抓取金投网文本数据(xpath练习)
创建时间:2024年8月5日
一、完整代码
import requests
from lxml import etreeheader = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
url = 'https://cang.cngold.org/c/2024-05-21/c9310686.html'
res = requests.get(url=url, headers=header)
text = res.content.decode()
tree = etree.HTML(text)
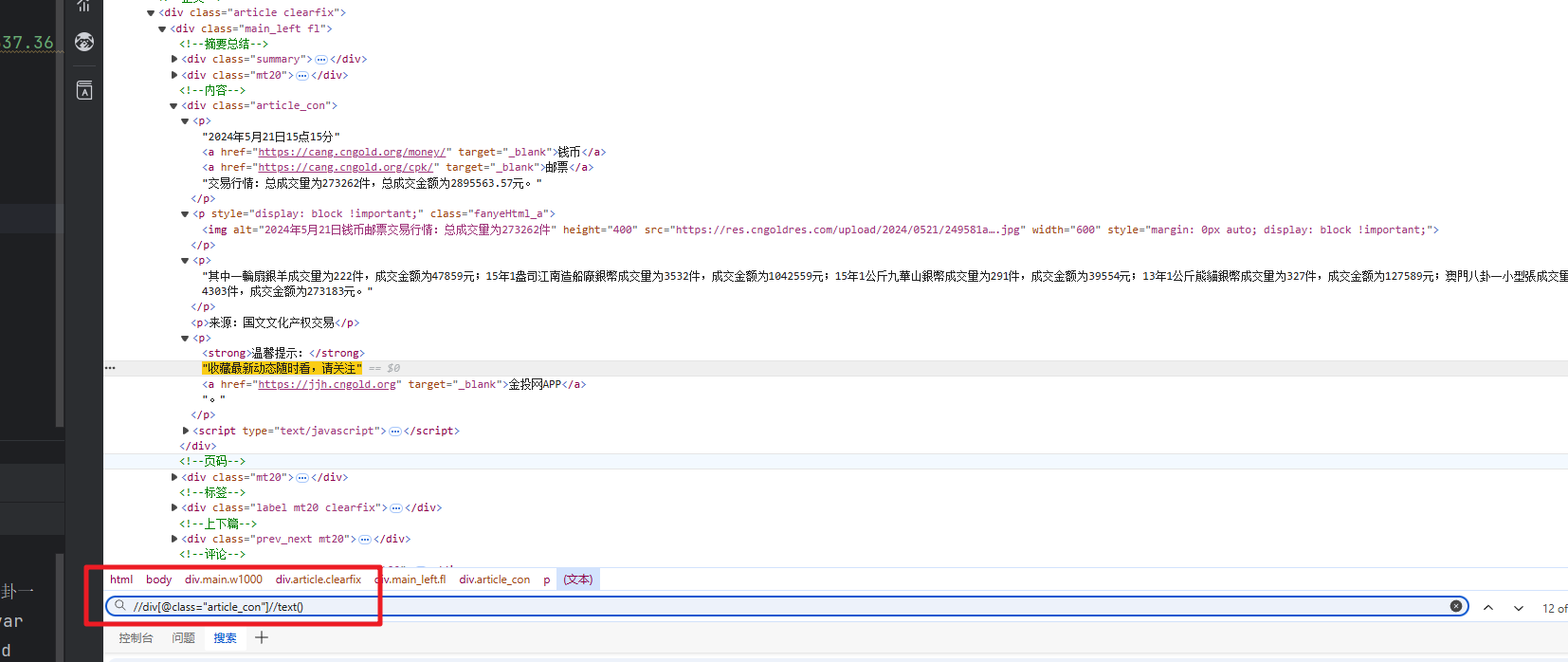
text = tree.xpath('//div[@class="article_con"]//text()')
print(text)
1.1 效果

二、代码讲解
2.1 主要是分析文本在什么地方
f12打开网站。--》选择元素--》选择检查---》然后鼠标放在需要抓取的内容,即可看到页面代码对应位置,然后使用下面的xath解析
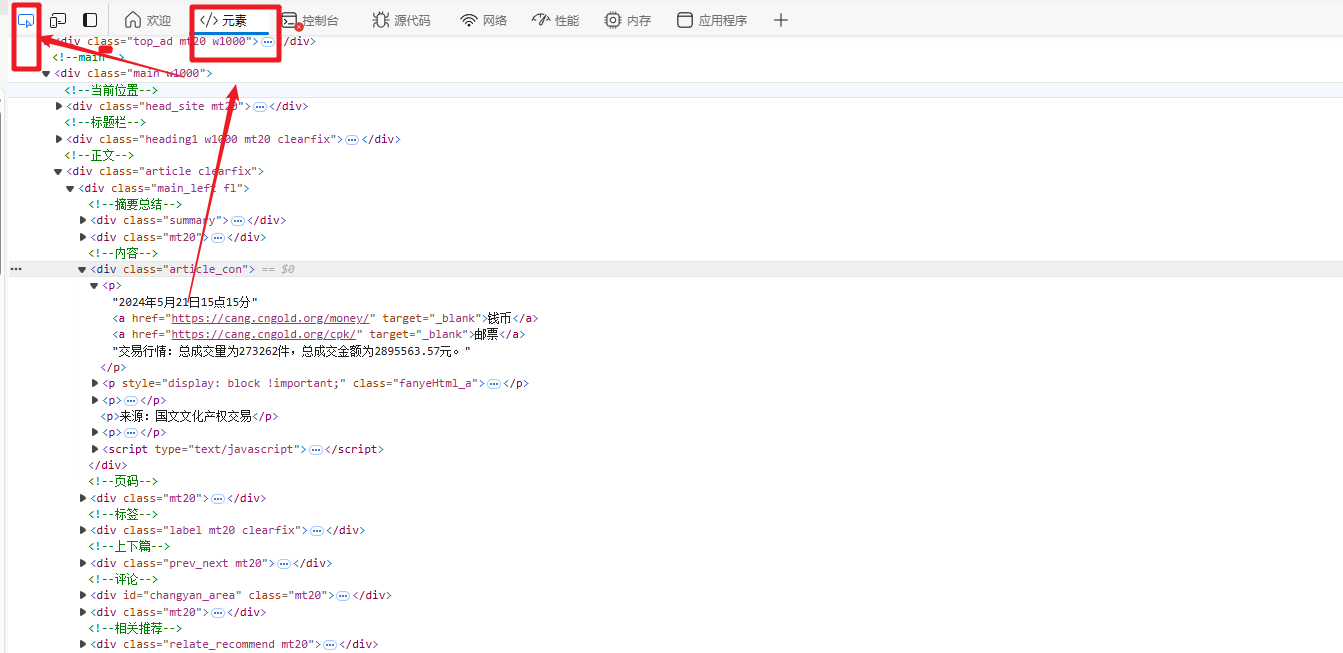
具体的地址:可先在元素界面使用 ctrl + f ,输入写的xpath检验是否正确。