书接上文:https://www.cnblogs.com/k4n5ha0/p/18314781
最近学习机器学习期间,了解到了向量数据库:

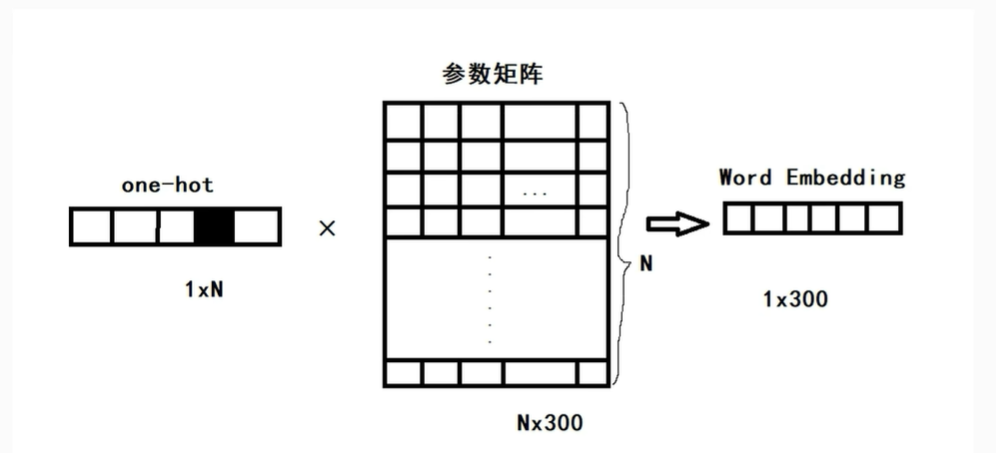
1)可以将文本向量化存储(如上图,将不同语句向量化)
2)在 检索向量的时间复杂 和 对比向量相似度的时间复杂度(例如余弦相似度)充分调优
3)可以调用TPU、GPU等硬件加速运算
4)高度适配向量所以性能明显好于某些插件化支持向量的数据库
所以对上文的设计可以进一步的优化:
1)构建一组安全正则表达式,用户可以根据业务场景选择匹配业务且安全的正则表达式,此类业务数据不再进行存储以及自学习
2)可以对输入值选择“向量判断”选项,选择此选项后网关对该值不再进行正则判定,而进行向量化判定
3)定期搜集、维护、构造各类攻击代码并进行预处理(降噪):
2.1)例如SQL注入需要进行语义处理,去掉注释、异常ASCII、多余的空白字符等并进行格式化后再存储为向量
2.2)XSS进行语义处理,分析html标签、标签属性等进行格式化后存储为向量
2.3)其他log4j、spring4shell、fastjson等恶意poc也进行单独向量化存储
2.4)此类向量记录为denyVector
4)在网关1~2周学习期间:
3.1)启动waf产品将业务数据先过滤
3.2)降噪(上一条(2)中的预处理过程)
3.3)去重
3.4)最后向量化存储,此类向量记录为allowVector
5)学习结束后,对“向量判断”的业务输入进行判断,向量相似性通过计算与 denyVector 和 allowVector 的距离判断是否为恶意请求