生态架构
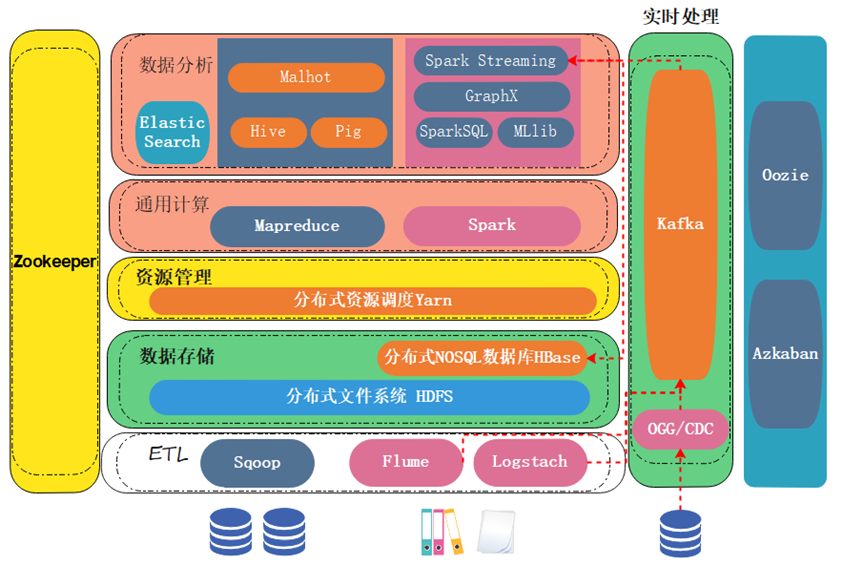
数据导入
离线方式处理的数据,需要通过 ETL 模块实现导入到大数据存储系统进行存储;其中 Sqoop 是常见的抽取结构化数据工具,而 Flume、LogStach 是用于抽取结构化、半结构化数据的工具。
数据存储
大数据的数据存储系统,最常见的包括分布式文件系统 HDFS;如果需要使用 NoSQL 的功能,HBase 是基于 HDFS 实现的一个分布式 NoSQL 数据库。
通用计算
存储的数据通过 MapReduce/Spark 框架进行实时计算,这些计算任务通过资源管理框架 Yarn 进行调度,从而将任务分发到数据存储 HDFS 中。
数据分析
在通用计算引擎如 MapReduce/Spark 编写处理任务的基础上,如果进行迁移就会带来很多问题,比如原始使用 SQL 进行数据处理任务,此时迁移到大数据平台。需要用 MapReduce/Spark 来替换原来的 SQL 业务,实现起来比较困难。
由此引入了 Hive,它实现了 SQL 转化为 MapReduce 任务,减少了数据仓库迁移成本;同理 Pig 和 Hive 类似,但它是将 MapReduce 封装为自己的 API,使用起来比原生 MapReduce 更加易用。
大数据实时流处理
数据采集
非结构化数据/半结构化数据:
- Flume、Logstash;
结构化数据: - 监控数据库预写日志,或者 CDC/OGG 等工具进行实时抽取。
实时抽取的数据会进入到消息队列中,完成削峰和解耦的功能,然后进行实时数据计算。
数据计算
- Spark Streaming:将实时任务转化为离线批处理任务进行处理,原理就是将一定时间间隔内的数据,转换为离线批处理任务。只要时间间隔够短就可以近乎于实时处理。
- Flink:有自己的计算引擎,能进行真正意义上的实时计算。