Text To SQL 指的是将自然语言转化为能够在关系型数据库中执行的结构化查询语言(简称 SQL)。近年来,伴随人工智能大模型技术的不断进步,Text To SQL 任务的成功率显著提升,这得益于大模型的推理、理解以及指令遵循等能力。
对于大数据平台来说,集成 Text To SQL 功能意义非凡。首先,这能够大幅优化用户体验;其次,Text To SQL 功能能够提高数据开发人员的工作效率,他们能够凭借自然语言描述来完成 SQL 任务的开发,进而极大地节省学习和编写复杂 SQL 语句的时间;最后,Text To SQL 功能降低了数据库查询的门槛,使得更多非技术人员能够参与到数据库查询工作中,让更多人得以享受大数据带来的便利。
本文将探讨袋鼠云在 Text To SQL 领域的探索与实践,分享如何实现更高效、更准确的自然语言到 SQL 的转换。
基于 LLM 实现 Text To SQL
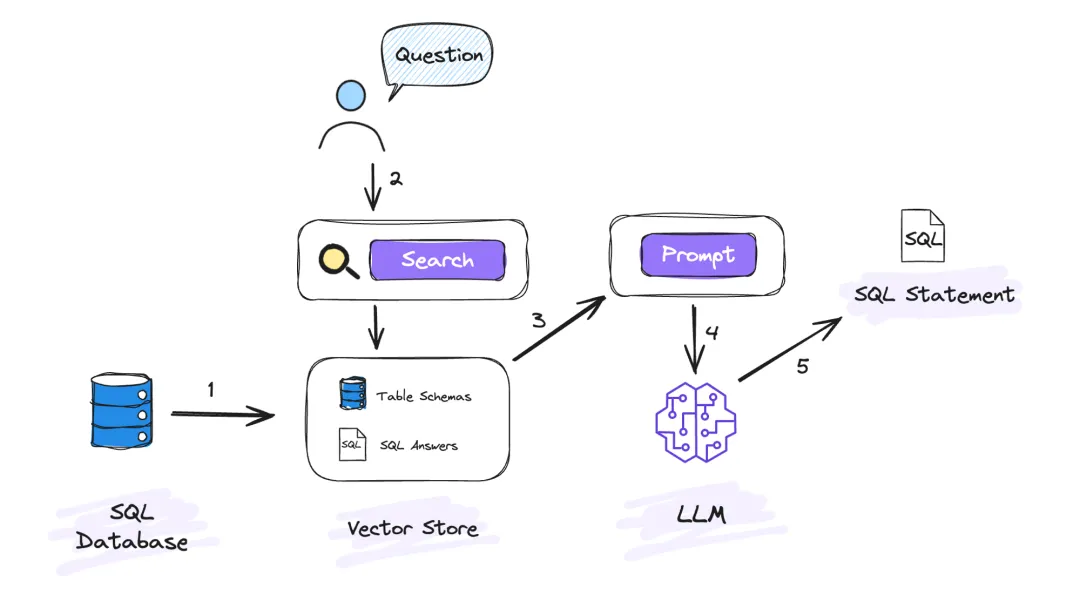
设计基于大模型(LLM)的 Text To SQL 系统是一项复杂且精细的任务,包括多个步骤和环节,每个步骤都需要我们精心设计和处理。首先,我们需要将数据库中表的元信息进行组织。此步骤涉及到将每一个表的详细信息,如字段名称、类型、关系等,写入到向量数据库中,这样就可以为后续的 SQL 生成提供必要的信息,这一步对于后续的 SQL 生成至关重要。
接着,我们需要对用户输入的自然语言加以理解。在这一步,我们将会运用先进的 embedding 模型。凭借这种模型,能够将用户输入的语言实施向量化处理,把每一个词或者词组转化为一个具备特定维度的向量。随后,我们会前往向量数据库中展开查找,匹配相关的表元数据信息,如此一来,我们便能知晓用户的查询意图与哪些表存在关联。
最后,我们把上一步匹配所得的表元数据信息与用户的问题加以合并,生成最终的 prompt。此 prompt 包括了全部所需的信息,涵盖角色表述、用户的初始问题、我们匹配到的相关表元数据信息以及一些约束条件。而后,我们把这个 prompt 交付给 LLM 模型,让模型依据这些信息生成最终的 SQL 查询语句。这一过程需要大模型(LLM)强大的计算能力以及精准的理解能力,以保障生成的 SQL 语句能够确切地反映用户的查询意图。
