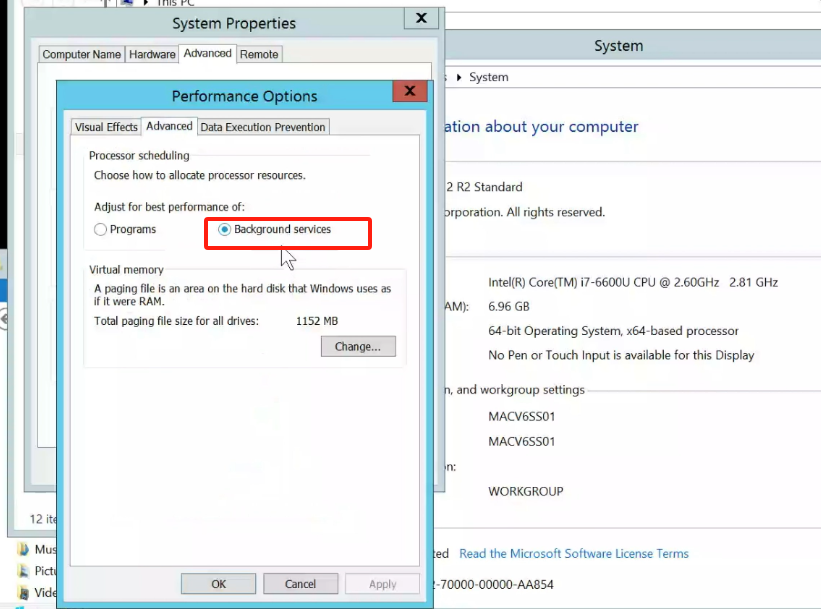
前段时间写过一篇介绍神经网络的入门文章:神经网络极简入门。
那篇文章介绍了神经网络中的基本概念和原理,并附加了一个示例演示如何实现一个简单的神经网络。
不过,在那篇文章中并没有详细介绍神经网络在训练时,是如何一步步找到每个神经元的最优权重的。
本篇介绍神经网络训练时,常用的一种权重更新的方式--梯度下降。
1. 回顾神经网络
首先,回顾一下神经网络模型主要包含哪些部分:
如上图所示,核心部分有:
- 神经元:图中黑色圆圈部分,接受输入,产生输出
- 层:神经元的集合,图中蓝色,绿色框,一个层一般包含一个或多个神经元

神经元对输入进行两步计算:
- 对各个输入按照权重求和
- 求和的结果再经过一个激活函数,得到一个输出值
神经网络的训练过程,就是给每个神经元找到一个合适的权重,
使得神经网络最后的输出(\(Output\))与目标值相差最小。
神经网络的结构不难,难点在于神经元和层多了之后,计算量暴增,需要强大的硬件支持。
2. 初始权重分配
下面回归本篇的主题,也就是神经网络中权重是如何更新和确定的。
我们知道,神经网络之所以如此流行,是因为基于它的模型,准确度远远好于传统的机器学习模型。
而神经网络模型的好坏取决于每个神经元的权重是否合理。
先假设做一个简单的神经网络,看看神经网络模型如何从输入值计算出输出值的。
这个网络中,假设我们的激活函数用\(y=\frac{1}{(1+e^x)}\)
那么,根据神经元的计算方法,先求和\(x_1w_{1,1}+x_2w_{2,1}\),
再用激活函数得到:\(y_1=\frac{1}{1+e^{(x_1w_{1,1}+x_2w_{2,1})}}\)
同理可得:\(y_2=\frac{1}{1+e^{(x_1w_{1,2}+x_2w_{2,2})}}\),\(y_2=\frac{1}{1+e^{(x_1w_{1,3}+x_2w_{2,3})}}\)
最终可得输出:\(z_1=\frac{1}{1+e^{(y_1 w^{'}_{1,1}+y_2 w^{'}_{2,1}+y_3 w^{'}_{3,1})}}\)
从上面的计算过程可以看出,\(x_1,x_2\)是输入值,无法改变;
\(y_1,y_2,y_3\)和\(z_1\)是计算产生的,也无法改变。
在神经网络中,我们能够调整优化的就是权重值\(w_{1,1},...,w_{2,3}\)以及\(w^{'}_{1,1},...,w^{'}_{3,1}\)。
理论上,初始化神经网络时,可以设置任意的权重,通过不断的训练最终得到合适的权重。
但实际情况下,模型的训练并不是万能的,初始权重设置的不好,对于训练花费的时间和训练结果都会造成不利的影响。
比如,初始权重设置的太大,会导致应用在数据上的激活函数总是处于斜率非常平缓的位置(如下图虚线红框处),
从而降低了神经网络学习到更好权重的能力。。
此外,还有一个问题是不要设置零值的权重,这也会导致神经网络丧失学习更好权重的能力。
所以,设置初始权重时:
- 选择随机的,值比较小权重,常见的范围是
0.01~0.99或-1.0~1.0(不要选择0) - 权重的分配最好与实际问题关联,比如实际问题中,知道某些输入值的重要性高,可以初始较大的权重
3. 误差的反向传播
训练神经网络,除了设置初始权重之外,另一个重要的部分就是计算误差。
误差就是根据训练结果与实际结果的差距。
比如上图,训练结果是\(o_1\),实际结果是\(t_1\),误差就是\(e=t_1-o_1\)。
根据这个误差\(e\),来计算上一层中各个神经元计算后的误差。
误差一般是根据神经元权重所占的比例来分配的。
比如,假设上图的神经网络中,最后一层的初始权重\(w^{'}_{1,1}=0.58, w^{'}_{2,1}=0.21, w^{'}_{3,1}=0.36\),
最后的误差为\(e=2\)。
那么,根据\(w^{'}_{1,1}, w^{'}_{2,1}, w^{'}_{3,1}\)的权重在这一层所占的比例来更新这一层的误差:
\(e_{y1}=e\times \frac{w^{'}_{1,1}}{w^{'}_{1,1}+w^{'}_{2,1}+w^{'}_{3,1}}=2\times \frac{0.58}{0.58+0.21+0.36}\approx 1.01\)
同理可得:\(e_{y2}\approx 0.37\),\(e_{y3}\approx 0.63\)。
然后再根据\(e_{y1},e_{y2}, e_{y3}\)去更新上一层的误差。
这样,从后往前,就得到了每个神经元的计算所产生的误差。
因为误差是从后往前计算的,所以也成为误差的反向传播。
4. 优化权重的思路
通过误差的反向传播计算出每个神经元的误差,目的就是基于这个误差来更新神经元的权重值。
- 当神经元的误差较大时,尝试减小神经元的权重值;
- 当神经元的误差较小时,尝试增加神经元的权重值。
这也就是梯度下降算法的思路。
那么权重每次更新多少合适呢?
每次更新步长太小,将导致计算量过大,经过很长时间的迭代才能找到最优值,如下:
而且,更新步长太小,还会导致找到次优值之后,就以为已经找到最优值,如下:
不过,每次权重更新步长过大,也会有问题,有可能会错过最优值,在最优值附近来回横跳,如下:
所以,计算出误差之后,更新权重不是一次就能完成的。
一般来说,会尝试用多种不同的步长来更新权重,看看哪种步长更新的权重会使得最后的误差最小。
5. 总结
总的来说,神经网络的训练,关键点主要有:
- 确定初始权重
- 误差反向传播
- 尝试不同步长更新权重,尽量找出最优值(也就是使得最终误差最小的权重)
整个训练过程大致如下:
上图中,结束训练的条件是误差<阈值,有的时候,可能会出现很长时间之后误差始终都大于阈值,无法结束训练。
这时,可以加一个条件,误差<阈值或者迭代次数到达1000次(可以任意次数),就结束训练。



![[SUCTF 2018]GetShell 1](https://img2024.cnblogs.com/blog/3335050/202407/3335050-20240715134528451-1789385396.png)