深度学习基础
学习目标
- 理解深度学习的常见概念。
- 掌握优化神经网络的方法。
- 找到优化神经网络失败的原因。
- 学习调整学习率(lr)的高级方法。
1、局部极小值与鞍点
在局部极小值与鞍点之前,首先了解一个特殊的点-临界点。
1.1 临界点
通常将梯度为零的点统称为“临界点”。什么时候梯度为零?
梯度为零的点通常称为“临界点”,在这些点上,函数的变化率为零。数学上,对于一个多变量函数 $ \ f(x) $,梯度为零的点$ \mathbf{x} $ 满足 \(\nabla f(\mathbf{x}) = 0\)。这意味着在该点,函数在所有方向上的偏导数都为零,表示可能是局部极值点、鞍点或平坦区域的点。
注 :在局部极值点中大家很容易忽略的就是局部极大值,大家习惯性的默认是极小值点。
在下图所示的为一个鞍点,在(0, 0) 是一个临界点,并不是极值点。
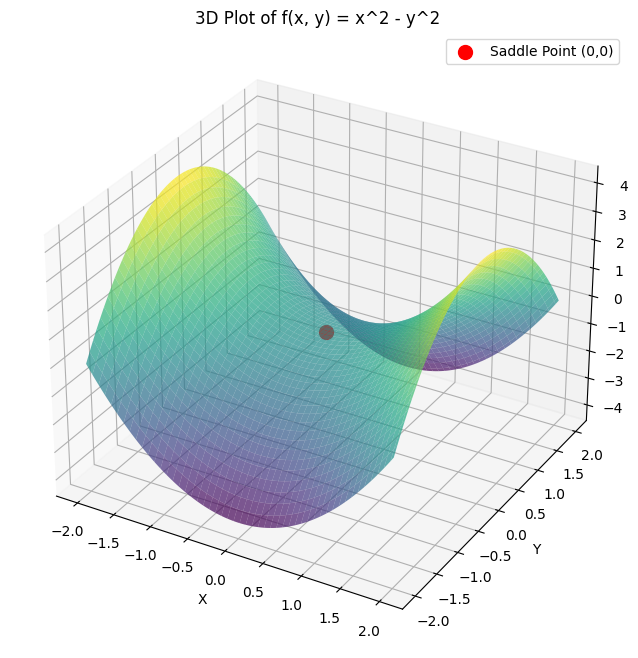
现在有一个值得思考的问题就是如何区分这个临界点是那种类型的点?
通过百度几乎都是通过海森矩阵来区分的。但是海森矩阵太复杂看不懂!!!!
换个思路,对于低维的函数我们可以去绘制函数图像去分析。面对高维的怎么办?
import numpy as np
from scipy.linalg import eigvalsdef hessian(func, x0, epsilon=1e-5):n = len(x0)hess = np.zeros((n, n))f0 = func(x0)for i in range(n):x0i = x0.copy()x0i[i] += epsilonf0i = func(x0i)for j in range(n):x0ij = x0.copy()x0ij[j] += epsilonf0ij = func(x0ij)x0i_j = x0.copy()x0i_j[j] += epsilonf0i_j = func(x0i_j)hess[i, j] = (f0i_j - f0i - f0ij + f0) / (epsilon**2)return hess# 定义函数分析
def func(x):return x[0]**5 + x[1]**2 - 4*x[0]*x[1] + x[1]**2# 示例点
x0 = np.array([11.0, 2.0])
hess = hessian(func, x0)
eigvals = eigvals(hess)# 判断类型
if np.all(eigvals > 0):print("局部极小值点")
elif np.all(eigvals < 0):print("局部极大值点")
elif np.any(eigvals > 0) and np.any(eigvals < 0):print("鞍点")
else:print("无法确定类型")看不懂的我求助了AI,让它帮忙生成了代码,嘤嘤嘤
通过上述的例子,了解到鞍点对于学习来说不友好,在高维空间中,鞍点可以让优化过程陷入困境。如何处理鞍点或者“逃离”呢?
-
随机梯度下降(SGD):由于其随机性,SGD可以通过噪声帮助避免在鞍点附近停滞。
-
动量方法(Momentum):通过引入历史梯度的加权平均来加速优化过程,减少被鞍点困住的可能性。
-
自适应学习率方法(如 Adam、RMSprop):通过调整每个参数的学习率,能够更快地离开鞍点。
2、动量
在动量方法中,“动量”指的是历史梯度的加权平均。这个“动量”帮助加速优化过程,同时减少震荡,使得更新更稳定,从而更有效地避免被鞍点困住。
注 :在计算梯度的时候,并不是对所有数据的损失 $L $计算梯度,而是把所有的数据分成一个一个的批量(batch),遍历所有批量的过程称为一个回合(epoch).