在数栈中实现 Text To SQL
● 表 schema 写入向量数据库
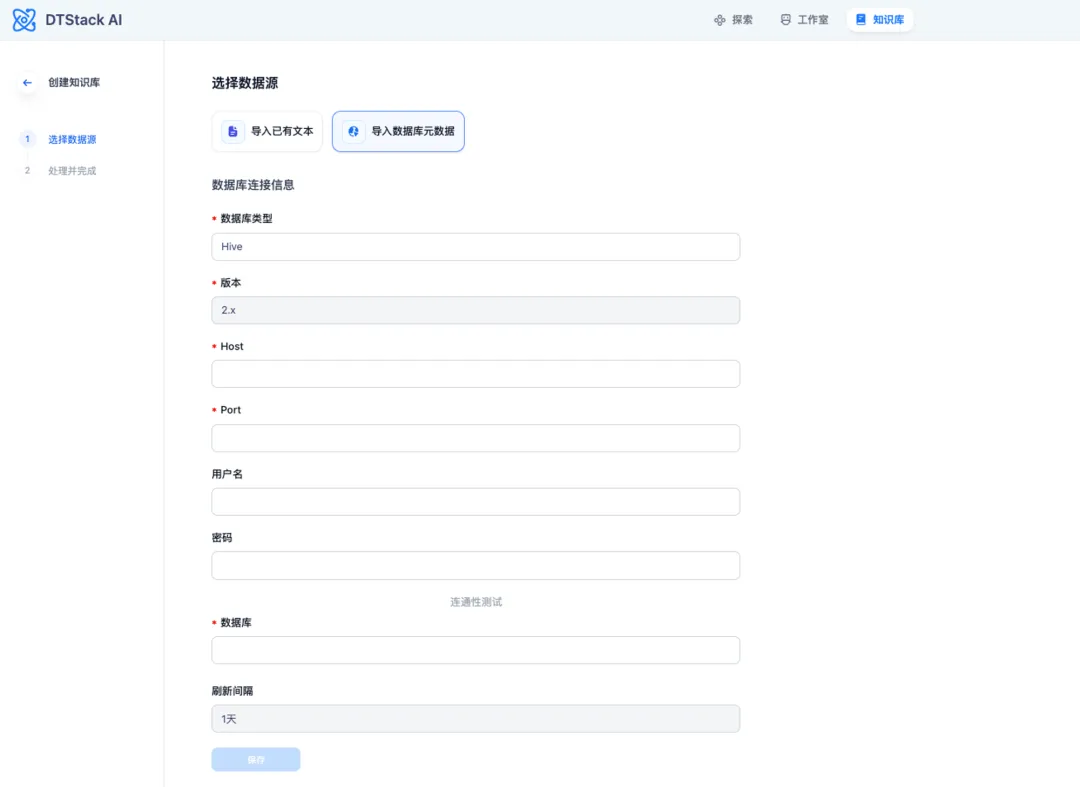
为了便于将数据库元数据置入向量数据库,在数栈中,我们研发了能够一键导入数据库表元数据信息的功能,并且支持自动刷新,如上图所示。
在此过程里,最为重要的当属如何对表的元数据信息进行组织,这一步极为关键,因为它会直接作用于 SQL 生成的准确性。我们所设计的表元数据信息组织格式如下:
table_name(column_name column_type column_comment,[...]), table_comment=""
● 根据用户问题匹配相关表元数据
这一步所面临的关键问题在于如何精准匹配到与用户输入问题相关的所有表元数据信息。为此,我们选用了对中文支持良好的 bge-large-zh-v1.5 embedding 模型,来对用户输入的问题进行向量化处理,以便充分领会用户的意图。
而在检索元数据信息方面,我们采用了混合检索的模式,即将向量化检索与全文搜索相结合。具体来说,首先依据用户问题生成的向量,在向量数据库中匹配出 TopK 条信息;接着运用 bm25 算法对表元信息进行一次全文搜索并获取结果;最后将向量检索和全文搜索所获取的结果予以合并,并进行一次相关性排序,从而得到最终的结果。
● 生成 Prompt
构建请求大模型的 Prompt。这里分享一个小技巧,就是使用 XML 标签来分隔 Prompt 中的每一部分内容。这种方法非常有效,因为大语言模型已经接受了大量包含 XML 格式的网页内容的训练,因此能够理解其结构,这样就能很好的帮助大模型完整识别到 Prompt 中的每一部分。
如下是我们定义生成 Text To SQL 的 Prompt 模版,
<context>表结构信息如下:{{表结构信息}}
</context>
<objective>你是一个高级SQL生成器,能够根据不同的SQL方言生成相应的SQL语句。你需要将用户输入的自然语言转化为SQL,请按照以下步骤操作:1. 请一步步思考并仔细分析用户的自然语言输入,确保充分理解用户的意图。2. 识别目标数据库类型为{{SQL方言}} SQL3. 考虑该数据库类型的特定语法和函数。4. 根据理解的用户意图,设计SQL查询的基本结构。5. 应用数据库特定的语法规则,对基本结构进行调整。6. 优化查询以提高性能(如适用)。7. 生成最终的SQL语句。在生成SQL时,请特别注意以下几点:- 使用{{SQL方言}} SQL特有的函数和语法结构 - 考虑该数据库类型的查询优化技巧 - 确保生成的SQL语句在语法和逻辑上的正确性如果用户的请求不明确或需要额外信息,请提出澄清性问题。
</objective>
● Prompt 构建完成后请求 LLM,生成 SQL
Prompt 构建完成后将 Prompt 发给大模型(LLM)执行,经过大模型(LLM)的推理能力生成 SQL。
Text To SQL 的优化手段
上文介绍了 Text To SQL 的一般流程,在这个流程中还可以加入一些优化手段来进一步提高生成 SQL 的准确率,下面分享两个优化技巧。
● Prompt Engineering - 动态少样本
Medprompt 是微软提出的一种极为有效的提示策略,动态少样本则属于 Medprompt 提示策略中的一项技巧。使用动态少样本可以进一步挖掘大模型的能力,提升响应的准确率。
在 Text To SQL 中如何使用动态少样本,首先可以结合自己的业务场景写出一些具有针对性的 SQL 生成问答对,然后将生成的这些问答对写入到向量数据库中,构建 Prompt 时根据用户输入问题进行一次向量检索然后将结果写入到 Prompt 中。
大模型存在不能理解某些领域的专有词汇问题,这个问题也可以通过这种方法解决,对于不能识别的词汇语句可以提前生成 SQL 生成问答对,生成 Prompt 时进行动态匹配,作为上下文发送给 LLM,这样 LLM 就能理解了。
● 模型微调
大模型(LLM)自身已然拥有 Text To SQL 的能力,而且通常模型规模越大,Text To SQL 的能力便越强。不管是大模型还是小模型,均能够通过微调来进一步增强 Text To SQL 的能力。当下,与 Text To SQL 相关的开源数据集众多,例如 WikiSQL、Spider 等等。
目前我们所采用的模型为阿里开源的通义千问 Qwen1.5-14B-Chat ,并运用 Spider 数据集进行了微调,模型微调前后在 Spider 数据集上的评测数据如下:

Text To SQL 在数栈中的应用
数栈作为一个大数据开发平台,始终专注于推动技术创新,提升用户体验。为了更进一步提高开发人员的工作效率并简化数据处理流程,数栈开发团队研发了「栈语妙编」智能助手。
「栈语妙编」智能助手能够把用户的自然语言描述转换为 SQL 语句,开发人员只需将待开发的 SQL 任务以自然语言进行描述,「栈语妙编」助手便会生成相应的 SQL ,如此一来,显著提升了开发人员的工作效率,使其能够将更多精力聚焦于数据分析和业务逻辑方面。
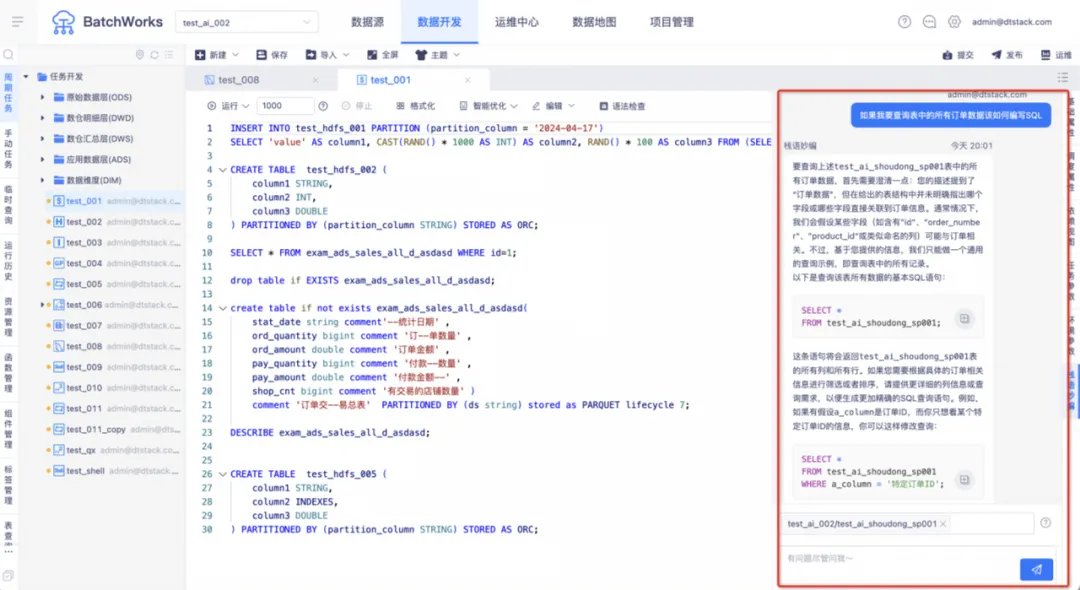
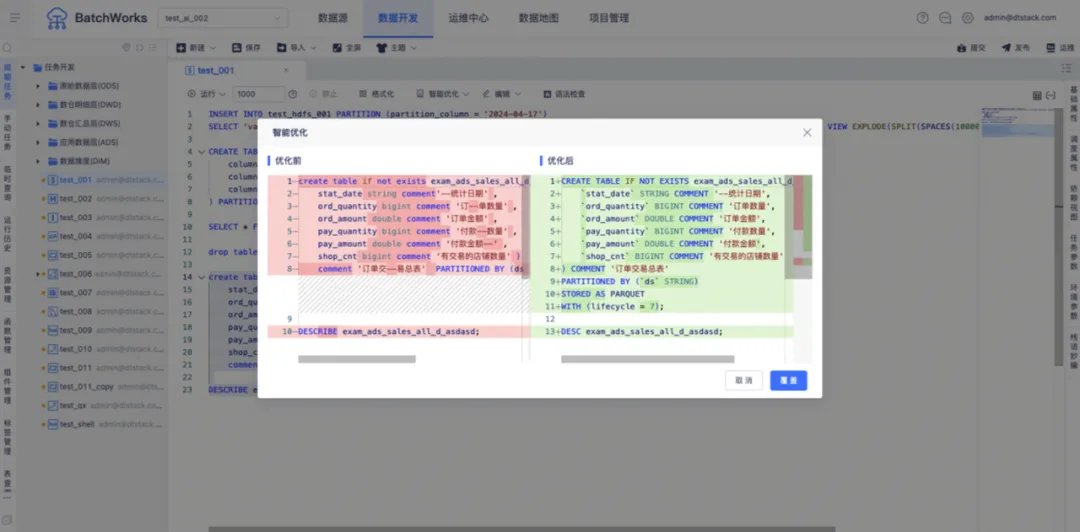
「栈语妙编」智能助手不仅可以根据自然语言生成 SQL,还可以对已有的 SQL 任务进行智能优化、SQL 纠错、代码补全和添加注释。
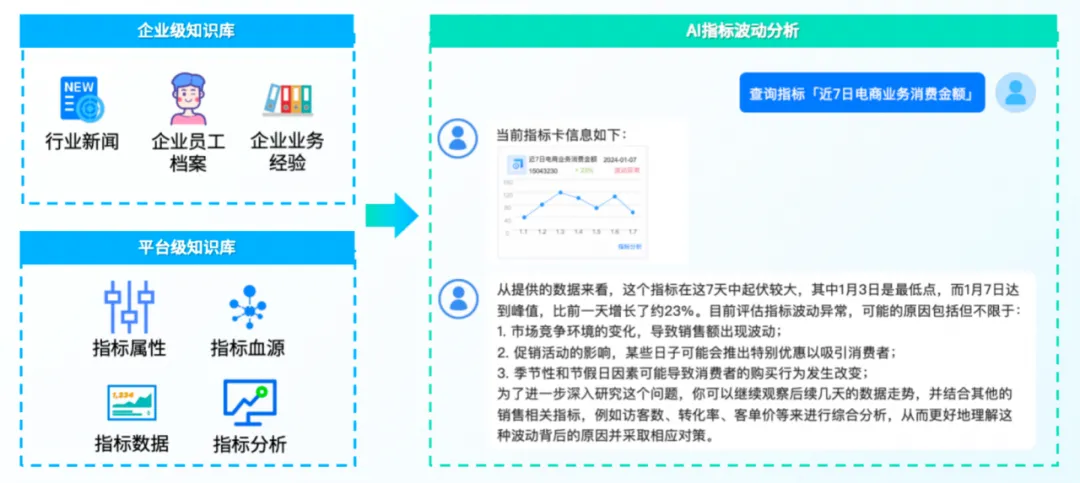
指标平台在数据驱动决策中扮演着至关重要的角色,为了使指标平台进入到一个新的智能化阶段,我们正在积极结合大模型(LLM)来提升指标平台的易用性、智能化程度和降低使用门槛,Text To SQL就是其中之一。
「袋鼠云指标管理平台」引入 Text To SQL 技术后,用户可以通过日常使用的自然语言来查询复杂的指标数据,并能基于查询结果进行深入分析,而无需掌握专业的 SQL 语法或了解底层数据结构。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky