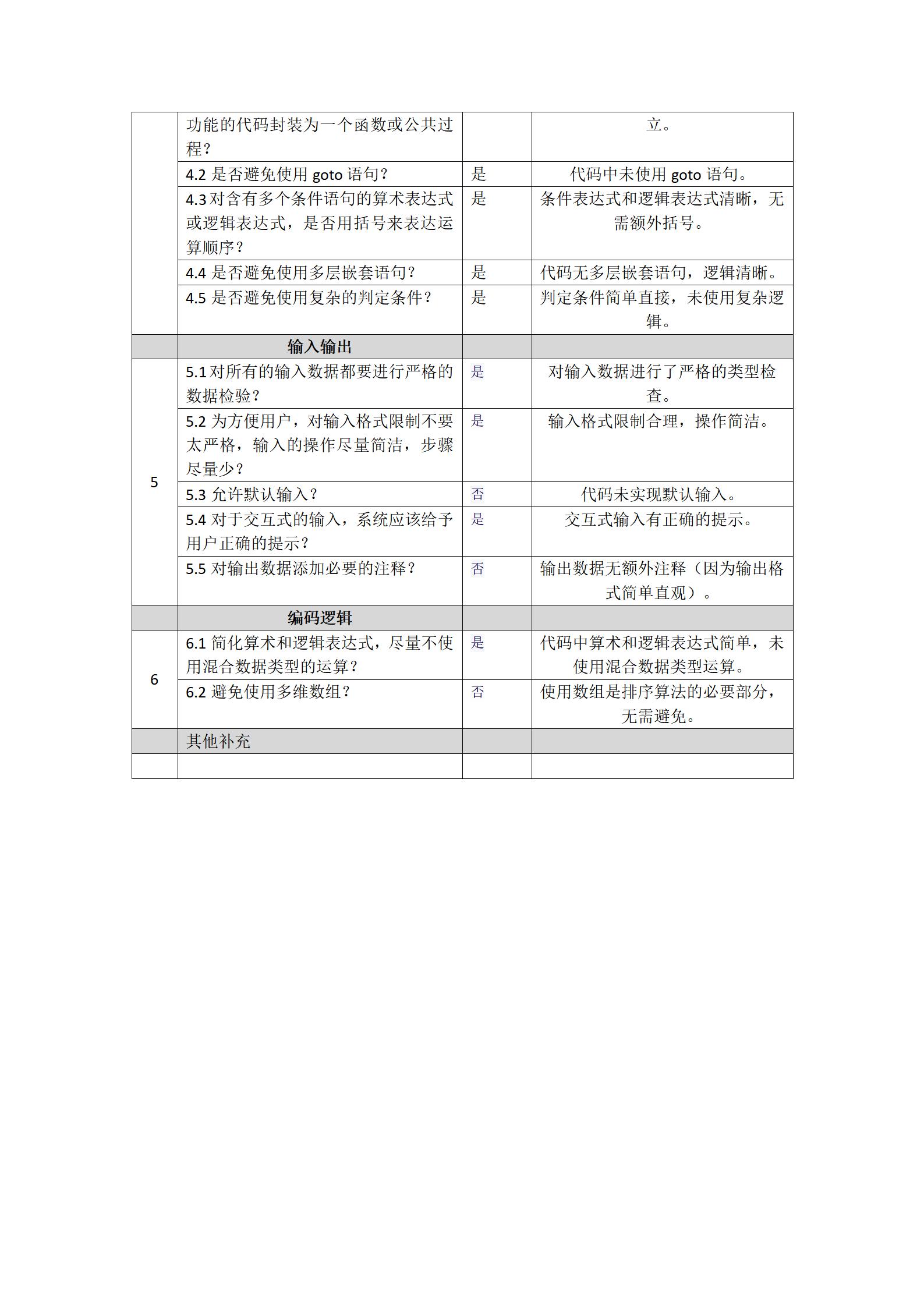
一、安装Xpath解析库-scrapy中的selector
win+r打开cmd,输入pip install wheel,先安装wheel库了才能安装.whl文件。

