故障现象
近日有客户找到我们,说有个 ES 集群节点,磁盘利用率达到了 82% ,而其节点才 63% ,想处理下这个节点,降低节点的磁盘利用率。
起初以为是没有打开自动平衡导致的,经查询,数据还是比较平衡的。
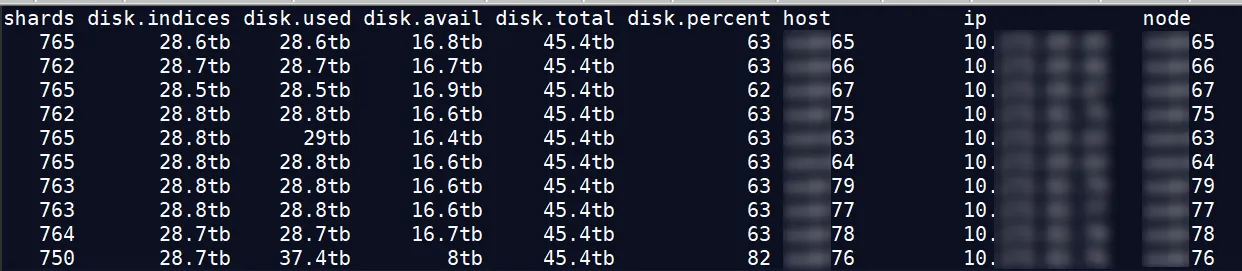
利用率较高的是 76 节点,如果 76 节点的分片比其他节点多,好像还比较合乎逻辑,但它反而比其他节点少了 12-15 个分片。那是 76 节点上的分片比较大?
索引情况

图中都是较大的索引,1 个索引 25TB 左右,共 160 个分片。
分片大小
节点 64

节点 77

节点 75
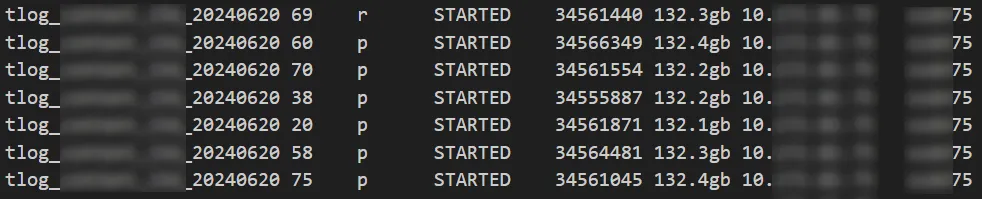
问题节点 76
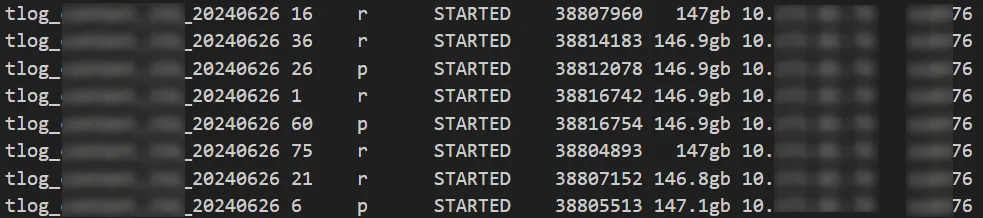
可以看出分片大小没有出现较大的倾斜,分片大小和数据平衡的原因都被排除。
换个方向思考,节点 76 比其他节点多使用了磁盘空间 8 个 TB 左右,集群最大分片大小约 140GB ,8000/140=57 ,即节点 76 至少要比其他节点多 57 个分片才行,啊这...
会不会有其他的文件占用了磁盘空间?
我们登录到节点主机,排查是否有其他文件占用了磁盘空间。
结果:客户的数据路径是单独的数据磁盘,并没有其他文件,都是 ES 集群索引占用的空间。
现象总结
分片大小差不多的情况下,节点 76 的分片数还比别的节点还少 10 个左右,它的磁盘空间反而多占用了 8TB 。
这是不是太奇怪了?事出反常必有妖,继续往下查。
原因定位
通过进一步排查,我们发现节点 76 上有一批索引目录,在其他的节点上没有,而且也不在 GET \_cat/indices?v 命令的结果中。说明这些目录都是 dangling 索引占用的。
dangling 索引产生的原因
当 Elasticsearch 节点脱机时,如果删除的索引数量超过 Cluster.indes.tombstones.size,就会发生这种情况。
解决方案
通过命令删除 dangling 索引:
DELETE /\_dangling/<index-uuid>?accept_data_loss=true
最后
这次的分享就到这里了,欢迎与我一起交流 ES 的各种问题和解决方案。