⭐️基础链接导航⭐️
☁️ 阿里云活动地址
🐟 上班摸鱼小网站地址
💻 源码库地址
一、前言
大家好呀,我是summo,第一篇已经教会大家怎么去阿里云买服务器,以及怎么搭建JDK、Redis、MySQL这些环境。第二篇我们把后端的应用搭建好了,并且完成了第一个爬虫(抖音)。那么这一篇我会教大家如何将爬取到的数据保存到数据库,并且可以通过接口获取到,为后面的前端界面提供数据源。
二、表结构设计
热搜表结构一览如下

建表语句如下
CREATE TABLE `t_sbmy_hot_search` (`id` bigint(20) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT '物理主键',`hot_search_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '热搜ID',`hot_search_excerpt` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '热搜摘录',`hot_search_heat` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '热搜热度',`hot_search_title` varchar(2048) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '热搜标题',`hot_search_url` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '热搜链接',`hot_search_cover` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '热搜封面',`hot_search_author` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '热搜作者',`hot_search_author_avatar` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '热搜作者头像',`hot_search_resource` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '热搜来源',`hot_search_order` int DEFAULT NULL COMMENT '热搜排名',`gmt_create` datetime DEFAULT NULL COMMENT '创建时间',`gmt_modified` datetime DEFAULT NULL COMMENT '更新时间',`creator_id` bigint DEFAULT NULL COMMENT '创建人',`modifier_id` bigint DEFAULT NULL COMMENT '更新人',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;其中核心字段是
hot_search_id、hot_search_title、hot_search_url、hot_search_heat这四个字段,这几个字段是一定会有值的,其他的字段看热搜接口给不给值,有就填没有就空,把这个建表语句执行一下就可以创建出热搜记录表了。
三、使用插件生成Java对象
Java映射表结构对象的生成有很多方式,这里我推荐使用mybatis插件的方式生成,操作非常简单,一次配好后面的对象都可以这样生成(ps:我用的开发工具是idea社区版)。
1. 在summo-sbmy-dao这个module的resources目录下创建generator目录

2. 在generator目录创建config.properties文件
内容如下
# JDBC链接
jdbc.url=jdbc:mysql://xxx:3306/summo-sbmy?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
# 用户名
jdbc.user=root
# 密码
jdbc.password=xxx
# 表名
table.name=t_sbmy_hot_search
# 对象名
entity.name=SbmyHotSearchDO
# Mapper
mapper.name=SbmyHotSearchMapper
这是一个配置文件,将需要创建Java的对象的表写到这来再设置好对象名即可。
3. 在generator目录创建generatorConfiguration.xml文件
内容如下
<!DOCTYPE generatorConfigurationPUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"><generatorConfiguration><properties resource="generator/config.properties"/><!-- MySQL数据库驱动jar包路径,全路径 --><classPathEntry location="/xxx/mysql-connector-java-8.0.11.jar"/><context id="Mysql" targetRuntime="MyBatis3Simple" defaultModelType="flat"><property name="beginningDelimiter" value="`"/><property name="endingDelimiter" value="`"/><plugin type="tk.mybatis.mapper.generator.MapperPlugin"><property name="mappers" value="com.baomidou.mybatisplus.core.mapper.BaseMapper"/><!-- 插件默认的通用mapper <property name="mappers" itemValue="tk.mybatis.mapper.common.Mapper"/>--><property name="caseSensitive" value="true"/><property name="lombok" value="Getter,Setter,Builder,NoArgsConstructor,AllArgsConstructor"/></plugin><!-- 数据库连接 --><jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"connectionURL="${jdbc.url}"userId="${jdbc.user}" password="${jdbc.password}"/><!-- entity路径 --><javaModelGenerator targetPackage="com.summo.sbmy.dao.entity"targetProject="src/main/java"/><!-- xml路径 --><sqlMapGenerator targetPackage="mybatis/mapper"targetProject="src/main/resources/"><property name="enableSubPackages" value="true"/></sqlMapGenerator><!-- mapper路径 --><javaClientGenerator targetPackage="com.summo.sbmy.dao.mapper"targetProject="src/main/java"type="XMLMAPPER"></javaClientGenerator><!-- 自增ID路径 --><table tableName="${table.name}" domainObjectName="${entity.name}"mapperName="${mapper.name}"><generatedKey column="id" sqlStatement="Mysql" identity="true"/></table></context>