在分散数据时,分成每一个批量的大小如何确定?如何限制?
2.1 批量
1、选择批量大小的考虑因素
- 计算资源:
内存限制:较大的批量大小会占用更多的内存,因此需要考虑显存(GPU)或内存(CPU)的容量。
计算效率:较大的批量大小可以利用并行计算加速训练,但过大的批量可能导致内存溢出或计算效率的下降。 - 模型收敛性:
小批量:通常会引入更多的噪声,有助于跳出局部最优解,但训练过程可能较慢,收敛路径较为震荡。
大批量:收敛过程更平滑,训练更加稳定,但可能会导致陷入局部最优解。 - 训练时间:
较大的批量大小通常能提高每次迭代的计算效率,从而减少训练的总时间。但是,需要平衡计算资源的利用和收敛速度。
2、 常见选择策略
-
经验法则:许多实践经验表明,批量大小的选择可以从 32、64、128 等常见值开始尝试。具体的最优值通常需要通过实验和调整确定。
-
逐步增大:从较小的批量大小开始训练,逐步增加,观察训练稳定性和模型性能。
-
学习率调整:如果增加批量大小,也可以尝试相应地调整学习率。例如,有研究表明,在批量大小增加时,适当增大学习率有助于更快的收敛
3 梯度下降
梯度下降(Gradient Descent)是一种用于优化模型参数的迭代算法,广泛应用于机器学习和深度学习中。其主要目标是最小化一个损失函数,使得模型的预测与实际值之间的差距最小化。
梯度下降的步骤:
初始化参数:选择初始参数值(通常是随机的)。
计算梯度:根据当前参数值计算损失函数的梯度(即损失函数相对于每个参数的偏导数)。
更新参数:根据计算得到的梯度调整参数值。更新公式为:
\(θ←θ−η∇_θJ(θ)\)
重复:重复计算梯度和更新参数的过程,直到满足停止条件(如损失函数收敛或达到最大迭代次数)。
梯度下降的变体
-
批量梯度下降(Batch Gradient Descent):
在每次迭代中使用整个训练集来计算梯度。适合较小的训练集,但在大规模数据集上计算成本高。 -
随机梯度下降(Stochastic Gradient Descent, SGD):
在每次迭代中仅使用一个样本来计算梯度。虽然每次更新的方向可能比较嘈杂,但通常可以更快地达到收敛。 -
小批量梯度下降(Mini-batch Gradient Descent):
结合了批量梯度下降和随机梯度下降的优点,每次迭代中使用训练集的一部分(小批量)来计算梯度。这样可以在一定程度上平衡计算效率和收敛性。
小批量梯度下降与批量梯度下降的比较

4 自适应学习率
一些先进的优化算法可以自动调整学习率,进一步提高训练效率:
- AdaGrad:根据每个参数的历史梯度调整学习率,使得频繁更新的参数学习率降低,不常更新的参数学习率增加。
- RMSprop:改进了AdaGrad,通过引入指数衰减来计算梯度的平方均值,防止学习率过快下降。
- Adam(Adaptive Moment Estimation):结合了动量法和RMSprop的优点,通过计算一阶矩(梯度均值)和二阶矩(梯度平方均值)来调整学习率。
自适应学习率在代码中的使用方法:
- TensorFlow/Keras
import torch.optim as optim# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 使用RMSprop优化器
optimizer = optim.RMSprop(model.parameters(), lr=0.001)# 使用Adagrad优化器
optimizer = optim.Adagrad(model.parameters(), lr=0.01)# 在训练过程中使用优化器
for epoch in range(num_epochs):optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()- PyTorch
import torch.optim as optim# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 使用RMSprop优化器
optimizer = optim.RMSprop(model.parameters(), lr=0.001)# 使用Adagrad优化器
optimizer = optim.Adagrad(model.parameters(), lr=0.01)# 在训练过程中使用优化器
for epoch in range(num_epochs):optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()- scikit-learn
from sklearn.linear_model import SGDClassifier# 使用Adam优化器
model = SGDClassifier(learning_rate='adaptive', eta0=0.001, loss='log')model.fit(X_train, y_train)在scikit-learn中,通常不直接使用这些自适应学习率算法,但某些模型如SGDClassifier和SGDRegressor支持不同的优化算法。








![[消息队列]kafka](https://img2024.cnblogs.com/blog/1533409/202408/1533409-20240823214605244-1660175957.png)