GenAI-contest/01-LLM_Fine-tuning at main · amd/GenAI-contest (github.com)
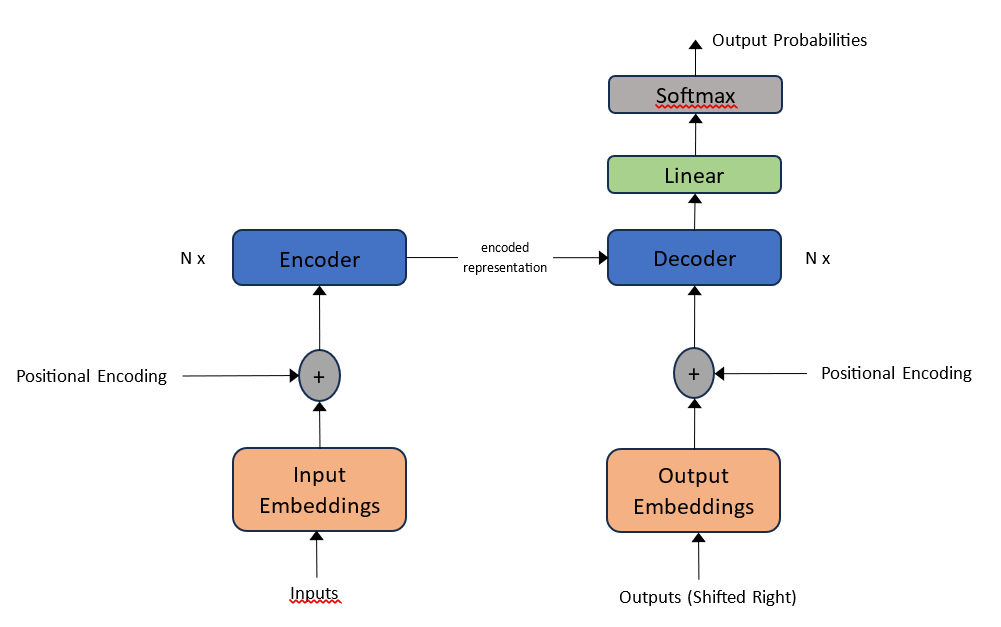
大型语言模型(LLMs)在大量的文本数据上进行训练。因此,它们能够生成连贯且流畅的文本。Transformer架构是所有LLMs的基础构建块,它作为底层架构,使LLMs能够通过捕捉上下文关系和长距离依赖来理解并生成文本。为了更好地理解Transformer架构的哲学,建议阅读论文《Attention is All You Need》。Transformer架构的简化版本大致如下:
微调可以让原始的大型语言模型更好地适应特定应用场景,从而在众多任务上取得更优的结果。从宏观层面来讲,微调过程主要包括以下三个步骤:
-
准备训练数据集:根据目标应用场景,收集或构建相关的训练数据。这些数据应该反映希望模型学习的特定领域知识或语言风格。数据集可以是标注过的(例如,带有分类标签的文本),也可以是未标注的,具体取决于微调任务的性质。
-
训练微调模型:使用准备好的数据集,在原始大型语言模型的基础上进行微调训练。这个过程涉及调整模型的内部参数,以便模型能够更好地理解和生成符合特定任务要求的文本。微调时可能会用到梯度下降等优化算法,以及对学习率、批次大小等超参数的调整。
-
部署并使用微调后的模型:训练完成后,将微调过的模型部署到实际应用环境中。这可能包括集成到现有的软件系统、Web服务或是开发新的应用程序中。用户或开发者可以通过API调用等方式,利用该模型进行预测、生成文本或执行其他语言处理任务,从而在特定场景下获得比通用模型更佳的性能表现。
总之,微调是通过针对具体任务定制化训练,优化大型语言模型的一种手段,旨在提升模型在特定领域的准确性和实用性。
在配备AMD Radeon GPU卡的PC上工作,可能需要先通过命令安装PyTorch。

安装依赖
下一步,需要安装一系列的Python库,包括但不限于Hugging Face的Transformers库、数据集处理库、加速库等,以及为了进行特定任务的训练和优化,还需要安装TRL、PEFT(参数高效的微调方法)和bitsandbytes-rocm(针对ROCm GPU优化的库)。
pip install transformers
pip install datasets
pip install accelerate
pip install huggingface
pip install huggingface-hub
pip install scipypip install trl # 为了使用最近的SFTTrainerpip install peft # 为了使用PEFT进行高效模型微调# 针对ROCm GPU安装bitsandbytes
git clone https://github.com/Lzy17/bitsandbytes-rocm
cd bitsandbytes-rocm
make hip
sudo python3 setup.py install确保能够在一个支持ROCm环境的系统上顺利进行深度学习相关的开发和实验。
模型和数据集
下载 facebook/opt-1.3b 模型和 mlabonne/guanaco-llama2-1k dataset 数据集:
export HF_ENDPOINT=https://hf-mirror.com
./hfd.sh facebook/opt-1.3b --tool aria2c -x 4
./hfd.sh mlabonne/guanaco-llama2-1k --dataset --tool aria2c -x 4

使用自定义数据集微调LLM模型
将展示如何使用facebook/opt-1.3b模型,并结合mlabonne/guanaco-llama2-1k数据集进行微调。
克隆脚本
首先,克隆含有微调示例脚本的仓库:
git clone https://github.com/amd/GenAI-contest.git
cd GenAI-contest/01-LLM_Fine-tuning微调模型
接下来,设置模型ID并执行微调脚本。
export MODEL_ID="../opt-1.3b"
CUDA_VISIBLE_DEVICES=0 python3 llm_finetuning_and_inference.py --model-id=$MODEL_ID
测试微调后的模型
要测试微调后的模型,请执行以下命令:
CUDA_VISIBLE_DEVICES=0 python3 llm_finetuning_and_inference.py --model-id=$MODEL_ID --inference