</generatorConfiguration>
这是生成的逻辑规则,设置指定的entity、dao、mapper等文件位置。这两个文件配置好之后,刷新一下maven仓库,插件就会自动识别到了。
4. 双击mybatis-generator:generate生成对象
找到插件执行的位置

双击mybatis-generator:generate就可以生成对应的DO、Mapper、xml了,不过其他的类像controller、service和repository生成不了,需要自己创建。这里最终的目录结构如下

这里的repository代码是我加上去的,插件生成不了,我还加了一个
AbstractBaseDO,它是一个抽象父类,所有的DO都会继承它;还加了一个MetaObjectHandlerConfig,用于对SQL进行切面处理,最后有些代码还有些微调。我把代码贴一下,详情可以见我的代码仓库。
SbmyHotSearchDO.java
package com.summo.sbmy.dao.entity;import java.util.Date;
import javax.persistence.*;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.summo.sbmy.dao.AbstractBaseDO;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;@Getter
@Setter
@TableName("t_sbmy_hot_search")
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ToString
public class SbmyHotSearchDO extends AbstractBaseDO<SbmyHotSearchDO> {/*** 物理主键*/@TableId(type = IdType.AUTO)private Long id;/*** 热搜标题*/@Column(name = "hot_search_title")private String hotSearchTitle;/*** 热搜作者*/@Column(name = "hot_search_author")private String hotSearchAuthor;/*** 热搜来源*/@Column(name = "hot_search_resource")private String hotSearchResource;/*** 热搜排名*/@Column(name = "hot_search_order")private Integer hotSearchOrder;/*** 热搜ID*/@Column(name = "hot_search_id")private String hotSearchId;/*** 热搜热度*/@Column(name = "hot_search_heat")private String hotSearchHeat;/*** 热搜链接*/@Column(name = "hot_search_url")private String hotSearchUrl;/*** 热搜封面*/@Column(name = "hot_search_cover")private String hotSearchCover;/*** 热搜作者头像*/@Column(name = "hot_search_author_avatar")private String hotSearchAuthorAvatar;/*** 热搜摘录*/@Column(name = "hot_search_excerpt")private String hotSearchExcerpt;
}
SbmyHotSearchMapper.java
package com.summo.sbmy.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface SbmyHotSearchMapper extends BaseMapper<SbmyHotSearchDO> {
}
SbmyHotSearchRepository.java
package com.summo.sbmy.dao.repository;import com.baomidou.mybatisplus.extension.service.IService;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;public interface SbmyHotSearchRepository extends IService<SbmyHotSearchDO> {
}SbmyHotSearchRepositoryImpl.java
package com.summo.sbmy.dao.repository.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import com.summo.sbmy.dao.mapper.SbmyHotSearchMapper;
import com.summo.sbmy.dao.repository.SbmyHotSearchRepository;
import org.springframework.stereotype.Repository;@Repository
public class SbmyHotSearchRepositoryImpl extends ServiceImpl<SbmyHotSearchMapper, SbmyHotSearchDO>implements SbmyHotSearchRepository {}AbstractBaseDO.java
package com.summo.sbmy.dao;import java.io.Serializable;
import java.util.Date;import com.baomidou.mybatisplus.annotation.FieldFill;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.Getter;
import lombok.Setter;@Getter
@Setter
public class AbstractBaseDO<T extends Model<T>> extends Model<T> implements Serializable {/*** 创建时间*/@TableField(fill = FieldFill.INSERT)private Date gmtCreate;/*** 修改时间*/@TableField(fill = FieldFill.INSERT_UPDATE)private Date gmtModified;/*** 创建人ID*/@TableField(fill = FieldFill.INSERT)private Long creatorId;/*** 修改人ID*/@TableField(fill = FieldFill.INSERT_UPDATE)private Long modifierId;
}MetaObjectHandlerConfig.java
package com.summo.sbmy.dao;import java.util.Calendar;
import java.util.Date;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.context.annotation.Configuration;@Configuration
public class MetaObjectHandlerConfig implements MetaObjectHandler {@Overridepublic void insertFill(MetaObject metaObject) {Date date = Calendar.getInstance().getTime();this.fillStrategy(metaObject, "gmtCreate", date);this.fillStrategy(metaObject, "gmtModified", date);}@Overridepublic void updateFill(MetaObject metaObject) {Date date = Calendar.getInstance().getTime();this.setFieldValByName("gmtModified", date, metaObject);}
}
SbmyHotSearchMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.summo.sbmy.dao.mapper.SbmyHotSearchMapper"><resultMap id="BaseResultMap" type="com.summo.sbmy.dao.entity.SbmyHotSearchDO"><!--WARNING - @mbg.generated--><id column="id" jdbcType="BIGINT" property="id" /><result column="hot_search_title" jdbcType="VARCHAR" property="hotSearchTitle" /><result column="hot_search_author" jdbcType="VARCHAR" property="hotSearchAuthor" /><result column="hot_search_resource" jdbcType="VARCHAR" property="hotSearchResource" /><result column="hot_search_order" jdbcType="INTEGER" property="hotSearchOrder" /><result column="gmt_create" jdbcType="TIMESTAMP" property="gmtCreate" /><result column="gmt_modified" jdbcType="TIMESTAMP" property="gmtModified" /><result column="creator_id" jdbcType="BIGINT" property="creatorId" /><result column="modifier_id" jdbcType="BIGINT" property="modifierId" /><result column="hot_search_id" jdbcType="VARCHAR" property="hotSearchId" /><result column="hot_search_heat" jdbcType="VARCHAR" property="hotSearchHeat" /><result column="hot_search_url" jdbcType="LONGVARCHAR" property="hotSearchUrl" /><result column="hot_search_cover" jdbcType="LONGVARCHAR" property="hotSearchCover" /><result column="hot_search_author_avatar" jdbcType="LONGVARCHAR" property="hotSearchAuthorAvatar" /><result column="hot_search_excerpt" jdbcType="LONGVARCHAR" property="hotSearchExcerpt" /></resultMap>
</mapper>
四、热搜数据存储
1. 唯一ID生成
上一篇的最后我们把抖音的热搜数据给获取到了,这里表结构也设计好了,到存储逻辑就变得简单很多了。这个有一个点需要注意下,由于抖音的热搜没有自带唯一ID,为了不重复添加,我们需要手动给热搜设置一个ID,生成ID的算法如下:
/*** 根据文章标题获取一个唯一ID** @param title 文章标题* @return 唯一ID*/
public static String getHashId(String title) {long seed = title.hashCode();Random rnd = new Random(seed);return new UUID(rnd.nextLong(), rnd.nextLong()).toString();
}public static void main(String[] args) {System.out.println(getHashId("当你有一只肥猫就会很显瘦"));System.out.println(getHashId("当你有一只肥猫就会很显瘦"));System.out.println(getHashId("当你有一只肥猫就会很显瘦"));System.out.println(getHashId("当你有一只肥猫就会很显瘦"));
}
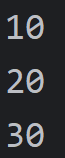
运行这串逻辑,输出一下代码

从输出结果来看,同一个标题获取的hashId都是一样的,可以满足我们的要求。
2. 数据存储流程
保存的逻辑流程如下图,核心就是根据那个唯一ID去数据库查询一下,有就跳过,没有就保存。

DouyinHotSearchJob代码如下
package com.summo.sbmy.job.douyin;import java.io.IOException;
import java.util.List;
import java.util.Random;
import java.util.UUID;import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;import com.google.common.collect.Lists;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import com.summo.sbmy.service.SbmyHotSearchService;
import lombok.extern.slf4j.Slf4j;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import static com.summo.sbmy.common.enums.HotSearchEnum.DOUYIN;/*** @author summo* @version DouyinHotSearchJob.java, 1.0.0* @description 抖音热搜Java爬虫代码* @date 2024年08月09*/
@Component
@Slf4j
public class DouyinHotSearchJob {@Autowiredprivate SbmyHotSearchService sbmyHotSearchService;/*** 定时触发爬虫方法,1个小时执行一次*/@Scheduled(fixedRate = 1000 * 60 * 60)public void hotSearch() throws IOException {try {//查询抖音热搜数据OkHttpClient client = new OkHttpClient().newBuilder().build();Request request = new Request.Builder().url("https://www.iesdouyin.com/web/api/v2/hotsearch/billboard/word/").method("GET", null).build();Response response = client.newCall(request).execute();JSONObject jsonObject = JSONObject.parseObject(response.body().string());JSONArray array = jsonObject.getJSONArray("word_list");List<SbmyHotSearchDO> sbmyHotSearchDOList = Lists.newArrayList();for (int i = 0, len = array.size(); i < len; i++) {//获取知乎热搜信息JSONObject object = (JSONObject)array.get(i);//构建热搜信息榜SbmyHotSearchDO sbmyHotSearchDO = SbmyHotSearchDO.builder().hotSearchResource(DOUYIN.getCode()).build();//设置文章标题sbmyHotSearchDO.setHotSearchTitle(object.getString("word"));//设置抖音三方IDsbmyHotSearchDO.setHotSearchId(getHashId(DOUYIN.getCode() + sbmyHotSearchDO.getHotSearchTitle()));//设置文章连接sbmyHotSearchDO.setHotSearchUrl("https://www.douyin.com/search/" + sbmyHotSearchDO.getHotSearchTitle() + "?type=general");//设置热搜热度sbmyHotSearchDO.setHotSearchHeat(object.getString("hot_value"));//按顺序排名sbmyHotSearchDO.setHotSearchOrder(i + 1);sbmyHotSearchDOList.add(sbmyHotSearchDO);}//数据持久化sbmyHotSearchService.saveCache2DB(sbmyHotSearchDOList);} catch (IOException e) {log.error("获取抖音数据异常", e);}}/*** 根据文章标题获取一个唯一ID** @param title 文章标题* @return 唯一ID*/public static String getHashId(String title) {long seed = title.hashCode();Random rnd = new Random(seed);return new UUID(rnd.nextLong(), rnd.nextLong()).toString();}}
这里的爬虫代码我做了微调,去掉了一些不必要的header和cookie。
数据存储逻辑如下
@Override
public Boolean saveCache2DB(List<SbmyHotSearchDO> sbmyHotSearchDOS) {if (CollectionUtils.isEmpty(sbmyHotSearchDOS)) {return Boolean.TRUE;}//查询当前数据是否已经存在List<String> searchIdList = sbmyHotSearchDOS.stream().map(SbmyHotSearchDO::getHotSearchId).collect(Collectors.toList());List<SbmyHotSearchDO> sbmyHotSearchDOList = sbmyHotSearchRepository.list(new QueryWrapper<SbmyHotSearchDO>().lambda().in(SbmyHotSearchDO::getHotSearchId, searchIdList));//过滤已经存在的数据if (CollectionUtils.isNotEmpty(sbmyHotSearchDOList)) {List<String> tempIdList = sbmyHotSearchDOList.stream().map(SbmyHotSearchDO::getHotSearchId).collect(Collectors.toList());sbmyHotSearchDOS = sbmyHotSearchDOS.stream().filter(sbmyHotSearchDO -> !tempIdList.contains(sbmyHotSearchDO.getHotSearchId())).collect(Collectors.toList());}if (CollectionUtils.isEmpty(sbmyHotSearchDOS)) {return Boolean.TRUE;}log.info("本次新增[{}]条数据", sbmyHotSearchDOS.size());//批量添加return sbmyHotSearchRepository.saveBatch(sbmyHotSearchDOS);
}
这里代码就是我们常说的CRUD了,感觉没有什么可讲的,具体的代码看仓库。
五、小结一下
由于我们这是一个项目,有很多框架级和工程化的东西,细节非常多,如果我把代码全贴出来,那文章估计没法看了,所以后续的文章我只会贴一些核心的代码和逻辑。主要是有些东西没法一时半会跟你们讲清楚,牵扯到脚手架的设计,所以你们先姑妄看之,先一股脑的把代码复制进来,有不理解的地方我可以后面单开文章介绍和解释,讲我为什么要这样做以及这样做有啥好处。
除了代码之外,我还会教大家一些插件的使用,比如上面这个代码生成器,类似于这样的东西我还会很多,我会在后面的文章中慢慢贴出来,让大家学到一些真正好用和好玩的东西。并且从这一篇开始我会放出我的仓库地址,后续的代码会持续更新到这个仓库,由于Github很多人都没法访问,我就用国内的Gitee吧,地址如下:。
番外:百度热搜爬虫
1. 爬虫方案评估
百度热搜是这样的, 接口是:https://top.baidu.com/board?tab=realtime&sa=fyb_realtime_31065

可以看到数据还是很完备的,标题、封面、热度、摘要都有,但是百度热搜和抖音热搜不一样,这个接口返回的HTML网页不是JSON数据,所以我们需要使用处理HTML标签的包:
jsoup,依赖如下:
<!-- jsoup -->
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.12.1</version>
</dependency>
2. 网页解析代码
这个用Postman就不太好使了,我们直接用jsonp进行调用,不逼逼逻辑了,直接上代码,BaiduHotSearchJob:
package com.summo.sbmy.job.baidu;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import com.summo.sbmy.service.SbmyHotSearchService;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import static com.summo.sbmy.common.enums.HotSearchEnum.BAIDU;/*** @author summo* @version BaiduHotSearchJob.java, 1.0.0* @description 百度热搜Java爬虫代码* @date 2024年08月19*/
@Component
@Slf4j
public class BaiduHotSearchJob {@Autowiredprivate SbmyHotSearchService sbmyHotSearchService;/*** 定时触发爬虫方法,1个小时执行一次*/@Scheduled(fixedRate = 1000 * 60 * 60)public void hotSearch() throws IOException {try {//获取百度热搜String url = "https://top.baidu.com/board?tab=realtime&sa=fyb_realtime_31065";List<SbmyHotSearchDO> sbmyHotSearchDOList = new ArrayList<>();Document doc = Jsoup.connect(url).get();//标题Elements titles = doc.select(".c-single-text-ellipsis");//图片Elements imgs = doc.select(".category-wrap_iQLoo .index_1Ew5p").next("img");//内容Elements contents = doc.select(".hot-desc_1m_jR.large_nSuFU");//推荐图Elements urls = doc.select(".category-wrap_iQLoo a.img-wrapper_29V76");//热搜指数Elements levels = doc.select(".hot-index_1Bl1a");for (int i = 0; i < levels.size(); i++) {SbmyHotSearchDO sbmyHotSearchDO = SbmyHotSearchDO.builder().hotSearchResource(BAIDU.getCode()).build();//设置文章标题sbmyHotSearchDO.setHotSearchTitle(titles.get(i).text().trim());//设置百度三方IDsbmyHotSearchDO.setHotSearchId(getHashId(BAIDU.getDesc() + sbmyHotSearchDO.getHotSearchTitle()));//设置文章封面sbmyHotSearchDO.setHotSearchCover(imgs.get(i).attr("src"));//设置文章摘要sbmyHotSearchDO.setHotSearchExcerpt(contents.get(i).text().replaceAll("查看更多>", ""));//设置文章连接sbmyHotSearchDO.setHotSearchUrl(urls.get(i).attr("href"));//设置热搜热度sbmyHotSearchDO.setHotSearchHeat(levels.get(i).text().trim());//按顺序排名sbmyHotSearchDO.setHotSearchOrder(i + 1);sbmyHotSearchDOList.add(sbmyHotSearchDO);}//数据持久化sbmyHotSearchService.saveCache2DB(sbmyHotSearchDOList);} catch (IOException e) {log.error("获取百度数据异常", e);}}/*** 根据文章标题获取一个唯一ID** @param title 文章标题* @return 唯一ID*/public static String getHashId(String title) {long seed = title.hashCode();Random rnd = new Random(seed);return new UUID(rnd.nextLong(), rnd.nextLong()).toString();}}其实网页版的数据爬虫也不难,关键就看你能不能快速找到存数据的标签,然后通过选择器获取到标签的属性或内容,Jsoup框架在解析dom是很好用的,也常用在爬虫代码中。