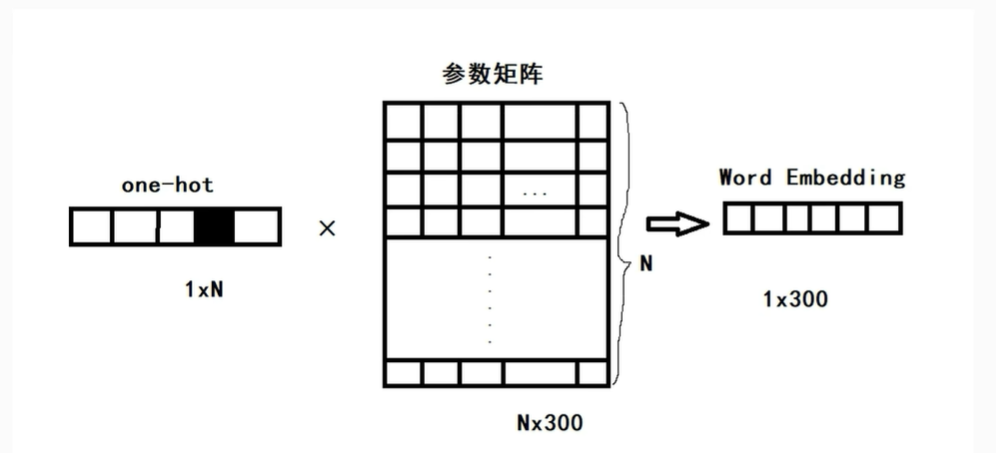
实际上就是去除该矩阵的某一行。该矩阵实际上就是一个有N个词的300维向量,或者说该矩阵就是一个完整的词向量词汇表。而这个词汇表是通过交叉熵损失最小来构造的。
即归根到底是“在特定语料库中(包含context中共现概率),以数学方法计算输入产生哪些输出”最复合“实际情况,即语料库上下文”。这个矩阵实际上是该语料库特定结构决定的。
冥冥之中,是客观世界的相要复合真实,必须采取什么样的映射(矩阵)。亦可以理解为变换即相,因为训练时使用的是one-hot,其实就是选择一行。
也可以看作,无论语料库,还是词向量都是世界的相。语料库词向量的关系在语句中,词向量的相似性在编码中。编码既是词,也包含性质,实际上也蕴含了概率关系。