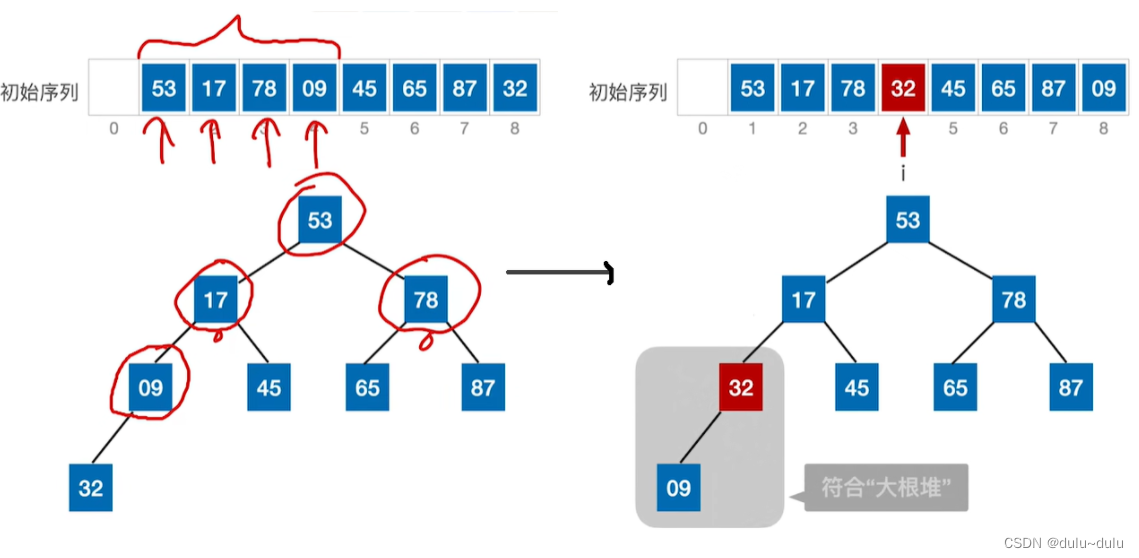
将初始序列中所有非终端结点都检查一遍,是否满足大根堆的要求(根左,右),如果不满足,则进行调整。在顺序存储的完全二叉树中,非终端节点编号
:1,2,3,4
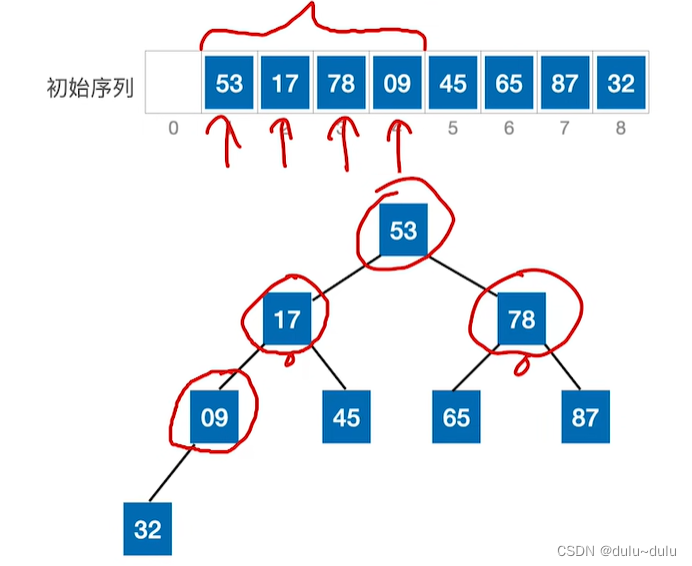
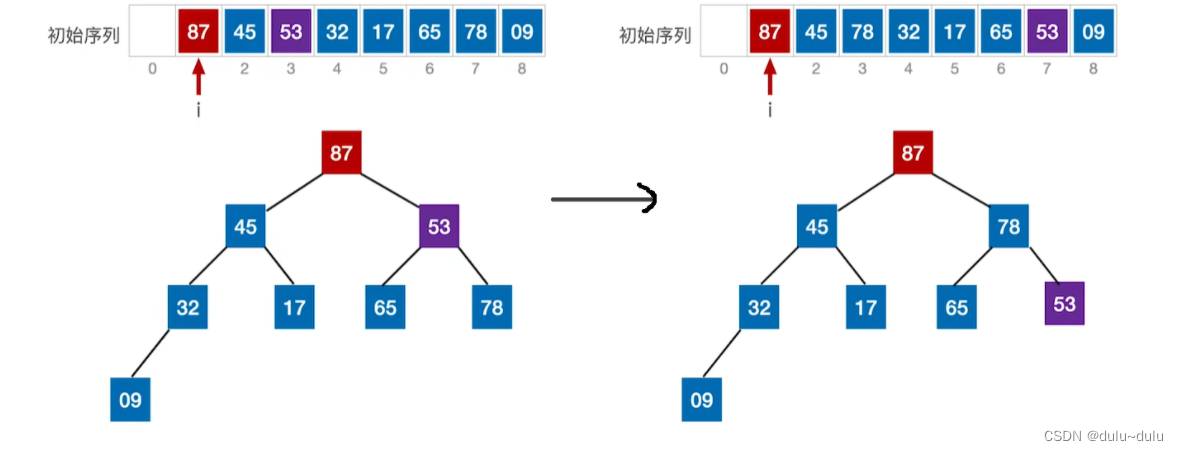
首先处理4号节点,这个节点是所有分支节点中编号最大的节点。检查以9为根节点的子树是否满足大根堆的要求,显然不满足。所以,将当前节点与更大的孩子互换:
接下来要处理的元素是78,由于其右孩子87>78,所以将87和78这两个数据元素进行位置互换:
接下来处理的元素是17,由于其比左右两个孩子的值都小,所以和值更大的一个孩子进行互换,所以17和45进行位置互换:
接下来处理1号节点,即53这个数据元素。右孩子87比53更大,所以两个元素位置互换:
但是更小的元素"下坠",使得下一层的子树不满足大根堆的要求。所以用之前的方法,让小元素不断"下坠"。
至此这棵二叉树已经符合大根堆的要求。
//建立大根堆
void BuildMaxHeap(int A[],int len){for(int i=len/2; i>0; i--) //从后往前调整所有非终端结点HeadAdjust(A,i,len);
}//将以 k 为根的子树调整为大根堆
void HeadAdjust(int A[],int k,int len){A[0]=A[k]; //A[0]暂存子树的根结点for(int i=2*k; i<=len; i*=2){ //沿key较大的子结点向下筛选。i=2*k,也就是让i指向当前结点的左孩子if(i<len && A[i]<A[i+1]) //若i>=len,则没有右孩子,A[i]<A[i+1],说明右孩子更大i++; //取key较大的子结点的下标if(A[0]>=A[i]) break; //判断当前的结点是否比更大的孩子还大,如果是,则说明当前结点满足“根>=左,右”else{A[k]=A[i]; //将A[i]调整到双亲结点上k=i; //修改k值,以便继续向下筛选}}A[k]=A[0]; //被筛选结点的值放入最终位置
}
补充:懂得大根堆的逻辑,小根堆就非常简单了:
//建立小根堆
BuildMinHeap(int A[],int len){for(int i=len/2;i>0;i--)HeadAdjust(A,i,len);
} void HeadAdjust(int A[],int k,int len){A[0]=A[k];for(int i=2*k;i<=len;i*=2){if(i<len && A[i]>A[i+1])i++;if(A[0]<=A[i]) break;else{A[k]=A[i];k=i;}} A[k]=A[0];
} •基于大根堆进行排序
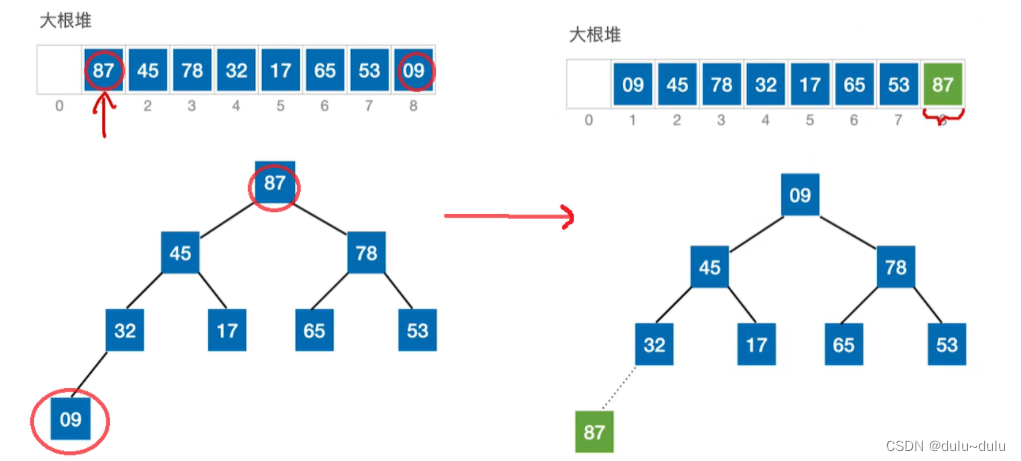
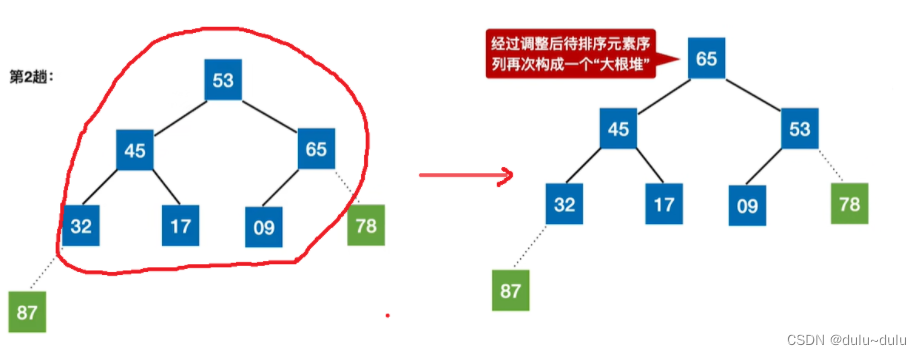
每一趟将堆顶元素加入有序子序列,也就是将堆顶元素与待排序序列的最后一个元素进行交换。
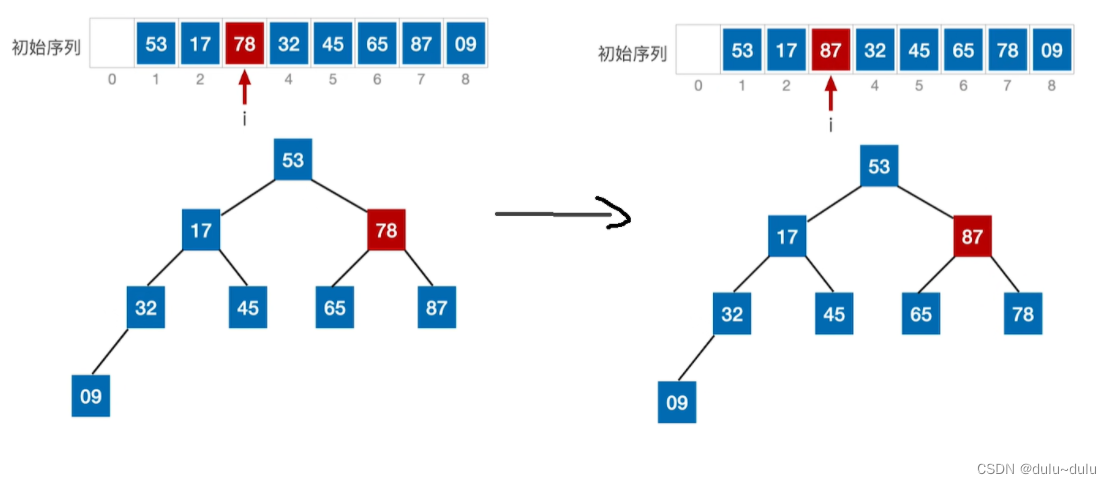
① 如上图所示,经过交换后,87的位置就固定了,只把其余数据元素看作一个堆。
由于09这个数据元素被换到了堆顶,圈起来的部分已经不是大根堆,所以将09不断“ 下坠”,直到达到“大根堆”的要求。
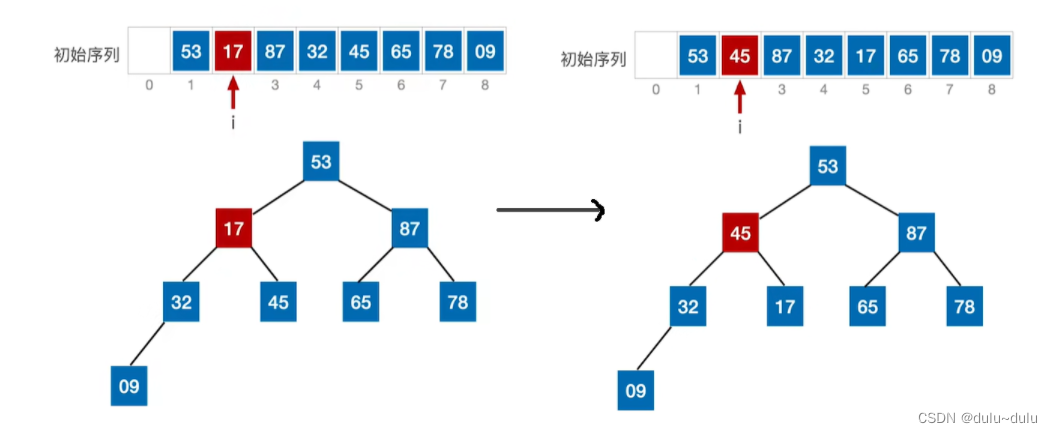
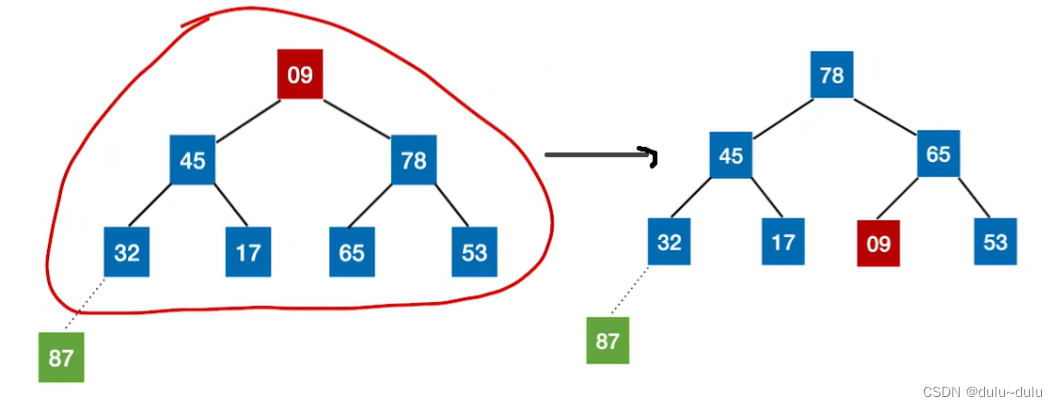
② 重复上面的步骤,将堆顶元素和堆低元素互换位置:
排除87和78这两个元素,将红圈内的待排序元素调整为"大根堆"。
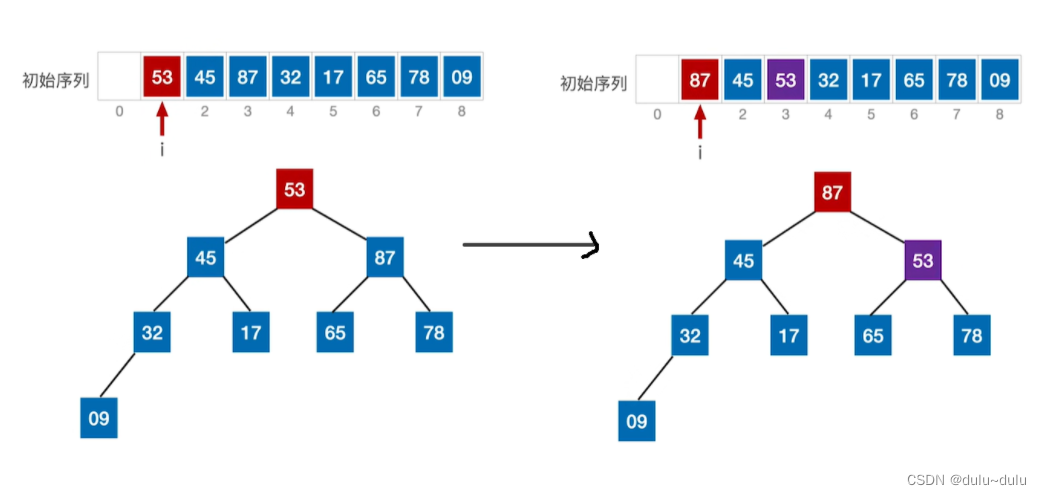
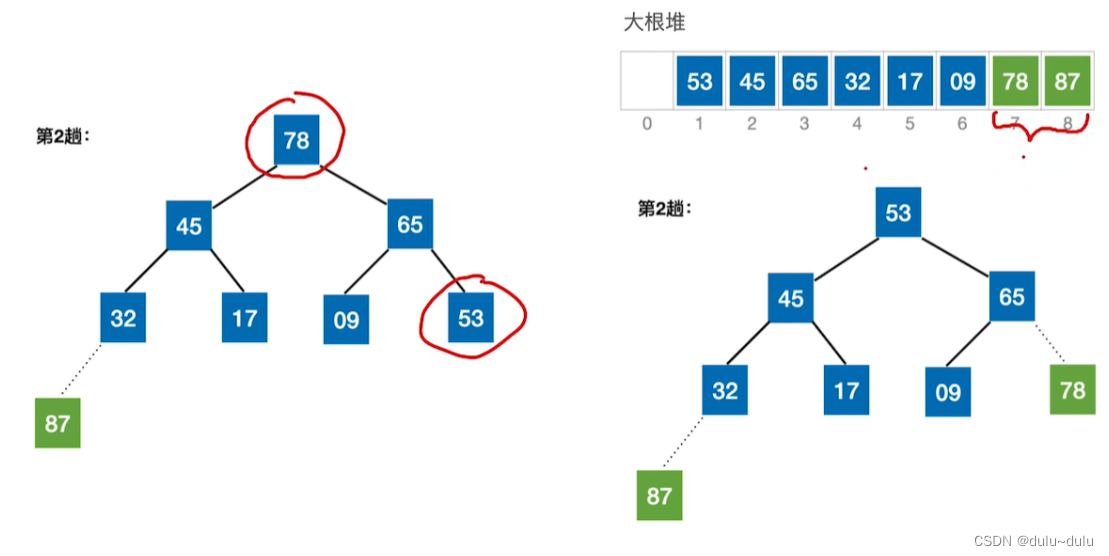
以此类推,经过n-1趟处理后,只剩下最后一个待排序元素时,就不用进行调整了。
注:基于“大根堆”的堆排序得到“递增序列”,基于"小根堆"的堆排序得到"递减序列"。
//建立大根堆
void BuildMaxHeap(int A[],int len)//将以 k 为根的子树调整为大根堆
void HeadAdjust(int A[],int k,int len)void HeapSort(int A[],int len){BuildMaxHeap(A,len);for(int i=len;i>1;i--){ //n-1趟的交换和建堆过程swap(A[i],A[1]); //堆顶元素和堆底元素交换HeadAdjust(A,1,i-1); //把剩余的待排序元素整理成堆}
}堆排序算法效率:
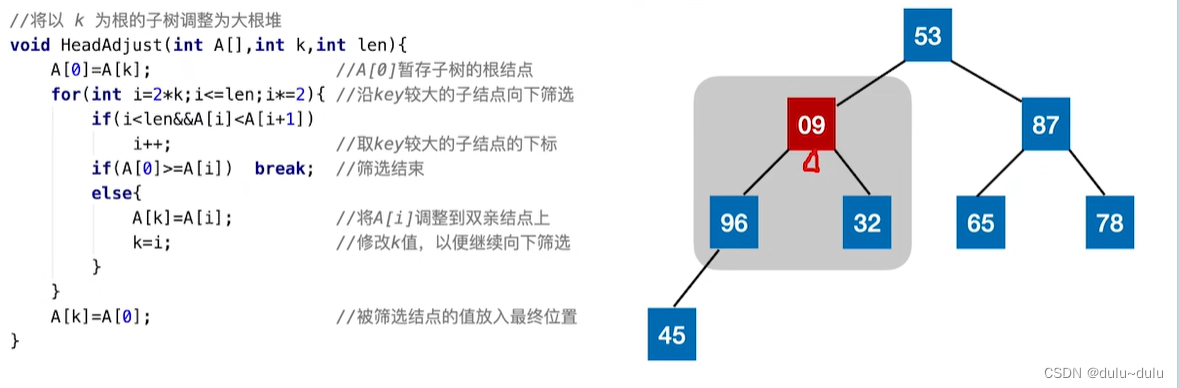
假设现在要调整09这个数据元素的位置:
① A[i]<A[i+1]:对比09的左,右孩子。
② A[0]>=A[i]: 将更大的孩子与09进行对比,若更大的孩子比09小,那么就不需要进行位置互换,否则就互换位置。
所以若一个结点有左,右两个孩子,那么他“下坠”一层,需要对比关键字2次。
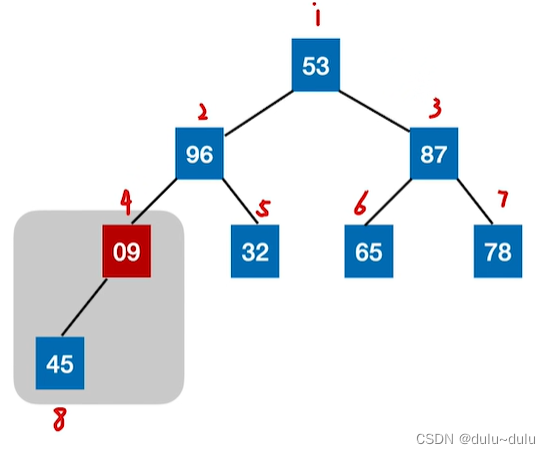
09下坠一次后,变为了4号位置的元素,那么其左孩子就是i=2*4=8号元素,当前这棵树有8个元素,所以不满足i<len,说明此时以4号位置元素为根节点的子树没有右孩子。
所以此时只需要进行1次关键字对比:
总结:
一个结点,每"下坠"一层,最多只需对比关键字2次。
若树高为h,某结点在第i层,则将这个结点向下调整最多只需要“下坠” h-i 层,关键字对比次数不超过 2(h-i)。而n个结点的完全二叉树树高h=
,第i层最多有
个结点,只有第1~h-1层的结点才有可能需要"下坠"调整。
第1层有1个结点,下坠调整次数为2(h-1);第2层有2个结点,下坠调整次数为2(h-2):
....=
将h=
由于:
所以:
结论:
建堆的过程,关键字对比次数不超过4n,建堆时间复杂度=O(n)
根节点最多“下坠” h-1 层,而每“下坠”一层,最多只需对比关键字2次,因此每一趟排序复杂度不超过 O(h) = O(
)。总共n-1趟,总的时间复杂度= O(
)。
堆排序的时间复杂度=O(n)+O(
)= O(
堆排序的空间复杂度=O(1)


堆排序算法稳定性:
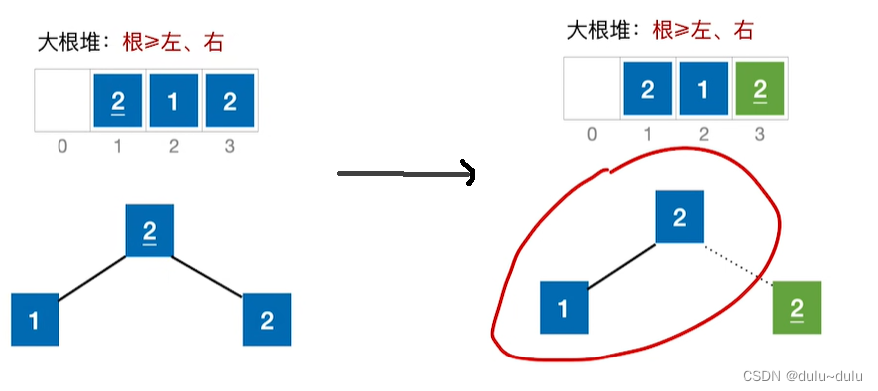
① 左右孩子都比根节点更大,代码的逻辑是A[i]<A[i+1],才将i++,表示右孩子>左孩子。所以左右孩子都相等时,会优先与左孩子进行交换。
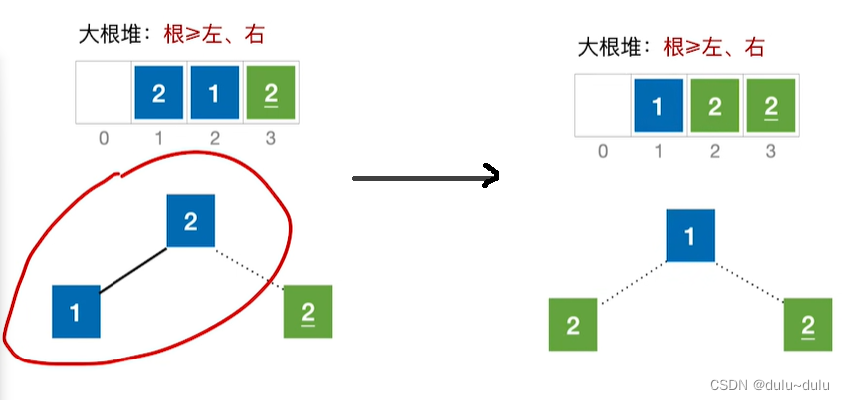
② 完成大根堆的建堆后,基于大根堆进行排序,将堆顶元素与堆低元素进行交换:
③ 剩余的待排序元素依然是一个大根堆,不需要调整,直接将堆低元素和堆低元素进行互换:
完成2次排序(3-1趟排序)后,初始序列和排序结果中,两个"2"的前后位置互换,所以堆排序不稳定。

3.堆的插入和删除
考试中会考察:堆的插入和删除的次数。
•在堆中插入新元素
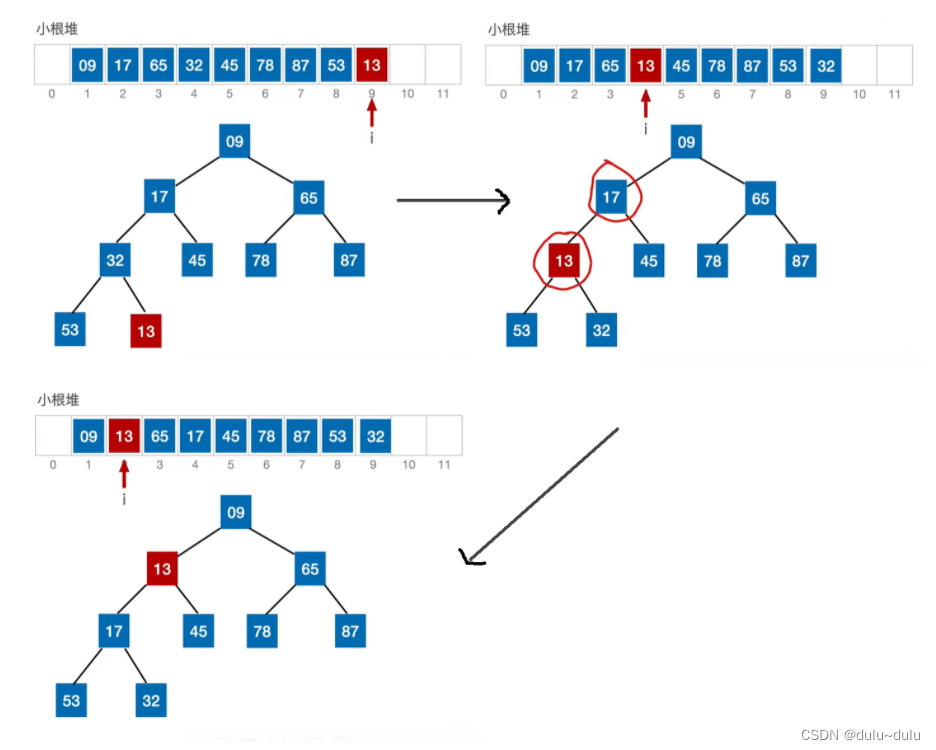
拿小根堆举例,假设插入的元素是13,那么新插入的元素会先放在表尾的位置。
将其与父节点对比,若新元素比父节点()更小,则将二者互换。新元素就这样一路“上升”,直到无法继续上升为止。
第1次,12与32进行对比;第2次,13与17进行对比;第3次,13与9进行对比。总共进行了3次对比。
#define MAX_HEAP_SIZE 100
void swap(int &a, int &b) { int temp = a; a = b; b = temp;
} minHeapInsert(int A[],int &len,int k){if(len>MAX_HEAP_SIZE - 1){return;} // 插入新元素到数组的末尾 A[++len] = k; // 上滤操作,从插入位置开始 int currentIndex = len; while (currentIndex >1 && A[currentIndex] < A[currentIndex/2]) { // 交换当前元素和它的父节点 int parentIndex = currentIndex/2; swap(A[currentIndex], A[parentIndex]); currentIndex = parentIndex; }
} •在堆中删除元素
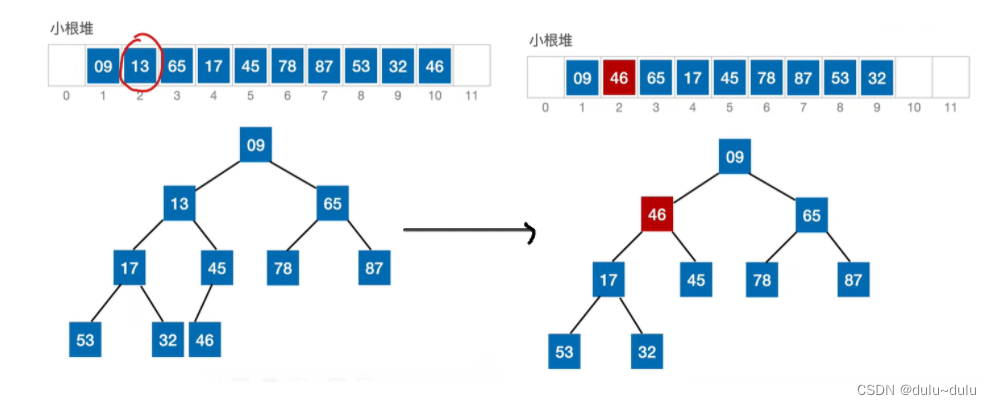
依旧拿小根堆举例,假设此时要删除的元素是13。删除13后,被删除的元素的用堆底元素替代,然后让该元素不断“下坠”,直到无法下坠为止。
最终结果如下,首先① 17(左孩子,2i)与45(右孩子,2i+1)对比,从中选出更小的关键字17;② 再将46与17进行对比,46>17,46与17位置互换;③ 53与32进行对比,选出更小的关键字32;④ 再将46与32进行对比,46>32,两个数据元素位置互换。至此完成小根堆的建立,对比关键字的次数为4次。
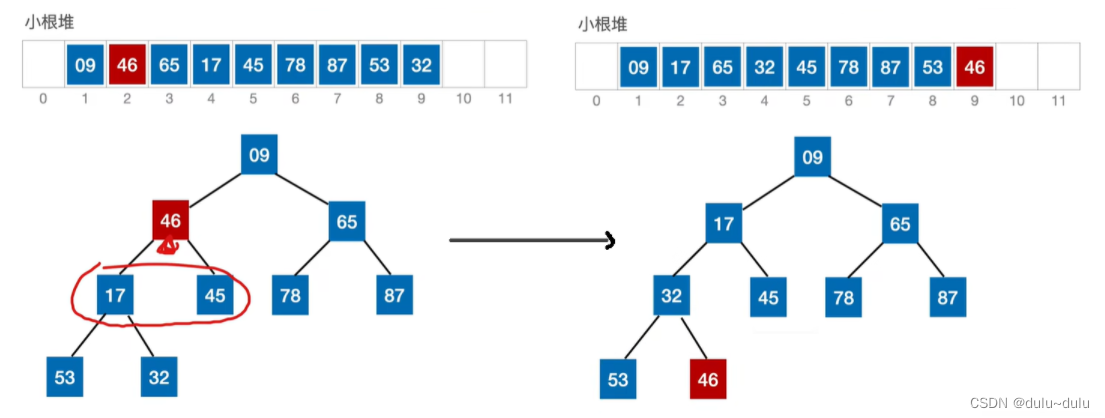
所以如果某个根节点下方有2个孩子,则“下坠”一层,需要对比关键字2次;如果某个根节点下方有1个,则只需要对比关键字1次。
void swap(int &a, int &b) { int temp = a; a = b; b = temp;
} void minHeapDelete(int A[], int k, int &len) {if (k<1||k>len) { return; }if (k=len){len--;return;}// 将最后一个元素移动到被删除元素的位置 A[k] = A[len]; len--; // 减少堆的大小 // 堆调整从被删除元素的位置开始 int i = k; int leftChild =2*i; // 如果当前节点有子节点,并且子节点比它小,就交换 while (leftChild<=len) { int smallChild = leftChild; int rightChild = leftChild + 1; // 找出较小的子节点 if (rightChild<=len && A[rightChild]<A[leftChild]) { smallChild = rightChild; } // 如果较小的子节点比父节点小,就交换 if (A[smallChild]<A[i]) { swap(A[smallChild], A[i]); i=smallChild; leftChild = 2*i; } else { // 如果没有更小的子节点,那么堆已经满足条件 break; } }
}二.归并排序
归并排序就是把两个或多个已经有序的序列合并成一个:
如下图所示,有2个有序序列:
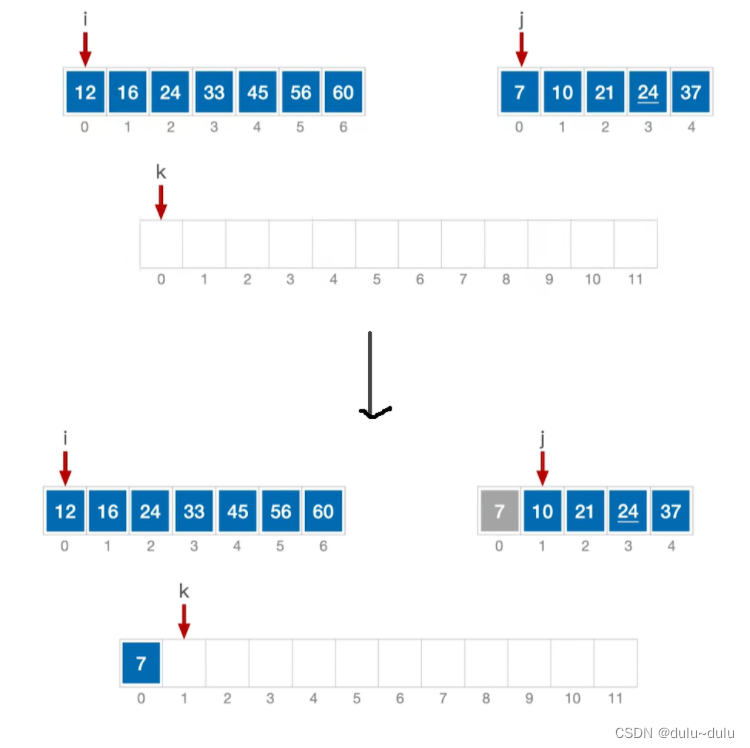
① 对比i和j指向的元素,更小的一个放入k所指得位置。如下图所示,j所指的元素更小,所以将7放入k[0],并且k,j往后移:
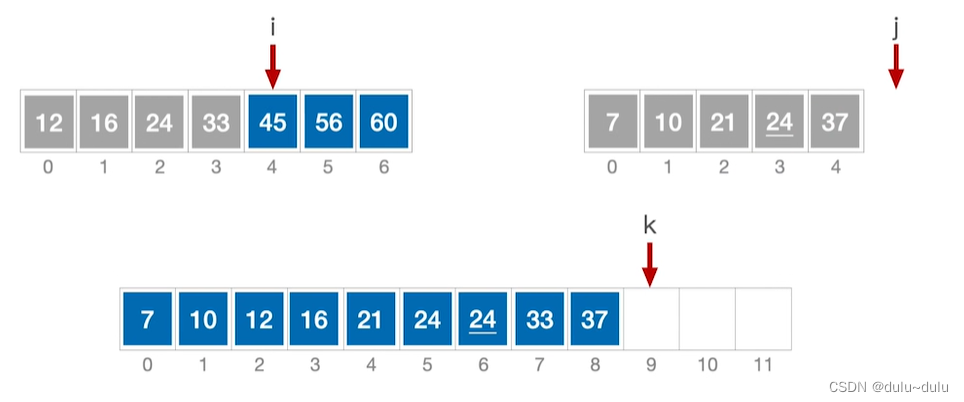
② 重复以上操作,对比i,j,并将更小的数据元素放到k所指位置。当 j 指针超出了原来数组的下标范围,只有左边数组没有合并完,所以将表中的剩余元素全部加到总表中。
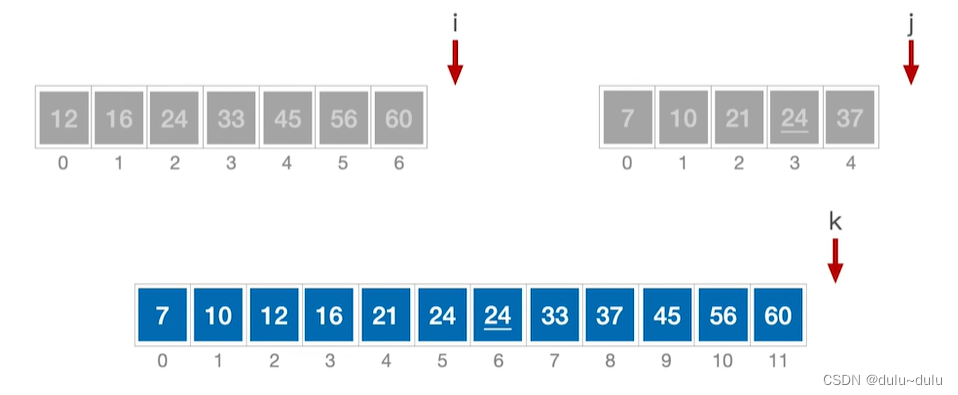
最后k表如下图所示:
这个过程也叫做“二路归并”,就是将2个有序序列合二为一,每选出一个更小的数据元素,只需要对比关键字1次。
同理,“4路”归并,就是将4个有序序列合为一个有序序列,每选出一个更小的元素就需要对比关键字3次。
结论:m路归并,每选出一个元素,需要对比关键字m-1次。

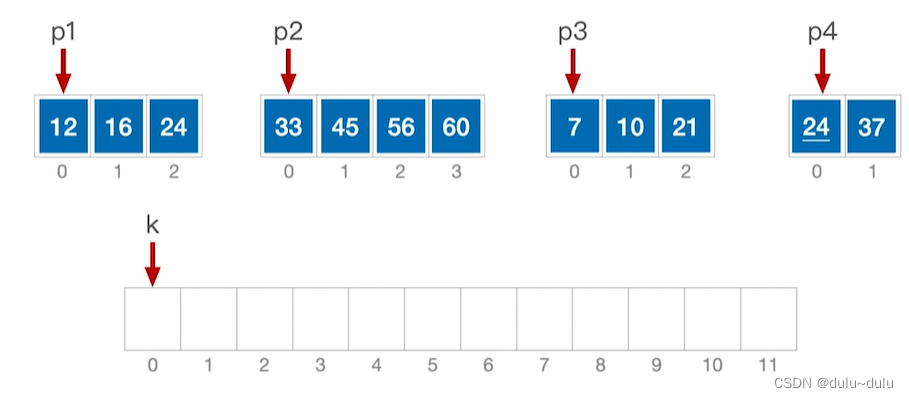
对一个初始序列进行归并排序的操作如下,内部排序一般采用的是2路归并,所以这里采用2路归并:
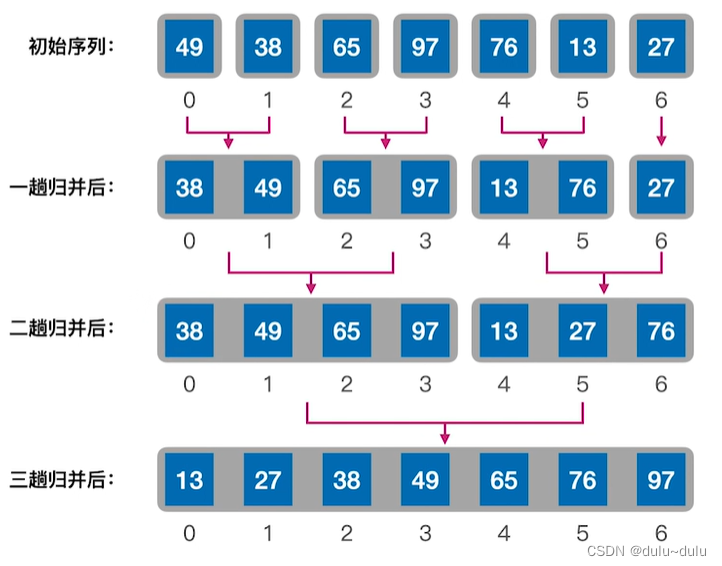
归并的实现如下:
int *B=(int *)malloc(n*sizeof(int)); //辅助数组B//A[low....mid] 和 A[mid+1..high]各自有序,将两个部分归并
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low; k<=high; k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){if(B[i]<=B[j]) //两个元素相等时,优先使用考前的那个,可以保证算法的稳定性A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++];}//forwhile(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
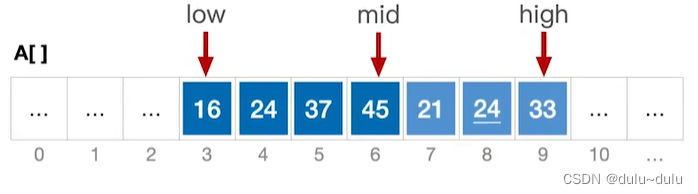
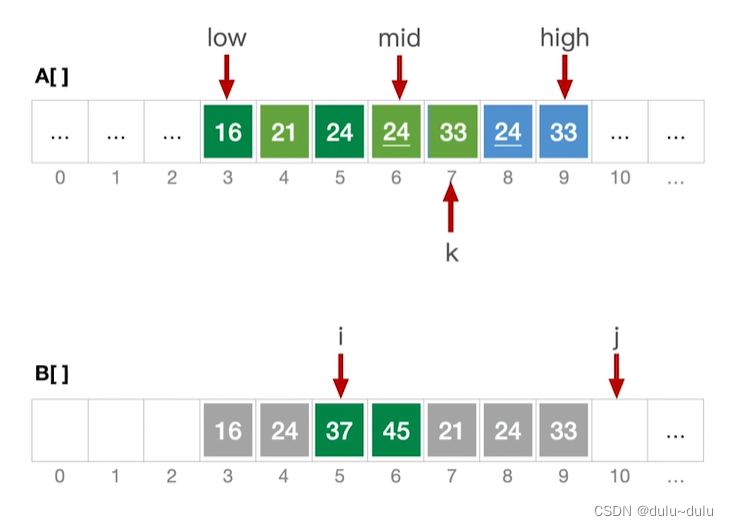
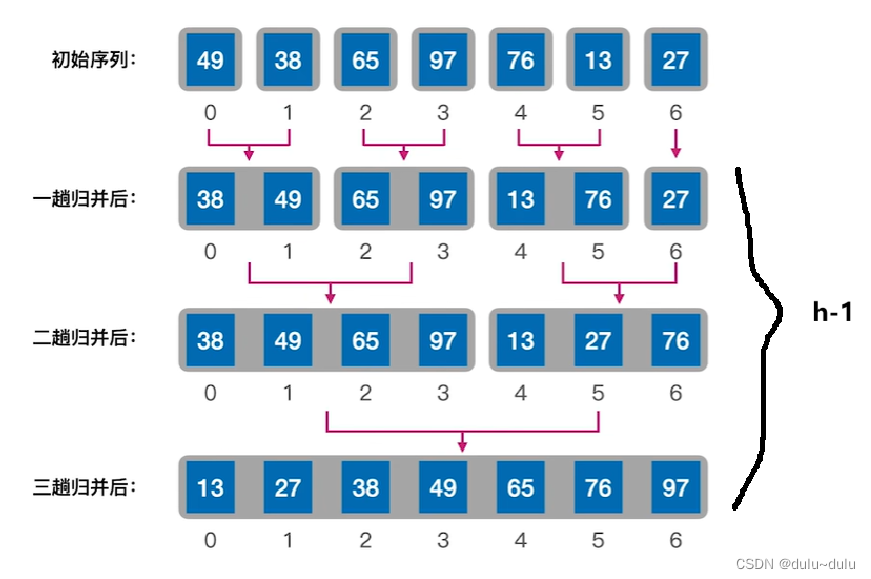
}如下图,是一个数组A,3~6是一个有序序列,7~8是一个有序序列。
用low指针指向第1个有序序列的第1个元素,用mid指针指向第1个有序序列的最后1个元素。high指针指向第2个有序序列的最后1个元素。
① 设置辅助数组B,将A数组的元素复制到数组B中:
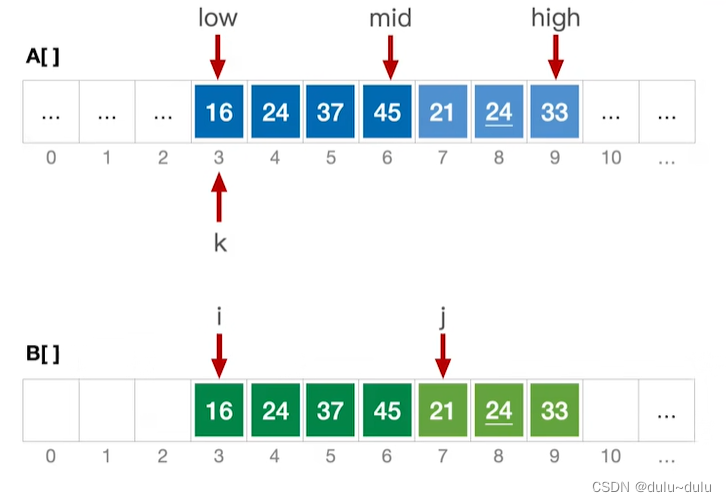
② 比较B[i]和B[j]元素的大小,将较小的元素复制到k所指的位置,k++:
③ 以此类推,当j>high时,不满足j
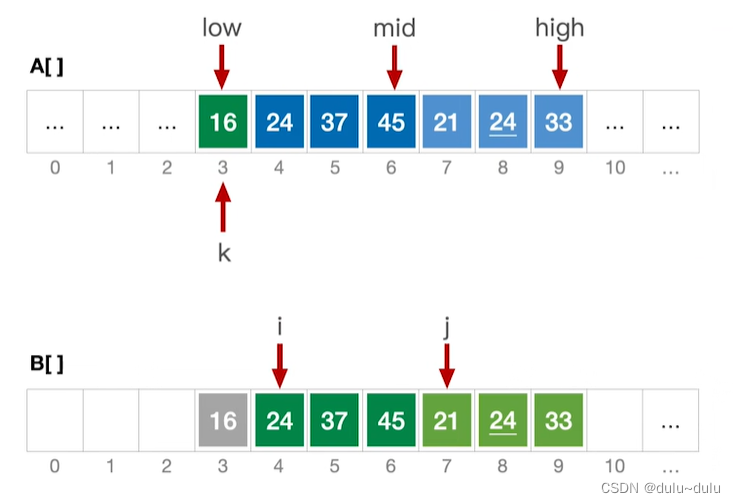
high的条件,跳出for循环。用while分别检查i,j两个序列是否已经合并完,没有合并完的子序列直接合并到A中即可。
合并完成后,i指向mid+1,j指向high+1。
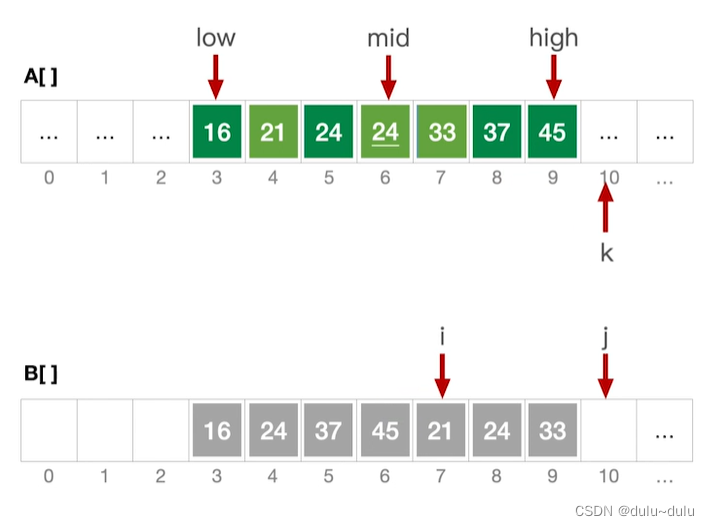
整体代码:
int *B=(int *)malloc(n*sizeof(int)); //辅助数组B//A[low....mid] 和 A[mid+1..high]各自有序,将两个部分归并
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low; k<=high; k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){if(B[i]<=B[j]) //两个元素相等时,优先将前面子序列的那个元素放到A中,可以保证算法的稳定性A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++];}//forwhile(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
}void Mergesort(int A[],int low,int high){if(low<high){int mid=(low+high)/2; //从中间划分MergeSort(A,low,mid); //对左半部分归并排序MergeSort(A,mid+1,high); //对右半部分归并排序Merge(A,low,mid,high); //归并}//if
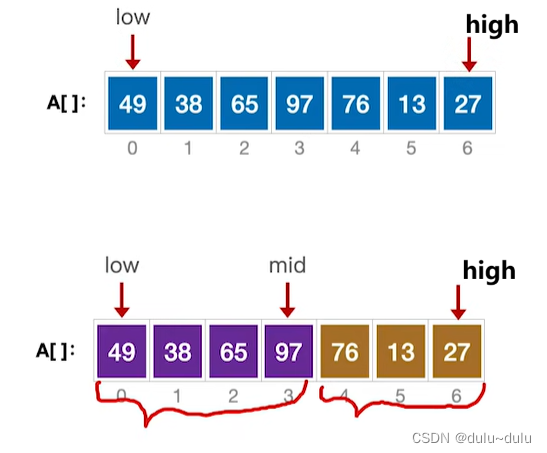
}① 将初始序列分为左半部分序列和右半部分序列:
② 并用MergeSort分别对左半部分序列和右半部分序列递归进行归并排序:
MergeSort(A,low,mid);
MergeSort(A,mid+1,high);
③ 左右都进行归并排序后,左右两个子序列都变为有序,再将左右子序列归并即可:
Merge(A,low,mid,high);
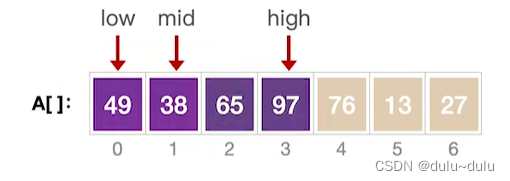
以左子序列的递归为例:
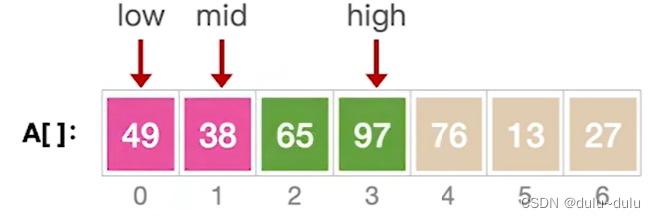
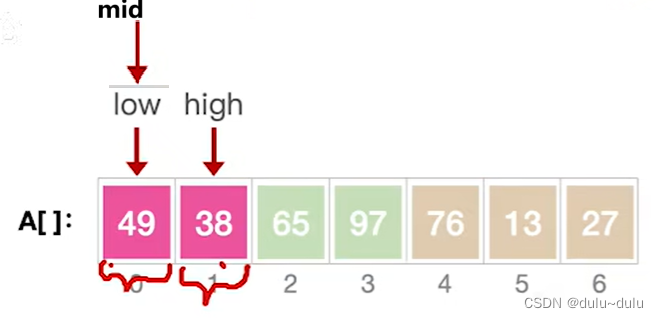
第一层:MergeSort(A,low,mid);此时low=0,high=3:
第二层:MergeSort(A,low,mid);此时low=0,high=1:
第三层:由于low<high,所以继续向下进行拆分。每个子序列只有一个元素,所以MergeSort不会做任何操作:
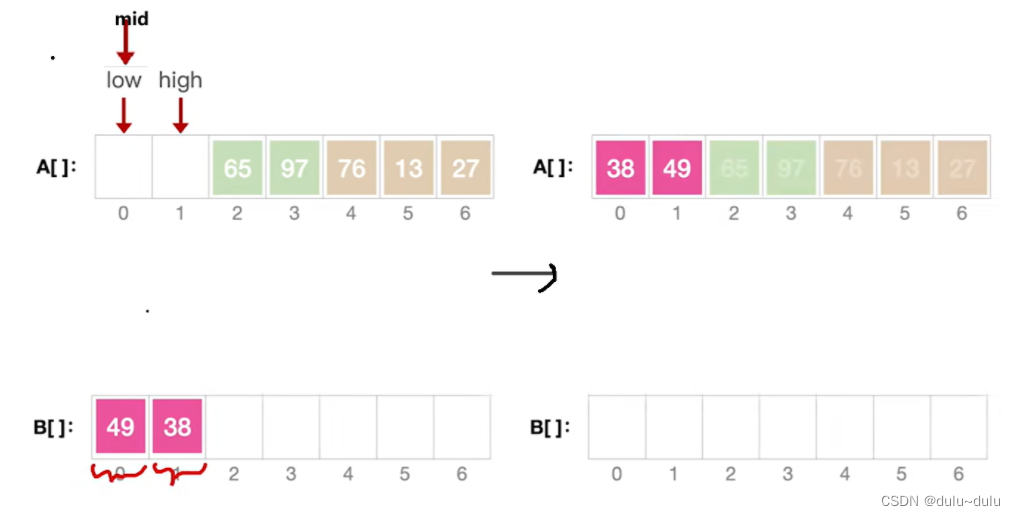
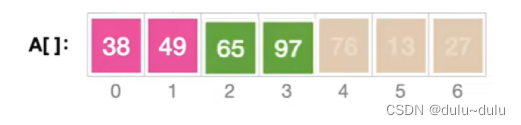
递归完成,继续执行Merge:
将要处理的左右子序列放到B数组中,归并两个有序序列后再放回A数组:
以此类推,再回到上一层的归并排序,对第二层的右子序列进行归并排序:
归并排序算法效率:
时间复杂度:
2路归并的“归并树”----形态上就是一棵倒立的二叉树。二叉树的第h层最多有个结点,若树高为h,则第h层的结点数n<=
个,也就是
。
又因为h-1刚好等于归并排序的躺输,所以:
n个元素进行2路归并排序,归并趟数=。
每趟归并时间复杂度为 O(n),则算法时间复杂度为
为什么每趟归并时间复杂度为O(n):
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low; k<=high; k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){if(B[i]<=B[j]) //两个元素相等时,优先将前面子序列的那个元素放到A中,可以保证算法的稳定性A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++];}//forwhile(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
}每一次对比 i,j 都能从中挑出1个更小的元素放到数组A中。最终将2张表合二为一,需要的关键字对比次数不会超过n-1,所以归并的时间复杂度为O(n)
空间复杂度:
空间复杂度为O(n),来自于辅助数组B(和存放数据元素的数组A是同样的大小n),其实归并排序所用到的递归工作栈也算到了里面。因为递归排序的趟数,也就是栈的深度不会
所以取更高阶的数量级,也就是辅助数组B带来的O(n)的空间。
归并排序算法的稳定性:
由于在代码中采用B[i]<=B[j],所以当两个元素相等时,优先将前面子序列的那个元素放到A中,可以保证算法的稳定性。所以归并排序是稳定的算法。
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low; k<=high; k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<=mid&&j<=high;k++){if(B[i]<=B[j]) A[k]=B[i++]; elseA[k]=B[j++];}//forwhile(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
}三.基数排序
之前的排序,都是以各个关键字值的大小作为排序的依据,而基数排序中排序的依据有所不同:
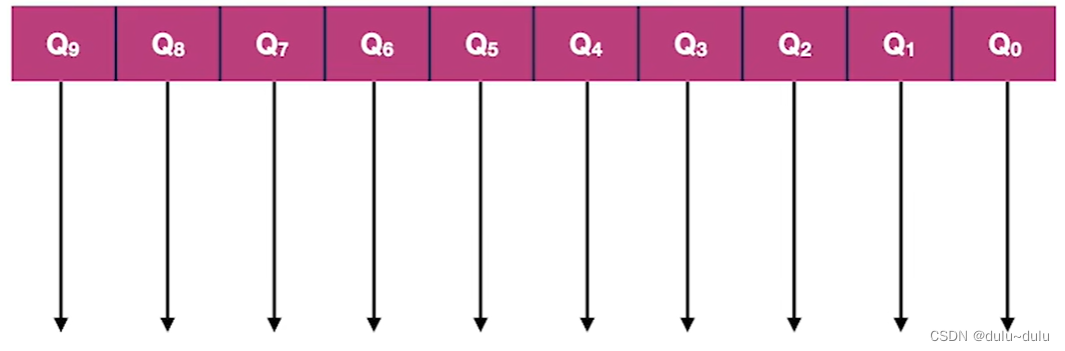
每一个关键字的值都有"个,十,百"位构成,每一位的取值范围都是0~9。所以,可以建立10个辅助队列,分别对应每一位取值的情况:
假设现在想得到递减的序列:
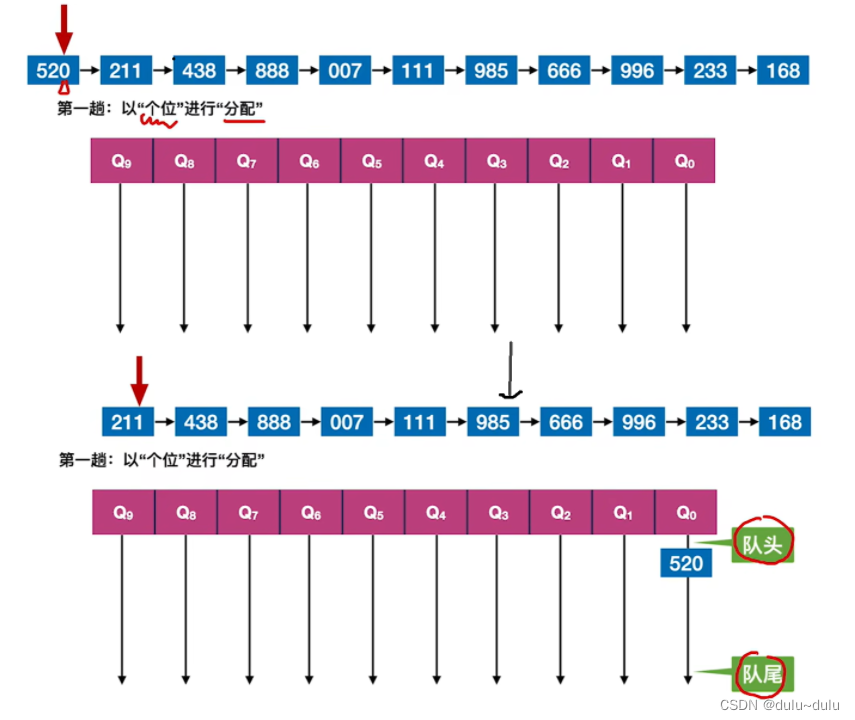
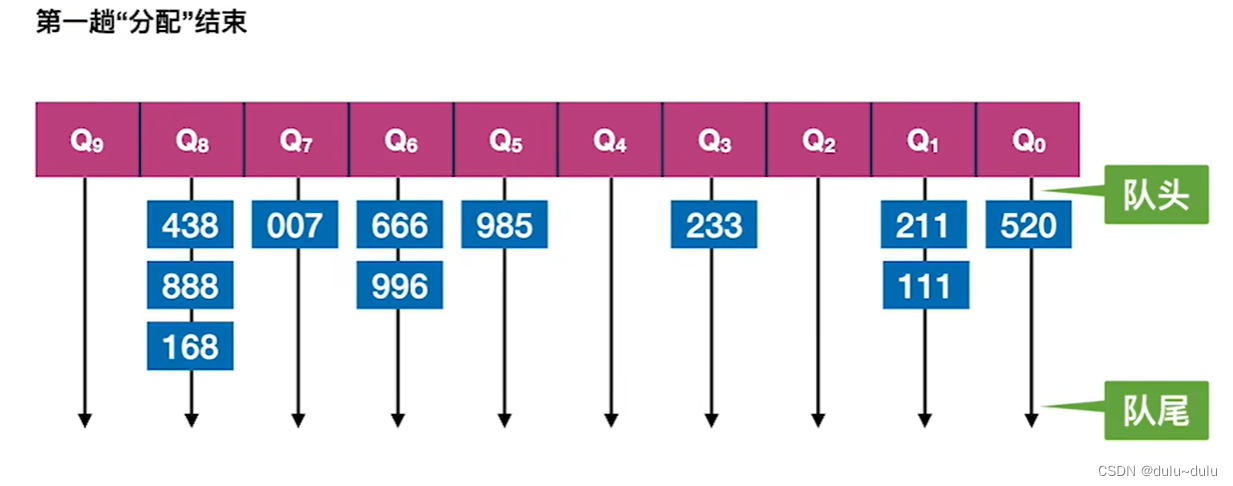
① 第一趟的处理中会以“个位”进行“分配”:
第一个元素的“个位”是0,所以将其放到0对应的辅助队列。
以此类推,得到的10个辅助队列的情况如下:
进行数据元素的“收集”,由于最终想要得到递减的序列,所以从“个位”值更大的队列开始收集,也就是“9”开始收集:
最终会得到按照“个位”递减的序列。
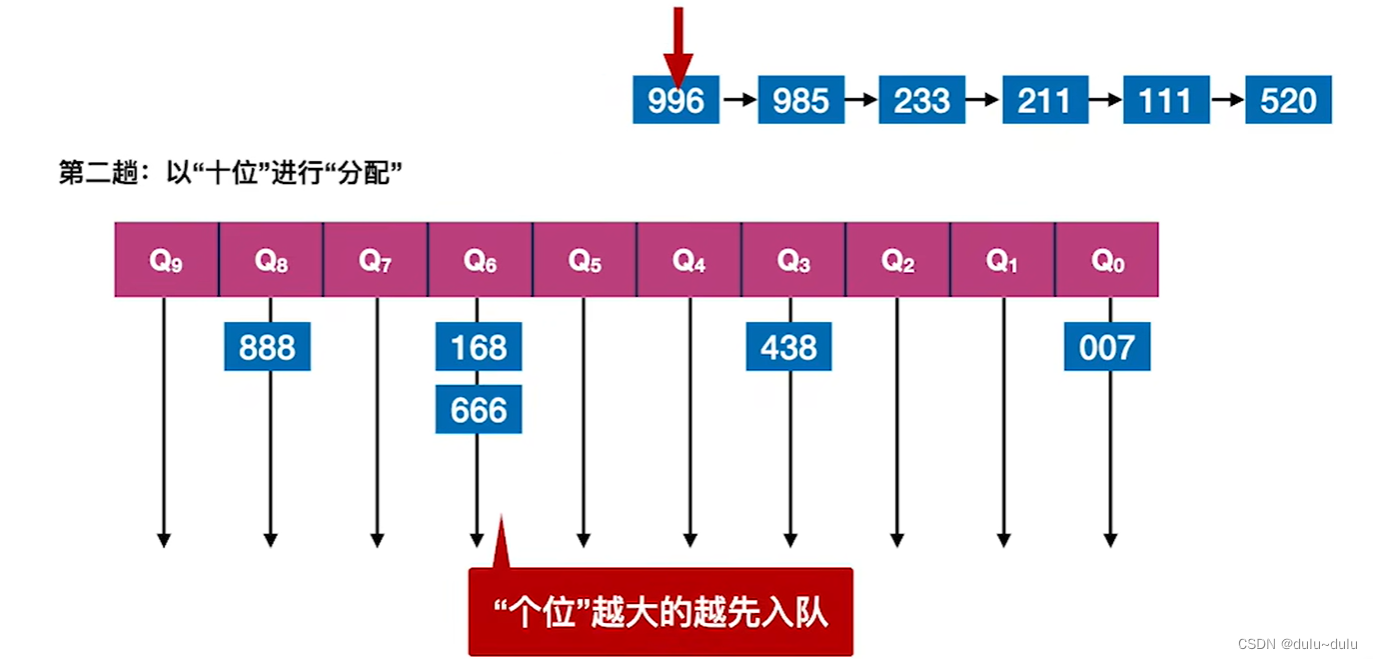
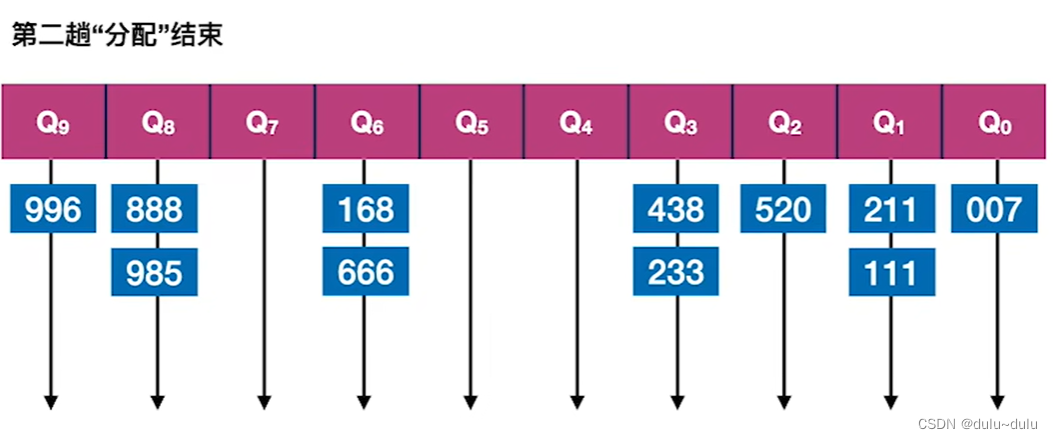
②第二趟的处理会基于第一趟的排序序列进行。第二趟以“十位”进行“分配” ,分配结果如下:
由排序的结果可知,当"十位"相同时,"个位"越大的越先入队,这是因为第二趟的“分配”工作是基于第一趟的排序序列进行的。而第一趟的处理中,"个位"数值越大的会排在前面。
进行第二趟的“收集”工作,方法和第一趟的“收集”一样,从"十位"更大的队列依次往后收集,这就能保证"十位"更大的数排在前面:
按第二趟“收集”后,会得到按“十位”递减排序的序列,“十位”相同的按“个位”递减排序。
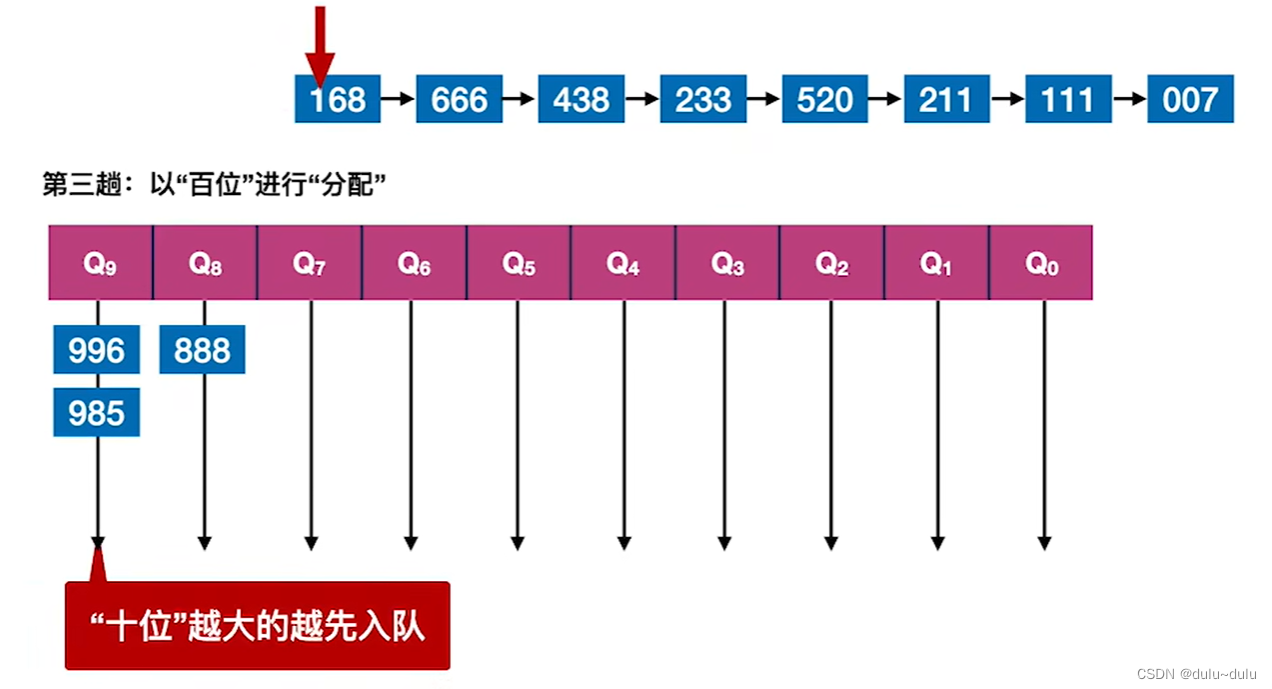
③第三趟的处理会以"百位"进行"分配":
同理,由于这一趟的分配是基于第二趟处理得到的序列,所以如果2个数值"百位"相同,那么他们中"十位"越大的越先入队。
第三趟分配结果如下:
接下来继续进行第三趟的"收集":
第三趟按“百位”分配、收集后,得到一个按“百位”递减排列的序列,若“百位”相同则按“十位”递减排列,若“十位”还相同则按“个位”递减排列。这样就可得到一个递减的有序序列。




总结一下:
假设长度为 n 的线性表中每个结点的关键字由d元组
组成。
其中,0 ≤ ≤ r-1(0≤j<n, 0 ≤ i ≤ d -1),r称为“基数”。在上面的例子中
的范围是0~9,r为10。每个关键字有10种不同的取值。
这里的被称为最高为关键字(最主位关键字),
被称为最低位关键字(最次位关键字),在上面的例子中,最高位关键字就是"百位",最低位关键字就是"个位"。因为"百位"关键字的数值是对整个关键字数值影响最大的,而"个位"对整个关键字的数值影响是最小的。
基数排序得到递减序列的过程如下:
初始化:设置r个空队列,
按照各个 关键字位 权重递增的次序(个、十、百),对 d 个关键字位分别做“分配”和“收集。
分配:顺序扫描各个元素,若当前处理的关键字位=x,则将元素插入
队尾。
收集:把
各个队列中的结点依次出队并链接。
基数排序得到递增序列的过程如下:
初始化:设置r个空队列,
按照各个 关键字位 权重递增的次序(个、十、百),对 d 个关键字位分别做“分配”和“收集。
分配:顺序扫描各个元素,若当前处理的关键字位=x,则将元素插入
收集:把
各个队列中的结点依次出队并链接。
只是收集的顺序不同,递增序列的收集是从这一位值更小的队列开始收集。
基数排序的算法效率:
常用链式存储结构实现基数排序算法。
如下图所示,初始序列用单链表表示,而表示0~9数值的队列用链式队列实现:
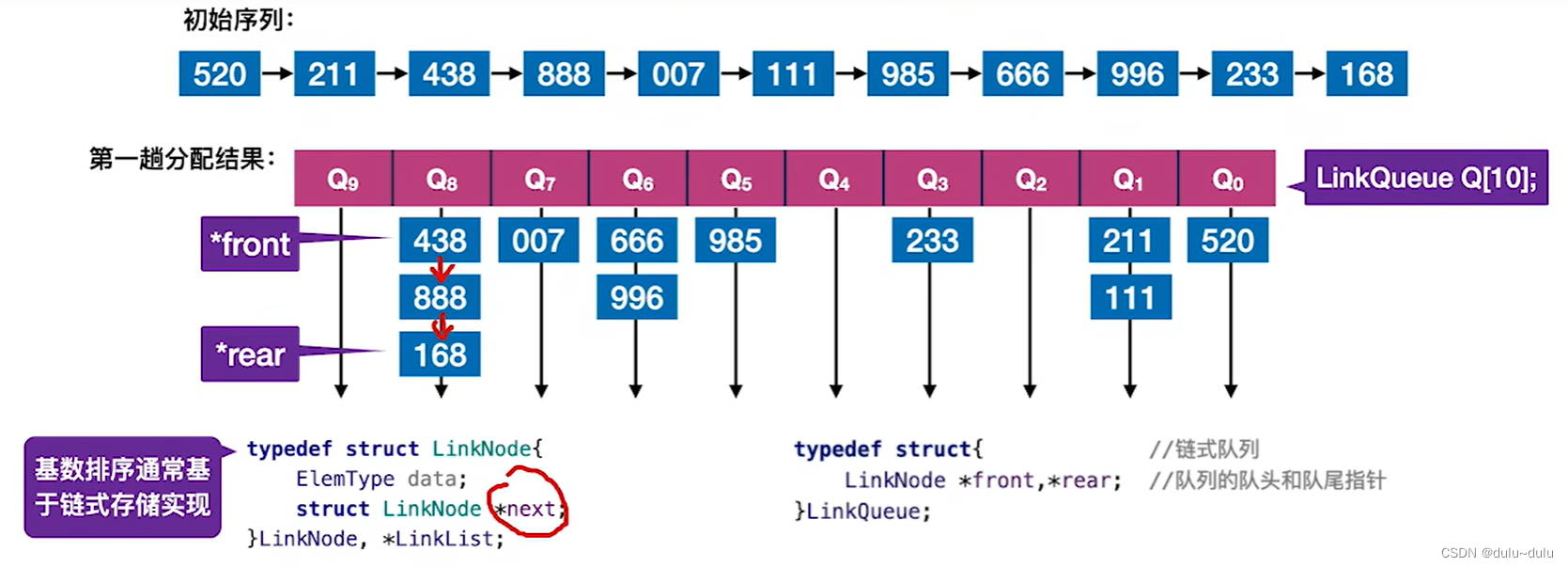
空间复杂度:
由于需要r个辅助队列,所以空间复杂度为O(r)。在上面的例子中,每一位的取值都为0~9,所以r(基数)=10。需要10个辅助队列。
时间复杂度:
一趟分配O(n):从头到尾依次扫描序列中的数据元素。总共n个元素,扫描n个元素时间复杂度为O(n)。
一趟收集O(r):总共r(每个"位"可能取得r个值)个队列,每一次收集就是将每个队列的元素合并起来。每个队列合并的时间复杂度为O(1)。为什么?
p->next=Q[5].front;
Q[5].front=NULL;
Q[5].rear=NULL;
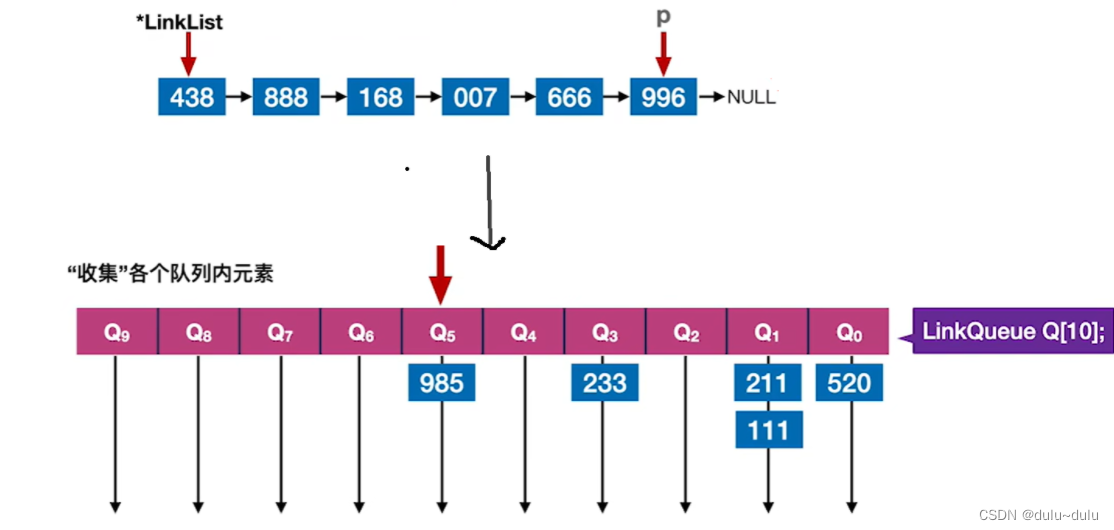
r个队列合并的时间复杂度为O(r)。
总共 d 趟(若关键字位有3位,那么总共需要3趟收集,分配)分配、收集,总的时间复杂度=O(d(n+r))
基数排序算法的稳定性:
某个初始序列中有2个“12”,分配时是从左往右依次扫描序列,所以在队列中第一个"12"会在第二个"12"的前面,所以,将队列的元素收集起来时,第一个“12”也会在前面:
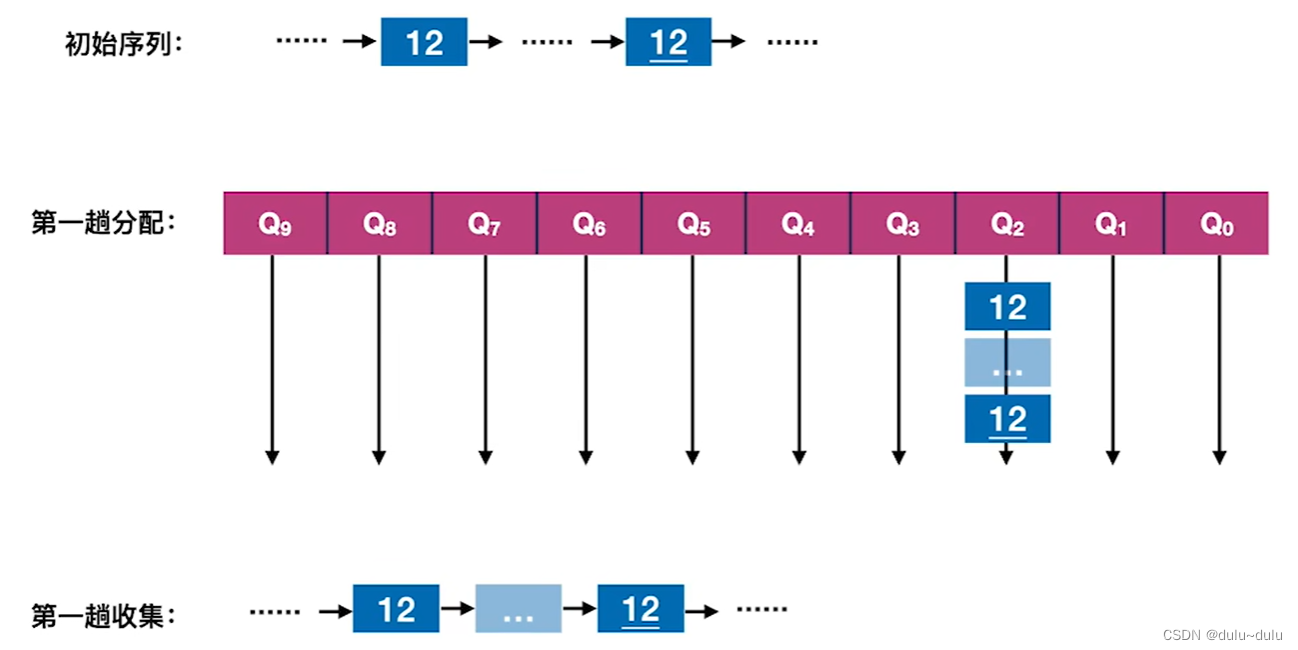
所以基数排序算法是稳定的。
基数排序的应用:
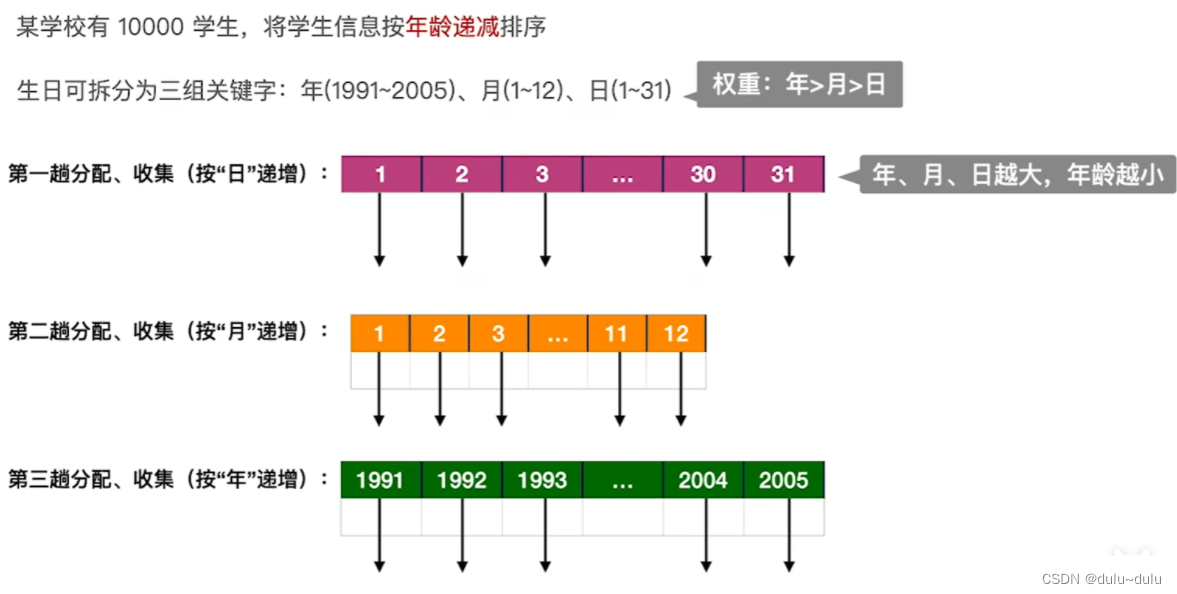
基数排序,时间复杂度=O(d(n+r)),上述例子的d=3(年,月,日),n=10000(10000个学生),r=31(第1轮r=31,第2轮r=12,第3轮r=15,这里取最大),所以:

基数排序擅长解决的问题:
① 数据元素的关键字可以方便地拆分为 d组,且 d 较小。
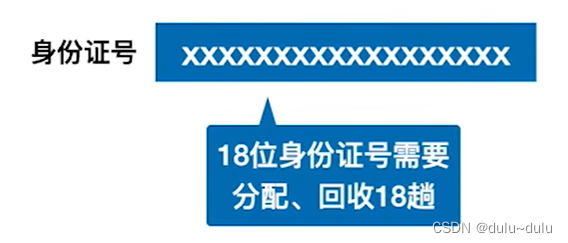
反例:若给5个人的身份证号排序:
这样效率非常低。
② 每组关键字的取值范围不大,即 r 较小。
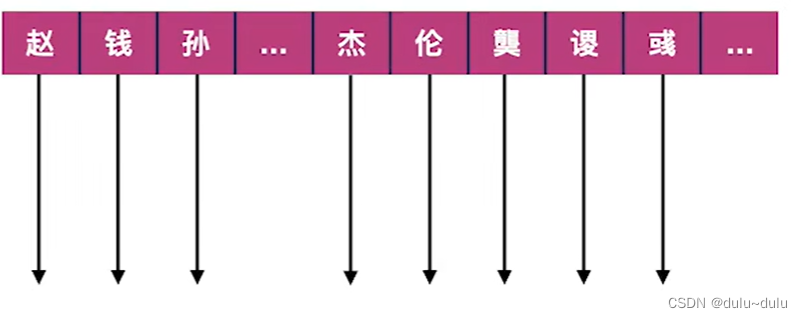
反例:若给中文人名排序,每个分组能取的值太多(r取值范围大)。
③ 数据元素个数 n 较大。
若给十亿人的身份证号排序,虽然身份证号有18位,会进行19趟的分配和回收,但是由于n的数较大,所以时间效率其实比O(n^2),O(