初步了解 机器学习
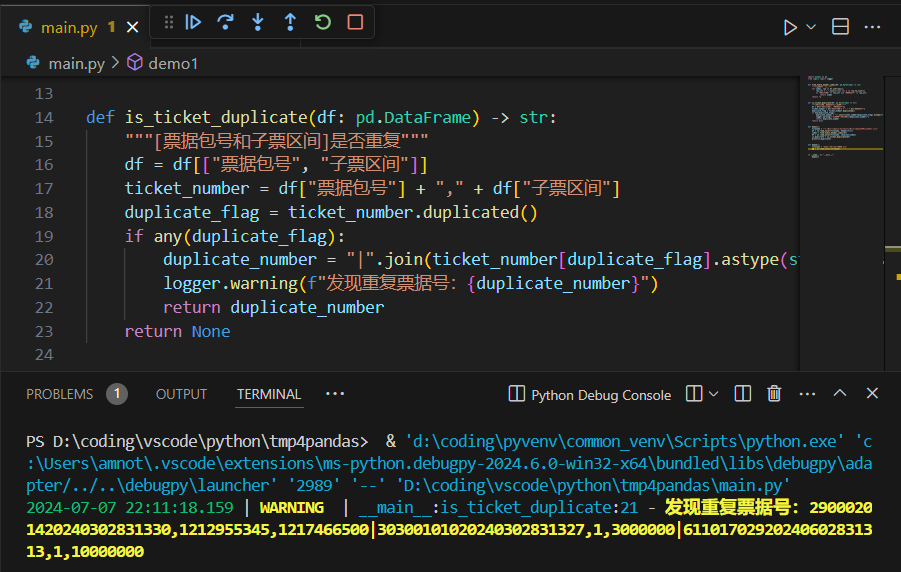
"""sklearn数据集使用:return:"""def dict_demo():"""字典特征抽取:return:"""data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray(), type(data_new))print("特征名字:\n", transfer.get_feature_names_out_out())return Nonetransfer = CountVectorizer(stop_words=["is", "too"])# 1、实例化一个转换器类transfer = CountVectorizer()def cut_word(text):"""进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门":param text::return:"""return " ".join(list(jieba.cut(text)))
![[LeetCode] 134. Gas Station](https://img2024.cnblogs.com/blog/747577/202407/747577-20240707232800466-649701410.png)