背光图像增强
M. Akai, Y. Ueda, T. Koga and N. Suetake, “A Single Backlit Image Enhancement Method For Improvement Of Visibility Of Dark Part,” 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 2021, pp. 1659-1663, doi: 10.1109/ICIP42928.2021.9506526.
-
这是一篇2021年用传统方法来做背光图像增强的论文。方法如下:
- 首先对RGB通道取均值得到了intensity image I I I,然后分别做gamma校正和直方图均衡化,把gamma校正的结果和均衡化的结果进行加权平均,得到增强后的intensity image O O O
- 然后用大津法(Otsu)找到划分黑白像素的阈值 t t t,对强度图 I I I进行二值化得到 W W W。随后对 W W W和 I I I利用导向滤波做下述计算得到weight map W ~ \tilde{W} W~:

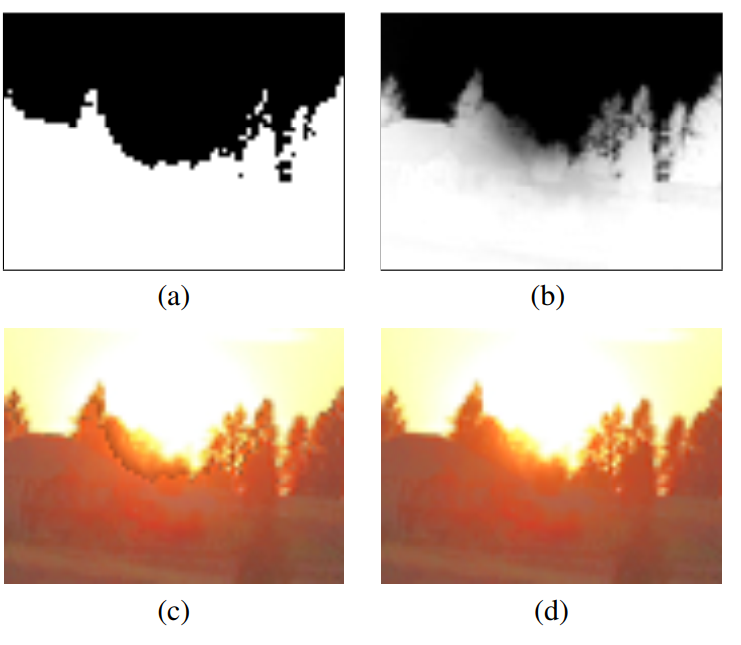
这一步的滤波目的是软化二值图,抑制伪影的同时保持边缘,滤波前后的weight map以及对应的增强结果如下图所示:
- 第三步是利用前两步得到的weight map和intensity map进行增强,公式如下图所示:
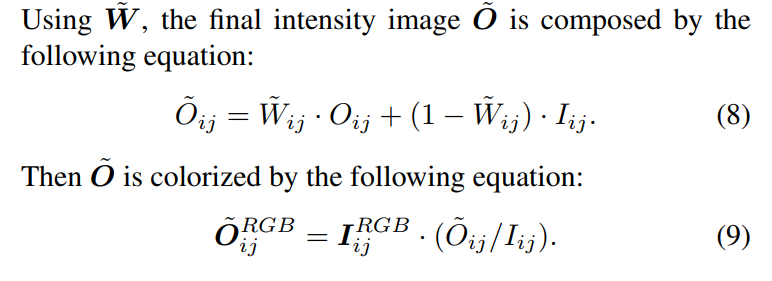
-
下面是实验结果:
- 原图:

- 增强结果:


- 速度比较:

- 原图:
-
评价:是传统方法 ,效果看起来欠曝的区域得到了增强的同时过曝区域没有进一步扩散和过曝,但无法抑制过曝。给出了一些图片的NIQE,和一些基于HE的方法进行比较,速度还挺快的。
Xiaoqian Lv, Shengping Zhang, Qinglin Liu, Haozhe Xie, Bineng Zhong, Huiyu Zhou,
BacklitNet: A dataset and network for backlit image enhancement,
Computer Vision and Image Understanding,
Volume 218,
2022,
103403,
ISSN 1077-3142,
https://doi.org/10.1016/j.cviu.2022.103403.
(https://www.sciencedirect.com/science/article/pii/S1077314222000340)
-
这是CVIU2022的一篇深度学习方法的论文。文章提出了一个背光图像数据集,有3000(2600train,400test)张背光图像以及对应的专家用adobe lightroom调制后的GT。数据集用的是4种单反相机拍摄的高分辨率的图像,并提供了RAW PNG JPEG的格式。图片如下图所示的效果,这说明GT是有做过曝抑制的:

-
网络结构如下图所示:
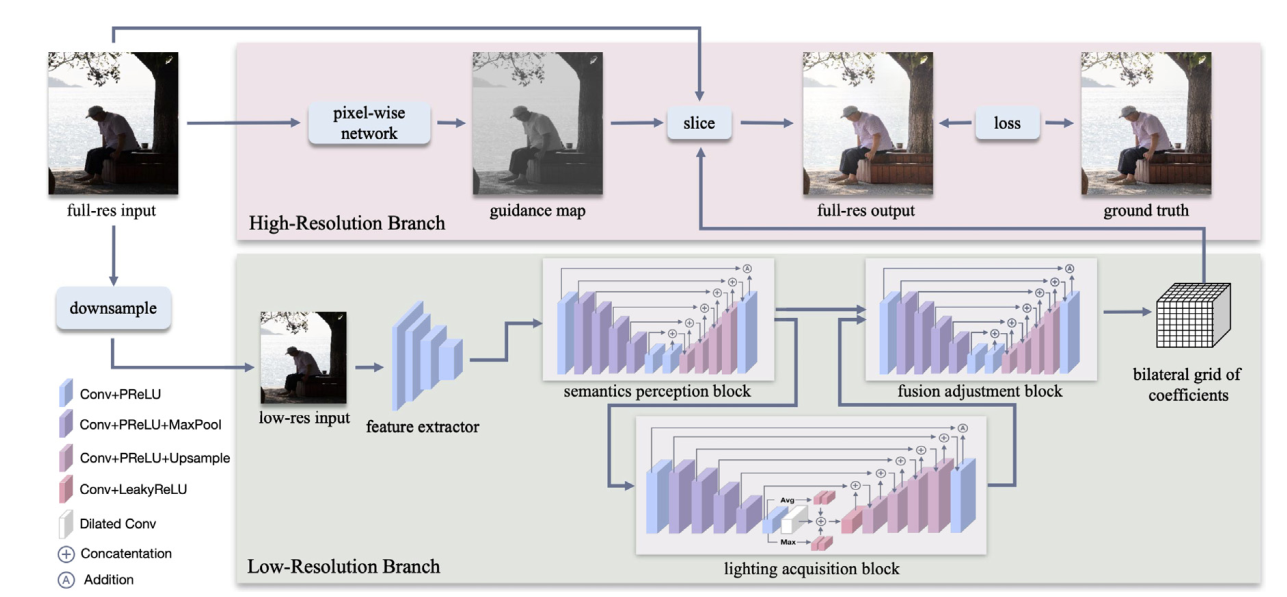
- 在下采样后的低分辨率图像上预测系数,然后用高分辨率输入图和在高分辨率输入图上提取的高分辨率guidance map的指导下利用Bilateral Guided Upsampling算法对系数进行上采样。从而增强结果是用系数和高分辨率图进行如下公式计算得出的结果(其实很像曲线估计方法(Zero-DCE)):
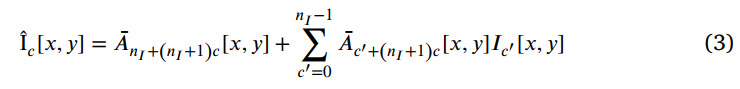
- 损失函数由如下两部分组成:
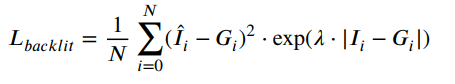
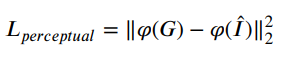
第一部分是对增强结果和GT的MSE做加权的结果,即当原图和GT的差越大,对增强结果和GT的差的惩罚权重就越高,反之越低;第二部分其实就是VGG16算的感知损失。
- 在下采样后的低分辨率图像上预测系数,然后用高分辨率输入图和在高分辨率输入图上提取的高分辨率guidance map的指导下利用Bilateral Guided Upsampling算法对系数进行上采样。从而增强结果是用系数和高分辨率图进行如下公式计算得出的结果(其实很像曲线估计方法(Zero-DCE)):
-
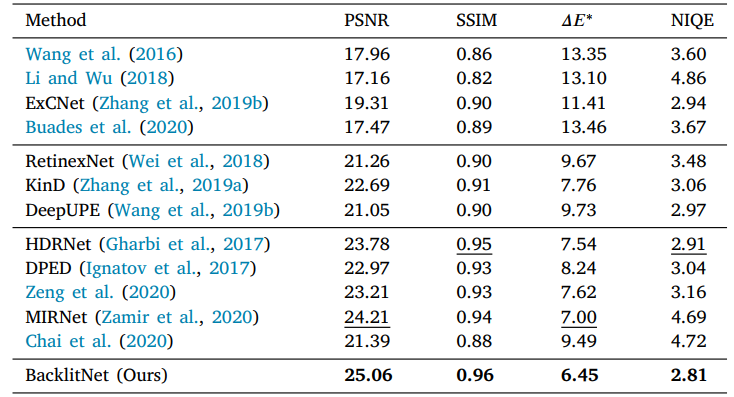
实验结果上,与一些背光图像增强方法、一些暗图增强方法和一些通用增强方法在测试集上比较了PSNR SSIM NIQE和颜色距离 Δ E ∗ \Delta E^* ΔE∗:
-
从可视化效果看,还是没有处理好过曝部分