安装lxml库
到https://pypi.org/project/lxml/#files下载对应python版本的lxml库

切到lxml下载位置,安装lxml


安装Twisted库
到https://pypi.org/project/Twisted/#files下载对应python版本的Twisted库

切到Twisted下载位置,安装Twisted


安装scrapy库
到https://pypi.org/project/Scrapy/#files下载对应python版本的scrapy库


安装完成之后,将pycharm的环境切到python_spider之前创建的虚拟环境中

二、Xpath
xpath使用路径表达式在xml和html中进行导航,xpath包含标准函数库,xpath是一个w3c的标准。
xpath的节点关系(1)父节点(2)子节点(3)同胞节点(4)先辈节点(5)后代节点
Xpath语法



同一个元素可能会存在多种xpath的语法,xpath可以直接获取到值
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
print(sel)
tag1=sel.xpath("//*[@id='info']/div/p[1]")
print("tag1:"+str(tag1))
#取出info的text
tag2=sel.xpath("//*[@id='info']/div[1]/p[1]/text()").extract()[0]
if tag2:print("tag2:"+str(tag2))
#获取第一个div的p节点的值
tag3=sel.xpath("//div[1]/div[1]/p[1]/text()").extract()[0]
print("tag3:"+str(tag3))
tag4=sel.xpath("//div[1]/div/p[1]/text()").extract()[0]
print("tag4:"+str(tag4))
输出结果:


输出年龄:29
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
name_xpath="//div[1]/div/p[1]/text()"
name=""
tag_texts=sel.xpath(name_xpath).extract()
if tag_texts:name=tag_texts[0]
print(name)
输出结果:

通过class属性xpath找值
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
teacher_tag=sel.xpath('//div[@class="teacher_info"]/p[2]').extract()
print(teacher_tag)
输出结果:

如果是标签之中含有多个class ,可以使用contains方法获取
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
teacher_tag=sel.xpath('//p[contains(@class,"bobbyname")]').extract_first()
print(teacher_tag)
输出结果:

在这个网站上存在着很多类似contains的内置方法
https://developer.mozilla.org/en-US/docs/Web/XPath/Functions
使用last()函数获取最后一个元素的值
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
info1=sel.xpath('//div[contains(@class,"teacher")]/p[last()]/text()').extract_first()
print(info1)
info2=sel.xpath('//div[contains(@class,"teacher")]/p[last()-1]/text()').extract_first()
print(info2)
输出结果:

获取class属性值
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
class_value=sel.xpath('//div[contains(@class,"teacher")]/p[last()-1]/@class').extract_first()
print(class_value)
输出结果:

同时获取两个属性值
from scrapy import Selectorhtml="""
<html lang="en">
<head><meta charset="UTF-8"><title>bobby基本信息</title><script src="jquery-3.5.1.min.js"></script>
</head>
<body><div id="info"><p style="color: blue">讲师信息</p><div class="teacher_info">Python全栈工程师<p class="age">年龄:29</p><p class="name bobbyname" data-bind="bobby">姓名:bobby</p><p class="work_years">工作年限:7年</p><p class="position">职位:python开发工程师</p></div><p style="color:aquamarine">课程信息</p><table class="courses"><tbody><tr><th>课程名称</th><th>讲师</th><th>地址</th></tr><tr><td>django打造在线教育</td><td>bobby</td><td><a href="https://coding.imooc.com/class/78.html">访问</a></td></tr><tr><td>python高级编程</td><td>bobby</td><td><a href="https://coding.imooc.com/class/200.html">访问</a></td></tr><tr><td>scrapy分布式爬虫</td><td>bobby</td><td><a href="https://coding.imooc.com/class/92.html">访问</a></td></tr><tr><td>diango rest framework打造生鲜电商</td><td>bobby</td><td><a href="https://coding.imooc.com/class/131.html">访问</a></td></tr><tr><td>tornado从入门到精通</td><td>bobby</td><td><a href="https://coding.imooc.com/class/290.html">访问</a></td></tr></tbody></table></div>
</body>
</html>
"""
#先取出所有的html值
sel=Selector(text=html)
#print(sel)
class_value=sel.xpath('//p[@class="work_years"]|//p[@class="position"]').extract()
print(class_value)
输出结果: