视图
1. 为什么要使用视图?什么是视图?
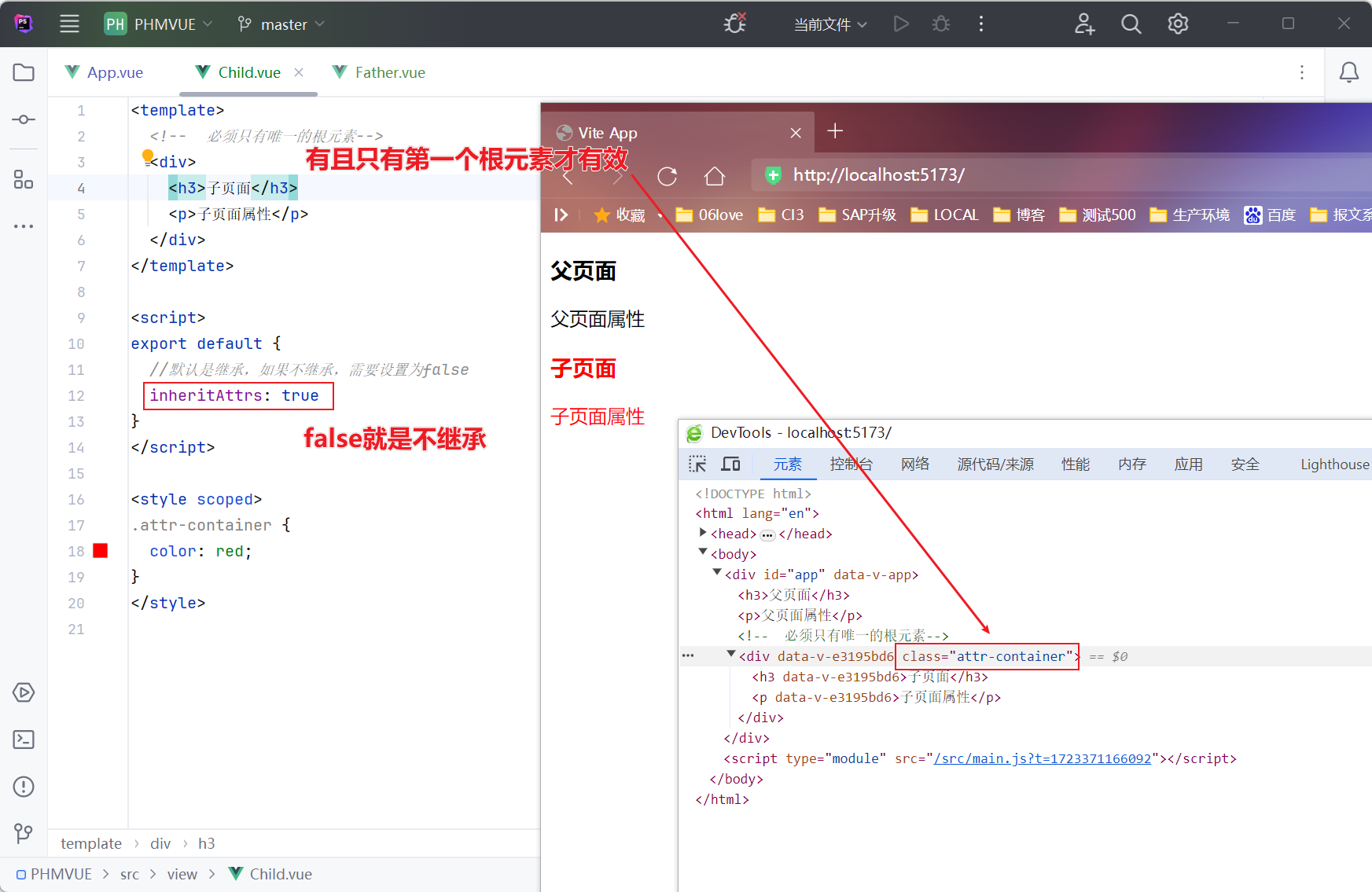
- 为了提高复杂 SQL 语句的复用性和表操作的安全性,MySQL 数据库管理系统提供了视图特性。所谓视图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的列和行数据。但是,视图并不在数据库中以储存的数据值形式存在。行和列数据来自定义视图的查询所引用基本表,并且在具体引用视图时动态生成。
- 视图使开发者只关心感兴趣的某些特定数据和所负责的特定任务,只能看到视图中所定义的数据,而不是视图所引用表中的数据,从而提高了数据库中数据的安全性。
2. 视图有哪些特点?
视图的特点如下:
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。
- 视图的操作包括创建视图,查看视图,删除视图和修改视图。
3. 视图的使用场景有哪些?
视图根本用途:简化 SQL 查询,提高开发效率。如果说还有另外一个用途,那就是兼容老的表结构。
- 重用 SQL 语句;
- 简化复杂的 SQL 操作。在编写查询后,可以方便地重用它而不必知道它的基本查询细节;
- 使用表的组成部分而不是整个表;
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
4. 视图的优点?
- 查询简单化。视图能简化用户的操作;
- 数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护;
- 逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性。
5. 视图的缺点?
- 性能。数据库必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,数据库也把它变成一个复杂的结合体,需要花费一定的时间。
- 修改限制。当用户试图修改视图的某些行时,数据库必须把它转化为对基本表的某些行的修改。事实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是,对于比较复杂的视图,可能是不可修改的。
这些视图有如下特征:
- 有 UNIQUE 等集合操作符的视图;
- 有 GROUP BY 子句的视图;
- 有诸如 AVG、SUM、MAX 等聚合函数的视图;
- 使用 DISTINCT 关键字的视图;
- 连接表的视图(其中有些例外)。
6. 什么是游标?
游标是系统为用户开设的一个数据缓冲区,存放 SQL 语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理。
7. 如何定位及优化 SQL 语句的性能问题?创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?

8. 大表数据查询,怎么优化?
- 优化 schema、SQL 语句 + 索引;
- 加缓存,如 memcached, redis;
- 主从复制,读写分离;
- 垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
- 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的 sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,SQL 中尽量带 sharding key,将数据定位到限定的表上去查,而不是扫描全部的表。
9. MySQL 分页?
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1)。
mysql> SELECT * FROM table LIMIT 5,10; -- 检索记录行 6-15
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
mysql> SELECT * FROM table LIMIT 95,-1; -- 检索记录行 96-last.
如果只给定一个参数,它表示返回最大的记录行数目:
mysql> SELECT * FROM table LIMIT 5; -- 检索前 5 个记录行
换句话说,LIMIT n 等价于 LIMIT 0,n。
10. 慢查询日志?
用于记录执行时间超过某个临界值的 SQL 日志,用于快速定位慢查询,为我们的优化做参考。
开启慢查询日志
配置项:slow_query_log
可以使用 SHOW VARIABLES LIKE 'slow_query_log' 查看是否开启,如果状态值为 OFF,可以使用 SET GLOBAL slow_query_log = ON 来开启,它会在 datadir 下产生一个 xx-slow.log 的文件。
设置临界时间
配置项:long_query_time
查看:SHOW VARIABLES LIKE 'long_query_time',单位秒
设置:SET long_query_time=0.5
实操时应该从长时间设置到短的时间,即将最慢的 SQL 优化掉。
查看日志,一旦 SQL 超过了我们设置的临界时间就会被记录到 xxx-slow.log 中。
11. 关心过业务系统里面的 SQL 耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是加载了不需要的数据列?还是数据量太大?
优化也是针对这三个方向:
- 首先分析语句,看看是否加载了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写;
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能地命中索引;
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
12. 优化查询过程中的数据访问?
- 访问数据太多导致查询性能下降;
- 确定应用程序是否在检索大量超过需要的数据,可能是太多行或列;
- 确认 MySQL 服务器是否在分析大量不必要的数据行;
- 避免犯如下 SQL 语句错误:
- 查询不需要的数据。解决办法:使用
LIMIT解决; - 多表关联返回全部列。解决办法:指定列名;
- 总是返回全部列。解决办法:避免使用
SELECT *; - 重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存;
- 是否在扫描额外的记录。解决办法:
- 使用
EXPLAIN进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:- 使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果;
- 改变数据库和表的结构,修改数据表范式;
- 重写 SQL 语句,让优化器可以以更优的方式执行查询。
- 使用
- 查询不需要的数据。解决办法:使用
13. 优化长难的查询语句?
- 一个复杂查询还是多个简单查询;
- MySQL 内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多;
- 使用尽可能小的查询是好的,但是有时将一个大的查询分解为多个小的查询是很有必要的;
- 切分查询,将一个大的查询分为多个小的相同的查询;
- 一次性删除 1000 万的数据要比一次删除 1 万,暂停一会的方案更加损耗服务器开销;
- 分解关联查询,让缓存的效率更高。执行单个查询可以减少锁的竞争;
- 在应用层做关联更容易对数据库进行拆分。查询效率会有大幅提升;
- 较少冗余记录的查询。
14. 优化特定类型的查询语句?
COUNT(*)会忽略所有的列,直接统计所有列数,不要使用COUNT(列名);- 在 MyISAM 中,没有任何
WHERE条件的COUNT(*)非常快。当有WHERE条件时,MyISAM 的COUNT统计不一定比其他引擎快; - 可以使用
EXPLAIN查询近似值,用近似值替代COUNT(*); - 增加汇总表;
- 使用缓存。
15. 优化关联查询?
- 确定
ON或USING子句中是否有索引; - 确保
GROUP BY和ORDER BY只有一个表中的列,这样 MySQL 才有可能使用索引。
16. 优化子查询?
- 用关联查询替代;
- 优化
GROUP BY和DISTINCT:- 这两种查询可以使用索引来优化,是最有效的优化方法;
- 关联查询中,使用标识列分组的效率更高;
- 如果不需要
ORDER BY,进行GROUP BY时加ORDER BY NULL,MySQL 不会再进行文件排序; WITH ROLLUP超级聚合,可以挪到应用程序处理。
17. 优化 LIMIT 分页?
LIMIT偏移量大的时候,查询效率较低;- 可以记录上次查询的最大 ID,下次查询时直接根据该 ID 来查询。
18. 优化 UNION 查询?
UNION ALL的效率高于UNION。
19. 优化 WHERE 子句?
- 确保
WHERE子句中的条件能有效利用索引; - 避免在
WHERE子句中进行计算或转换操作,尽量将计算移到查询外部处理。
20. 数据库为什么要优化?
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
- 数据是存放在磁盘上的,读写速度无法和内存相比
- 优化原则:减少系统瓶颈,减少资源占用,增加系统的反应速度。