-
同时对LOL数据集也作了比较。
-
总体上看,数据集部分倒是很有意义的,模型因为涉及Bilateral Guided Upsampling我没有看得太仔细,差不多是个低分辨率曲线估计上采样的方法,损失函数是简单的有监督成对图像损失函数,然后实验结果看还不错,不过因为GT是手调的,模型的训练结果就受限于手调图的质量,从上面这张图就可以看出来其实手调的结果也不咋地,所以模型出来的结果也就一般。这个是未来的一个改进方向
Lin Zhang, Lijun Zhang, Xiao Liu, Ying Shen, Shaoming Zhang, and Shengjie Zhao. 2019. Zero-Shot Restoration of Back-lit Images Using Deep Internal Learning. In Proceedings of the 27th ACM International Conference on Multimedia (MM '19). Association for Computing Machinery, New York, NY, USA, 1623–1631. https://doi.org/10.1145/3343031.3351069
-
这是ACMMM2019的一篇背光图像增强的论文,是test time training地训练一个小CNN去无监督地估计一个S曲线,用来增强背光图像。
-
它估计的是一个全局的曲线,曲线公式如下:

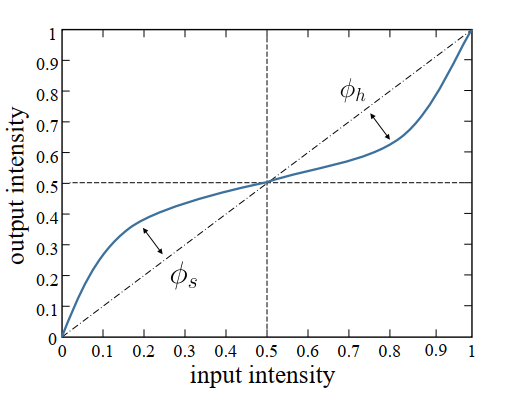
-
所以它的CNN网络只有两个输出: ϕ s , ϕ h \phi_s, \phi_h ϕs,ϕh,网络名为ExCNet,由几层CNN和几层全连接组成。输入为 I l I_l Il,是输入图像的亮度通道,输出为 I l c I^c_l Ilc
-
损失函数受马尔可夫随机场启发,为patch-wise的如下损失函数:
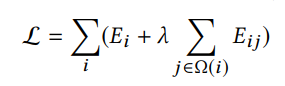
其中, Ω ( i ) \Omega(i) Ω(i)表示第 i 个patch的4邻域patch,因此损失函数可以看作是两部分组成,一部分是每个patch各自的损失,第二部分是每对patch之间的损失。其中, E i E_i Ei和 E i j E_{ij} Eij如下所示
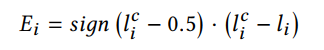
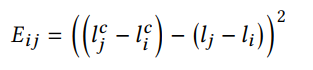
E i E_i Ei的形状如下图所示:

其实就是增强结果在0.5能取到最低损失,就训练的梯度来说完全可以用 ∣ I i c − 0.5 ∣ |I_i^c-0.5| ∣Iic−0.5∣来替代,搞得花里胡哨的。。而 E i j E_{ij} Eij约束增强前后相邻块的对比度不变。 -
首先用导向滤波将图像分为base分量和detail分量,base分量图像转换到YIQ空间,取Y通道为亮度通道,送进网络并取得调整结果,根据Y通道调整结果调整结果调整其他两个通道,然后和detail分量用weber contrast方法融合得到最终的增强结果:
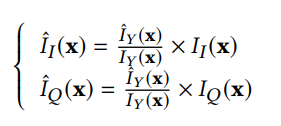
-
实验结果看起来很不错:


- 指标上在 I E p s D IE_{ps}D IEpsD数据集(Lijun Zhang, Lin Zhang, Xiao Liu, Ying Shen, and Dongqing Wang. 2018. Image exposure assessment: A benchmark and a deep convolutional neural networks based model. In 2018 IEEE International Conference on Multimedia and Expo (ICME ’18). IEEE, San Diego, CA, USA, 1–6. https://doi.org/10.1109/ICME.2018.8486569)上和一些传统方法比较了user study的结果和LOD、CDIQA指标:
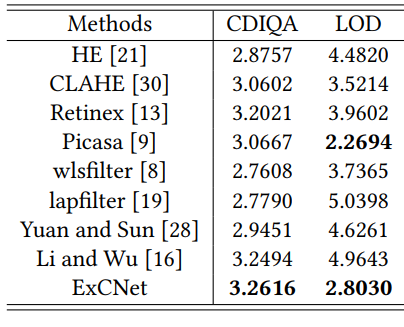
- 运行效率上,在Titan X上达到了每秒1张4032x3024图片的速度。
- 作为一个zero-shot的test time training 的无监督方法,设计的全局曲线估计方法挺有意思,实验结果看起来也还不错。同时由于简单的全局曲线估计,损失函数也可以相应简化。
- 指标上在 I E p s D IE_{ps}D IEpsD数据集(Lijun Zhang, Lin Zhang, Xiao Liu, Ying Shen, and Dongqing Wang. 2018. Image exposure assessment: A benchmark and a deep convolutional neural networks based model. In 2018 IEEE International Conference on Multimedia and Expo (ICME ’18). IEEE, San Diego, CA, USA, 1–6. https://doi.org/10.1109/ICME.2018.8486569)上和一些传统方法比较了user study的结果和LOD、CDIQA指标:
Gaurav Yadav, Dilip Kumar Yadav,
Contrast enhancement of region of interest of backlit image for surveillance systems based on multi-illumination fusion,
Image and Vision Computing,
Volume 135,
2023,
104693,
ISSN 0262-8856,
https://doi.org/10.1016/j.imavis.2023.104693.
- 这是Image and Vision Computing这个期刊2023年一篇做背光图像感兴趣区域对比度增强的论文。它先分割出背光的区域(用Z. Li and X. Wu, “Learning-Based Restoration of Backlit Images,” in IEEE Transactions on Image Processing, vol. 27, no. 2, pp. 976-986, Feb. 2018, doi: 10.1109/TIP.2017.2771142.),然后用多种gamma校正和log transform得到多亮度的图片(各5种共10种),然后用这些图片送进亮度估计网络LightenNet(C. Li, J. Guo, F. Porikli, et al., Lightennet: A convolutional neural network for weakly illuminated image enhancement, Pattern Recogn. Lett. 104 (2018) 15–22, https:// doi.org/10.1016/j.patrec.2018.01.010)得到多个亮度估计(即retinex理论中的照度分量,除以亮度估计可以得到增强结果),将这些亮度估计计算得到的增强结果的平均值(相加除以10)作为ROI的增强结果,如下图所示
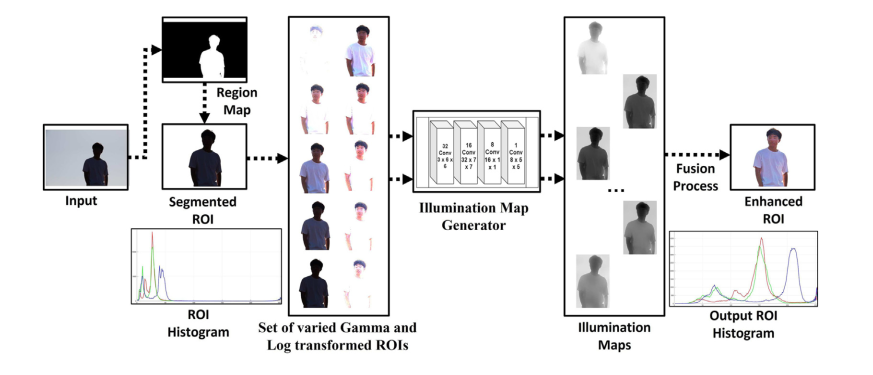

- 虽然方法很简单且大多数方法基于原有方法,但实验结果看起来是不错的:


- 此外,文章用的一些衡量指标也有点意思,contrast measure(CM)指的是每个patch增强结果的方差除以原图的方差,再对不同区域加权平均,如下:
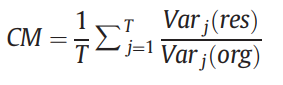
- 总体看起来,有点多源融合的思想,但多源数据仅直接gamma校正和log transform得到,融合也仅直接平均,增强的方法还用的是现有方法LightenNet,感觉有改进空间。
Z. Li and X. Wu, “Learning-Based Restoration of Backlit Images,” in IEEE Transactions on Image Processing, vol. 27, no. 2, pp. 976-986, Feb. 2018, doi: 10.1109/TIP.2017.2771142.
- 这是TIP2018的一篇做背光图像修复的机器学习方法的论文。文章主要思想就是区分背光的前景和背景,分别处理。
- 用来区分前景和背景的是两个SVM的二分类器。第一个分类器用来区分某个patch是前景还是背景,有人工标注,进行有监督训练。SVM的特征选的是亮度的分布、patch的亮度通道值,平均饱和度和skewness。第二个分类器用来区分一个块是不是前景和背景的边缘所在块。
- 首先用SILC算法分patch(R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Süsstrunk,
“SLIC superpixels compared to state-of-the-art superpixel methods,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 11, pp. 2274–2282, Nov. 2012.),然后用两个SVM分别进行二分类,用条件随机场进一步优化,然后滤波,产生最终的分割结果。(太多复杂的公式和算法了我没有仔细读) - 然后对前景和背景区域分别用两条曲线去增强。曲线的定义采用的是向量化定义方式,对每个亮度级别 l j l_j lj都定义一个增量 s j s_j sj,从而对某个亮度的输入 l k l_k lk,其增强结果为如下累加和:
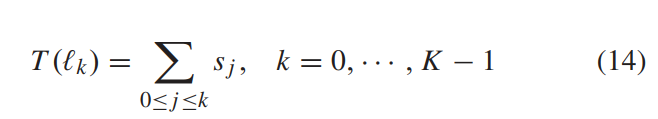
- 曲线的优化目标是最大化全局对比度增益,同时保证不失真,如下:
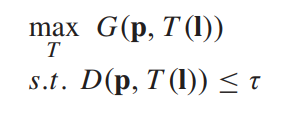
- 其中G衡量对比度增益,用的是如下的定义方式:
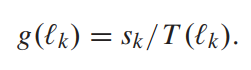
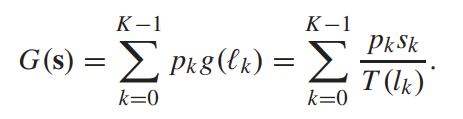
即g的加权平均,其中g为增强结果相邻亮度level之间的相对增量 - 而D则根据(X. Wu, “A linear programming approach for optimal contrast-tone mapping,” IEEE Trans. Image Process., vol. 20, no. 5, pp. 1262–1272, May 2011.)定义为:
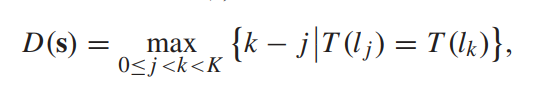
等价定义为:
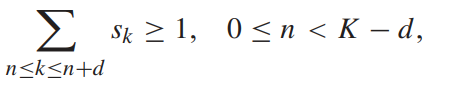
其实就是不能出现很多原图的不同亮度层级被映射到增强结果的相同亮度层级,否则就会失真。
- 其中G衡量对比度增益,用的是如下的定义方式:
- 这个优化问题用现有的算法可以直接求最优值,因此可以得到两条最优的tone mapping曲线。
- 前景背景增强结果的融合方式在非边界patch是直接取其一,而边界patch则根据分割的概率值进行加权平均:
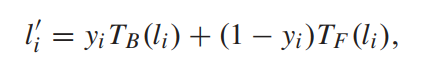
- 实验结果看起来还行:

- 总体看,这是一篇经典的传统机器学习方法的论文,用了非常多的公式和优化算法,将问题一步步分解成机器学习算法能解决和优化的问题。其目标函数和曲线的设计值得参考,前景背景分治的方式也有进一步改进空间,但曲线的增量设计方式意味着这样的算法无法抑制过曝。
Y. Ueda, T. Koga and N. Suetake, “Fusion-Based Backlit Image Enhancement Using Multiple S-Type Transformations For Convex Combination Coefficients,” 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 2022, pp. 2971-2975, doi: 10.1109/ICIP46576.2022.9897370.3
- 这是2022ICIP的一篇基于传统方法进行背光增强的论文,基本思想还是先产生多个增强结果,再融合这些结果。
- 文章定义了一个曲线公式:
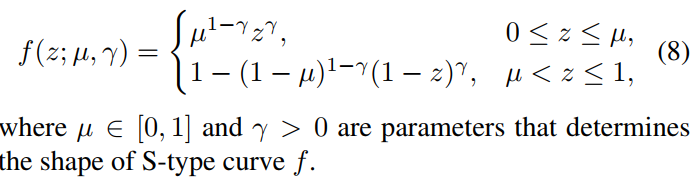
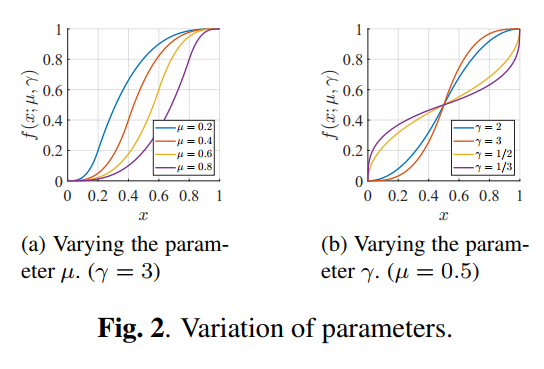
-
文章将图片分解为三个分量:白色 a w a_w aw、黑色 a k a_k ak、彩色 a c a_c ac:
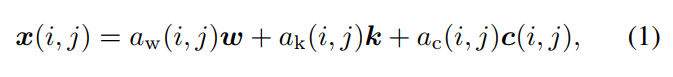
其中, x ( i , j ) , a w ( i , j ) , a k ( i , j ) , a c ( i , j ) x(i,j),a_w(i,j),a_k(i,j),a_c(i,j) x(i,j),aw(i,j),ak(i,j),ac(i,j)都是1x3的向量,表示每个位置的三通道值, w = ( 1 , 1 , 1 ) , k = ( 0 , 0 , 0 ) w=(1,1,1),k=(0,0,0) w=(1,1,1),k=(0,0,0),每个分量分别定义如下:
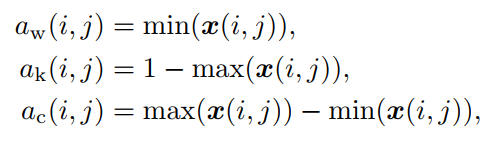
- 根据定义可以推算出 c ( i , j ) c(i,j) c(i,j)如下:
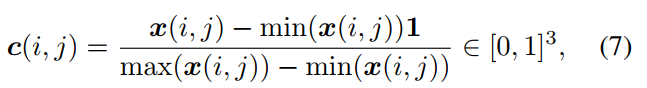
- 从而对各个分量分别用前面定义的曲线进行增强
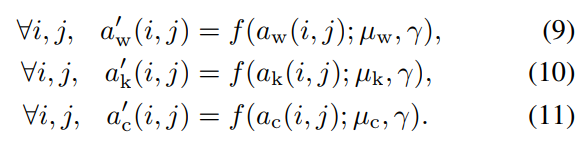
- 再归一化一下:
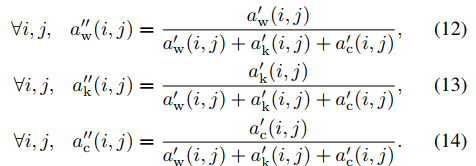
- 再组合回去得到增强结果:
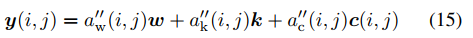
- 根据定义可以推算出 c ( i , j ) c(i,j) c(i,j)如下:
-
从曲线的图可以看到,曲线围绕 μ \mu μ来拉伸对比度,因此多个版本的增强结果的核心就是找到不同的 μ \mu μ。为此首先将图像的强度分布画出来,用如下的三轴图表示,然后进行聚类(K-meas++),找到30个聚类中心,以这些聚类中心的三通道值作为三通道各自的 μ \mu μ定义曲线,而 γ \gamma γ是预定义的超参数,用来决定对比度拉伸的程度,大于1时拉伸 μ \mu μ附近的值的对比度,小于1时压缩,但能拉伸0附近的值的对比度,因此可以增强暗图区域。
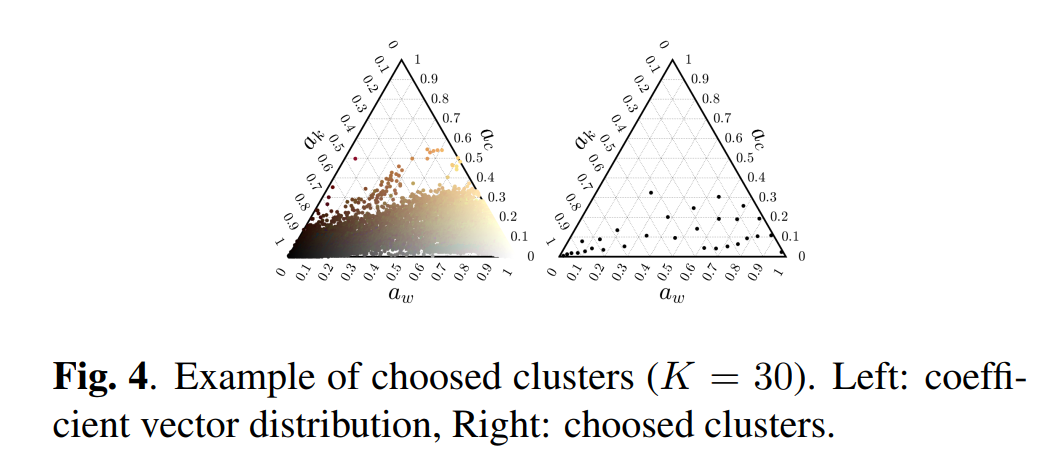
-
基于这一点呢,分两波进行曲线增强,首先以30个聚类中心作为 μ \mu μ值,以这个 γ = 3 \gamma=3 γ=3作为 γ \gamma γ值,产生30个增强结果。同时,对接近(1,0,0)的聚类中心,额外进行一些以 1 / 3 1/3 1/3作为 γ \gamma γ值的增强,产生D个增强结果,对这30+D个增强结果进行融合(用的是T. Mertens, J. Kautz, and F. Van Reeth, “Exposure fusion,” in 15th Pacific Conference on Computer Graphics and Applications (PG’07), 2007, pp. 382–390.)得到最终的增强结果。
-
实验结果看起来还不错:

-
文章提出一个观点,黑暗区域有必要拉伸对比度因为内部存在重要的纹理信息,而明亮区域的对比度拉伸不重要因为这些区域内部通常不存在纹理信息和物体,拉伸会导致伪影。这个可能是多数背光图像没有考虑过曝抑制的原因。但我觉得这一点有待商榷。
-
另外,对图像进行分解的公式,以及画出来的分布很有意思,可能作为一个促进色彩多样性的先验监督,后续再进行探究。基于聚类中心来确定 μ \mu μ值来拉伸也是很有意思。
Liang Z, Li C, Zhou S, et al. Iterative Prompt Learning for Unsupervised Backlit Image Enhancement[J]. arXiv preprint arXiv:2303.17569, 2023.
- 这篇是李重仪老师所在的S-Lab放在arxiv上的文章,应该是还没发表,用CLIP和提示学习来做无监督背光图像增强的论文:

- 流程图如图所示:
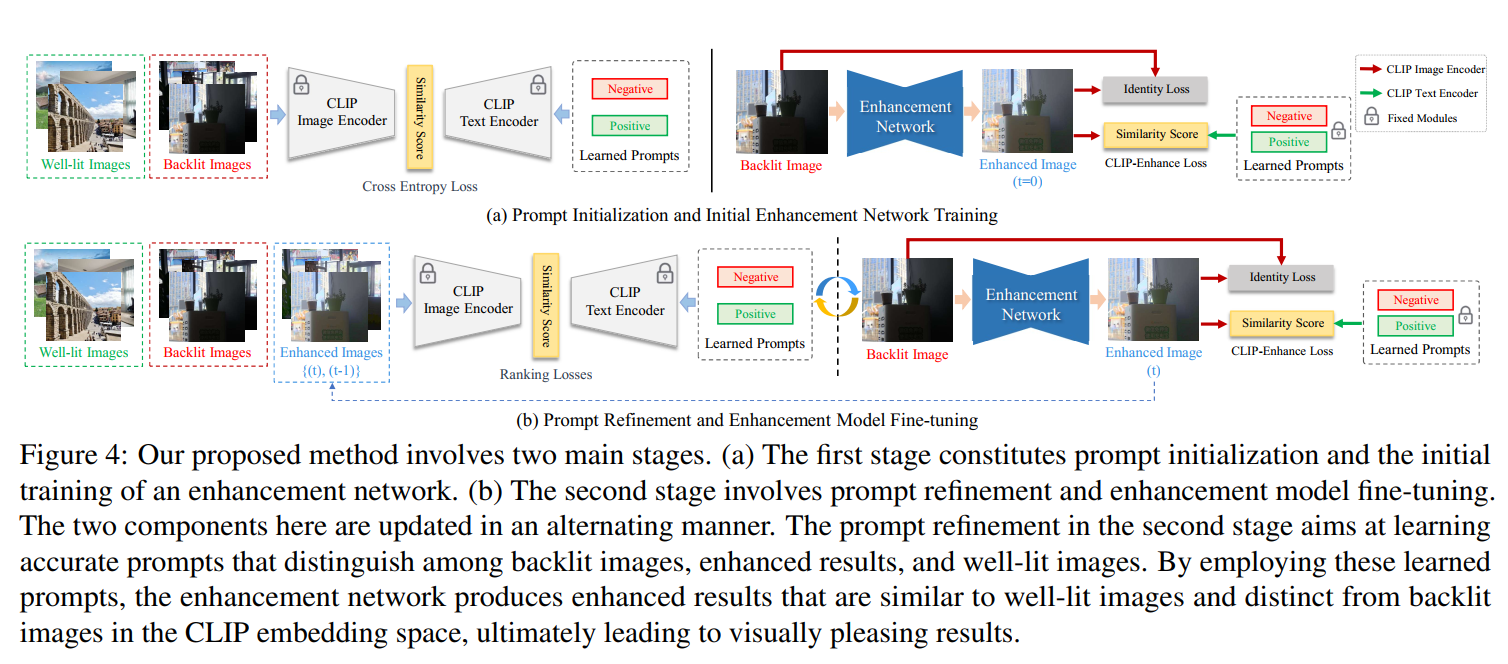
- 第一阶段先用一些 well-lit images 和 backlit images 来优化两个 prompt,最终的结果是得到两个prompt,分别对应well-lit的语义和backlit的语义。这一步用的损失函数如下:
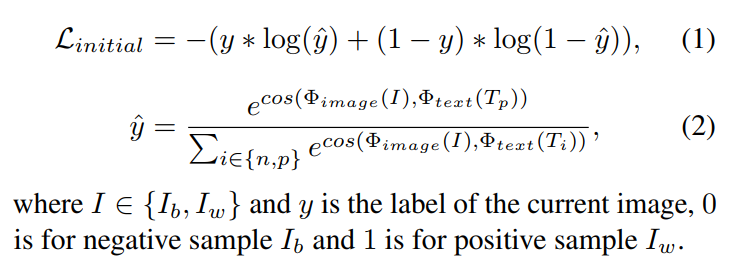
- 第二阶段是训练增强网络。增强网络是一个简单的Unet,最后输出单通道的照度图,用原图除以照度图得到增强结果。第二阶段的损失函数由两部分组成,一个是增强结果的特征和原图的特征之间的L2距离,一个是增强结果的特征与第一阶段获得的两个prompt提取的文本特征之间的对比损失:
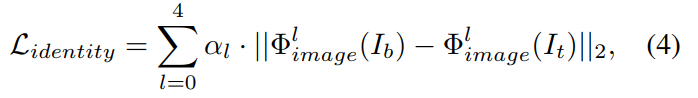 .
.
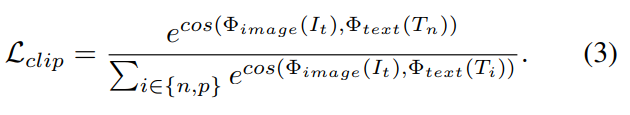
这一步的结果是获得了一个训练好的Unet网络。这一阶段可以分为两个子阶段,首先用1k个itertaion训练只有identity loss的,再训练有两个损失的 - 第三阶段是finetuning,交替得finetune prompt和Unet网络,有点类似对抗训练,希望prompt能区分出增强结果和well-lit images(训练prompt),又希望增强结果不被区分出(训练Unet)。训练prompt用的是rank loss,如下:

- 首先我们看 S S S函数的性质,其实就是其提取的图像特征与 T n T_n Tn的文本特征越接近 S S S值就越大,也就是说衡量的是背光的程度,越背光值越大。这里有三项,第一项是希望 S ( I w ) S(I_w) S(Iw)比 S ( I b ) S(I_b) S(Ib)小 m 0 m_0 m0以上,这里 m 0 m_0 m0被设为0.9;第二项是希望 S ( I t ) S(I_t) S(It)也比 S ( I b ) S(I_b) S(Ib)小 m 0 m_0 m0以上;第三项是希望 S ( I w ) S(I_w) S(Iw)比 S ( I t ) S(I_t) S(It)小 m 1 m_1 m1以上, m 1 m_1 m1被设为0.2。其意义在于希望prompt能提供一个正确的顺序,其文本特征与well-lit的图片的相似度最高,与增强结果的相似度排第二,与背光图片的相似度最低。
- 这个损失函数可以被进一步改进。因为用的是迭代学习的方式,增强网络更新前后,会有两个增强结果,所以可以进一步定义损失函数如下,其中 m 2 = m 1 = 0.2 m_2=m_1=0.2 m2=m1=0.2:
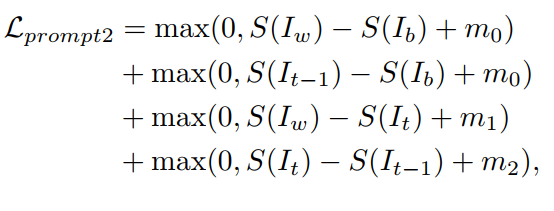
- 而增强网络的更新用的损失函数和第二阶段的一样。
- 文章在BAID训练集里随机找了380张背光图像和DIV2K里384张well-lit图像用来训练模型。在BAID测试集上测试。同时采集了一个测试集叫backlit300,用来测试泛化性。训练用了数据增强,flip,zoom,rotate。prompt的单词数设为16。模型总共训练50k个迭代,其中10k个迭代用来训练第一阶段。
- 实验结果看起来,Zero-DCE确实是好,而本文的方法也确实指标上比较好:
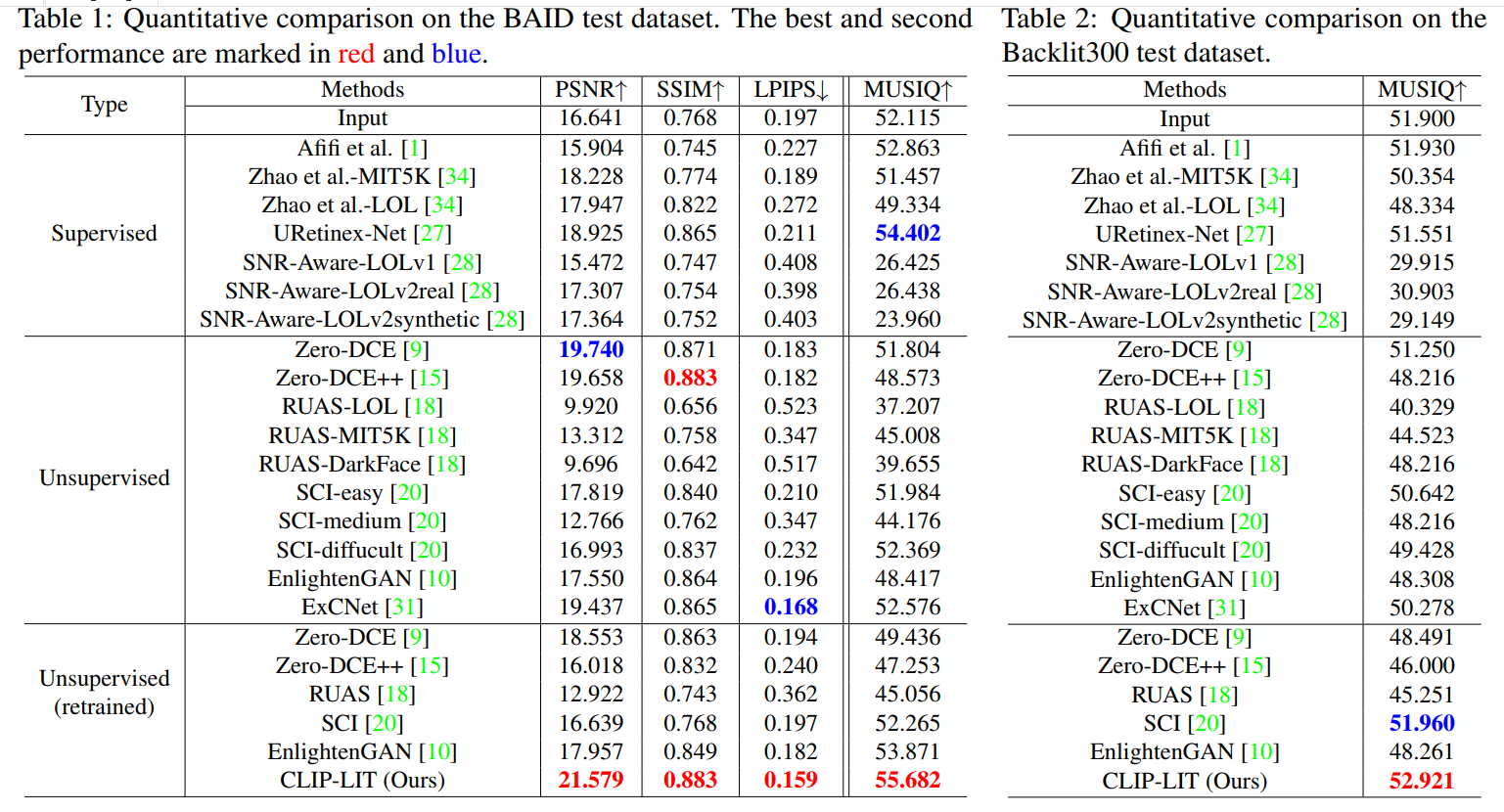
- 从附录来看增强结果的可视化效果也确实不错:

- 而且根据(Hila Chefer, Shir Gur, and Lior Wolf. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In ICCV, 2021. 5)可视化的注意力图来看prompt确实是在关注背光区域: