什么是 Quickwit?
Quickwit 是首个能在云端存储上直接执行复杂的搜索与分析查询的引擎,并且具有亚秒级延迟。它借助 Rust 语言和分离计算与存储的架构设计,旨在实现资源高效利用、易于操作以及能够扩展到 PB 级数据量。
Quickwit 非常适合日志管理、分布式追踪以及通常为不可变数据的应用场景,例如对话数据(电子邮件、文本消息、消息平台)和基于事件的分析。
为什么 Quickwit 与其他搜索引擎不同?
Quickwit 专为从对象存储中实现亚秒级搜索而设计,真正实现了计算与存储的分离。这对您的基础设施来说意义重大:
- 您只需一次存储即可满足所有数据需求,使用廉价、安全且容量无限的存储。
- 您可以在几秒钟内扩展集群规模,无需移动数据。
- 索引和搜索工作负载相互独立,您可以独立地进行扩展。
- 您可以轻松隔离各个租户,并根据他们的使用情况向他们收费。
Quickwit 还专为索引和搜索半结构化数据而设计。其无模式索引功能允许您索引包含任意数量字段的 JSON 文档,而不会严重影响性能。虽然目前还不支持聚合功能,但我们正在努力开发中,请持续关注!
何时使用 Quickwit
Quickwit 非常适合日志管理、分布式追踪以及通常为不可变数据的应用场景,例如对话数据(电子邮件、文本消息、消息平台)、基于事件的分析、审计日志、安全日志等。
查看我们的指南以了解如何使用 Quickwit:
- 日志管理
- https://quickwit.io/docs/log-management/overview
- 分布式追踪
- https://quickwit.io/docs/distributed-tracing/overview
- 为 OLAP 数据库如 ClickHouse 添加全文搜索功能。
- https://quickwit.io/docs/guides/add-full-text-search-to-your-olap-db
关键特性
- 全文搜索和聚合查询
- 支持 Elasticsearch 查询语言
- 在云端存储上实现亚秒级搜索(Amazon S3、Azure Blob 存储等)
- 分离计算与存储,无状态索引器与搜索器
- Schemaless(无模式) 或严格模式索引
- https://quickwit.io/docs/guides/schemaless
- 无模式分析
- Grafana 数据源
- https://github.com/quickwit-oss/quickwit-datasource
- Jaeger 原生支持
- https://quickwit.io/docs/distributed-tracing/plug-quickwit-to-jaeger
- OTEL 原生支持 日志 和 追踪
- https://quickwit.io/docs/log-management/overview
- https://quickwit.io/docs/distributed-tracing/overview
- Kubernetes 就绪 - 查看我们的 helm-chart
- https://quickwit.io/docs/deployment/kubernetes
- RESTful API
企业级特性
- 多种 数据源 Kafka / Kinesis / Pulsar 原生支持
- https://quickwit.io/docs/ingest-data
- 多租户:支持多个索引和分区索引
- 保留策略
- 删除任务(用于 GDPR 场景)
- 分布式且高度可用的引擎,可在几秒钟内扩展(仅 Kafka 支持 HA 索引)
不宜使用 Quickwit 的情况
以下是一些您可能不想使用 Quickwit 的应用场景:
- 您需要为电子商务网站提供低延迟搜索。
- 您的数据是可变的。
开始探索 Quickwit
- 快速入门
- https://quickwit.io/docs/get-started/quickstart
- 概念
- https://quickwit.io/docs/overview/architecture
- 最新版本博客文章
- https://quickwit.io/blog/quickwit-0.7
架构
Quickwit 分布式搜索引擎依赖于四个主要服务和一个维护服务:
- Searchers (搜索器):通过 REST API 执行搜索查询。
- Indexers (索引器):从数据源对数据进行索引。
- Metastore (元存储):在类似 PostgreSQL 的数据库或云端存储文件中存储索引元数据。
- Control plane(控制平面):调度索引任务给索引器。
- Janitor(清理程序):执行周期性的维护任务。
此外,Quickwit 利用现有的基础设施,依靠经过验证的技术来实现索引存储、元数据存储和数据摄取:
- 云端存储:如 AWS S3、Google Cloud Storage、Azure Blob Storage 或其他兼容 S3 的存储用于索引存储。
- PostgreSQL:用于元数据存储。
- 分布式队列:如 Kafka 和 Pulsar 用于数据摄取。
架构图
下图展示了 Quickwit 集群及其四大组件和清理程序,清理程序的作用是执行周期性的维护任务,更多详情请参见清理程序部分。
- https://quickwit.io/docs/overview/architecture#janitor

Index & splits(索引与分片)
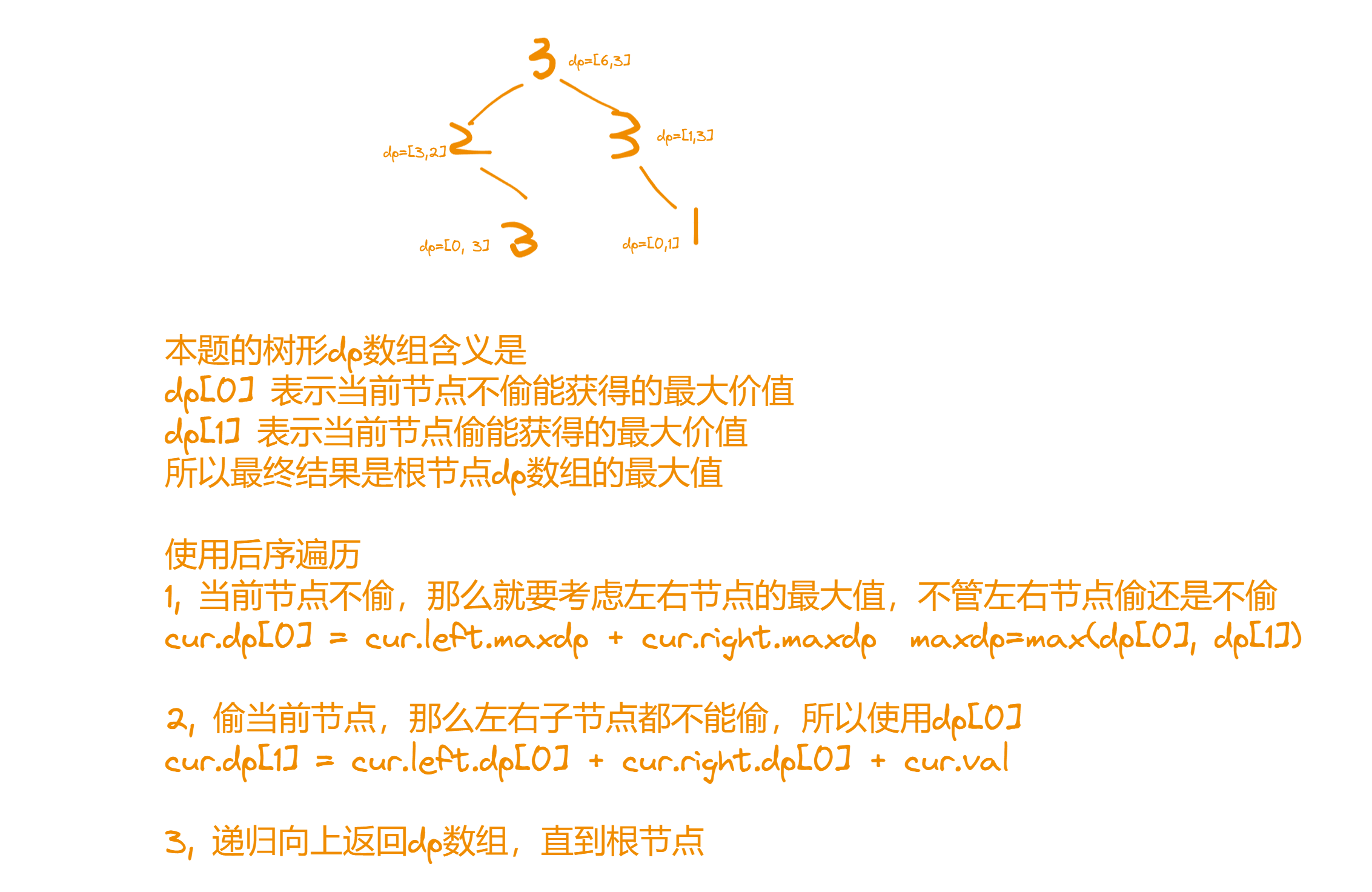
Quickwit 索引存储文档并使其能够被高效查询。索引将文档组织成一系列较小的独立索引,称为splits(分片)。
文档是一组字段的集合。字段可以存储在不同的数据结构中:
- 倒排索引:使全文搜索变得快速。
- 列式存储,称为
fast field。这相当于 Lucene 中的 doc values。Fast fields 用于计算匹配查询的文档上的聚合。它们还可以允许一些高级类型的过滤。- https://lucene.apache.org/
- 行存储,称为文档存储。它使得获取匹配文档的内容成为可能。
您可以配置索引来控制如何将 JSON 对象映射到 Quickwit 文档,并为每个字段定义是否应存储、索引或作为 fast field。了解如何配置您的索引
- https://quickwit.io/docs/configuration/index-config
Splits(分片)
分片是索引的一个小部分,通过 UUID 来标识。对于每个分片,Quickwit 会添加一个 hotcache 文件与索引文件一起。这个 hotcache 使得搜索器能够在不到 60 毫秒的时间内打开分片,即使是在高延迟存储上也是如此。
Quickwit 索引通过维护分片元数据来识别其分片,特别是:
- 分片的状态,指示分片是否已准备好进行搜索。
- 如果存在时间戳字段,则计算出的最小/最大时间范围。
这些时间戳元数据在查询时非常有用。如果用户在其查询中指定了时间范围过滤器,Quickwit 将使用它来剔除无关的分片。
索引元数据需要对集群中的每个实例都可访问。这是通过 元存储 实现的。
Index storage(索引存储)
Quickwit 将索引数据(分片文件)存储在云端存储(AWS S3、Google Cloud Storage、Azure Blob Storage 或其他兼容 S3 的存储)上,并且在单服务器部署中也会存储在本地磁盘上。
Metastore(元存储)
Quickwit 将索引元数据汇总到元存储中,以便在整个集群中都能访问这些元数据。
在写入路径上,索引器将索引数据推送到索引存储,并将元数据发布到元存储。
在读取路径上,对于特定索引上的特定查询,搜索节点会向元存储请求索引元数据,然后使用这些元数据来进行查询规划,并最终执行该计划。
在集群部署中,元存储通常是传统的 RDBMS,比如 PostgreSQL,这是我们当前唯一支持的选项。在单服务器部署中,也可以依赖本地文件或 Amazon S3。
Quickwit 集群和服务
集群形成
Quickwit 使用 chitchat,这是一种由 Quickwit 实现的带有故障检测功能的集群成员协议。该协议受到了 Scuttlebutt 协调和 phi-accrual 检测的启发,这些想法借鉴自 Cassandra 和 DynamoDB。
了解更多关于 chitchat。
- https://github.com/quickwit-oss/chitchat
Indexers(索引器)
请参阅 专门的索引文档页面。
- https://quickwit.io/docs/overview/concepts/indexing
Searchers(搜索器)
Quickwit 的搜索集群具有以下特点:
- 它由无状态节点组成:任何节点都可以回答关于任何分片的任何查询。
- 节点可以将搜索工作负载分配给其他节点。
- 负载均衡通过 rendezvous 哈希实现,以允许高效的缓存。
这种设计提供了高可用性,同时保持架构简单。
工作负载分配:根节点和叶节点
任何搜索节点都可以处理任何搜索请求。接收查询的节点将在请求期间充当根节点。然后,它将按照以下三个步骤处理查询:
- 从元存储获取索引元数据,并确定与查询相关的分片。
- 在集群的节点之间分配分片工作负载。这些节点承担叶节点的角色。
- 等待来自叶节点的结果,合并它们,并返回聚合结果。
Stateless nodes(无状态节点)
Quickwit 集群在保持节点无状态的同时分配搜索工作负载。
得益于 hotcache,即使是在 Amazon S3 上打开分片也只需要 60 毫秒。这使得完全无状态成为可能:节点不需要了解任何索引信息。添加或移除节点只需几秒钟,而且不需要移动数据。
Rendezvous 哈希
根节点使用 rendezvous 哈希在叶节点之间分配工作负载。rendezvous 哈希使得可以在节点加入或离开集群时定义具有出色稳定性特性的节点/分片亲和力函数。这一技巧解锁了高效的缓存。
- https://en.wikipedia.org/wiki/Rendezvous_hashing
在 查询文档页面 上了解更多关于查询内部细节的信息。
- https://quickwit.io/docs/overview/concepts/querying
Control plane(控制平面)
控制平面服务负责调度索引任务给索引器。调度会在调度器接收到外部或内部事件以及满足某些条件时执行:
- 调度器监听元存储事件:创建源、删除源、切换源或删除索引。在这些事件发生时,它会调度一个新的计划,称为“期望计划”,并将索引任务发送给索引器。
- 每个
HEARTBEAT(3 秒)时,调度器检查“期望计划”与索引器上运行的索引任务是否同步。如果不一致,它将重新应用期望计划给索引器。 - 每分钟,调度器根据最新的元存储状态重建一个计划,如果与上次应用的计划不同,它将应用新的计划。这是必要的,因为调度器可能由于网络问题而未接收到所有元存储事件。
Janitor(清理程序)
清理程序服务在索引上运行维护任务:垃圾收集、删除查询任务和保留策略任务。
Data sources(数据源)
Quickwit 支持 多种数据源 来摄取数据。
- https://quickwit.io/docs/ingest-data
文件非常适合一次性摄取,例如初始加载;摄取 API 或消息队列则非常适合持续地向系统喂送数据。
Quickwit 索引器直接连接到外部消息队列,如 Kafka、Pulsar 或 Kinesis,并保证恰好一次(exactly-once)的语义。如果您需要支持其他分布式队列,请在此 链接 中投票选择您需要的支持。
- https://github.com/quickwit-oss/quickwit/issues/1000
高级概念
Indexing(索引)
支持的数据格式
Quickwit 摄取 JSON 记录,并将其称为“文档”或“docs”。每个文档必须是一个 JSON 对象。在摄取文件时,文档之间必须用换行符分隔。
Quickwit 目前还不支持如 Avro 或 CSV 这样的文件格式。压缩格式如 bzip2 或 gzip 也不受支持。
Data model(数据模型)
Quickwit 支持无模式索引和固定模式。索引的“文档映射”(通常也称为“doc 映射”)是一份字段名称和类型的列表,用于声明索引的模式。对于无模式或混合固定模式与无模式索引,请遵循我们的 无模式索引指南。此外,文档映射还指定了文档如何被索引(标记器)和存储(列式 vs. 行式)的方式。
- https://quickwit.io/docs/guides/schemaless
合并过程与合并策略
索引被分割成不可变的分片。分片的大小由其携带的文档数量决定。当分片的大小达到索引配置中定义的阈值 split_num_docs_target 时,该分片被视为“成熟”。
索引器缓冲传入的文档,并在缓冲区的大小达到 split_num_docs_target 或者自第一个文档被排队以来经过了 commit_timeout_secs 秒时生成一个新的分片,具体取决于哪个事件先发生。在这种情况下,索引器会产生不成熟的分片。合并过程是指将不成熟的分片分组并合并在一起以产生成熟分片的迭代过程。
合并策略控制合并算法,该算法主要由两个参数驱动:split_num_docs_target 和 merge_factor。每当有新的分片发布时,合并策略都会检查不成熟分片的列表,并尝试将 merge_factor 个分片合并在一起以产生更大的分片。合并策略也可能根据需要决定合并更少或更多的分片。最后,合并算法永远不会合并超过 max_merge_factor 个分片。
Split store(分片存储)
分片存储是一个缓存,它将最近发布的和不成熟的分片保留在磁盘上以加快合并过程。在一个成功的合并阶段之后,分片存储会清除悬空的分片。
分配给分片存储的磁盘空间由配置参数 split_store_max_num_splits 和 split_store_max_num_bytes 控制。
Data sources(数据源)
数据源指定可以从外部数据存储(可以是文件、流或数据库)连接和摄取数据的位置和一组参数。通常,Quickwit 简单地将数据源称为“源”。索引引擎支持使用 CLI 进行本地临时文件摄取和流式源(例如 Kafka 源)。Quickwit 可以从一个或多个源将数据插入到索引中。更多详细信息可以在 源配置页面 中找到。
- https://quickwit.io/docs/reference/cli#tool-local-ingest
- https://quickwit.io/docs/configuration/source-config
Checkpoint(检查点)
Quickwit 通过检查点实现了恰好一次(exactly-once)处理。对于每个源,“源检查点”记录了目标文件或流中已处理的文档位置。检查点存储在元存储中,并且每次发布新分片时都会原子性地更新。当出现索引错误时,索引过程会从最后一个成功发布的检查点后立即恢复。内部地,源检查点表示为一个对象映射,该映射从绝对路径或分区 ID 到偏移量或序列号。
Querying(查询)
Quickwit 提供了两个带有全文搜索查询的端点,这些查询由 query 参数标识:
- 一个搜索端点返回 JSON
- https://quickwit.io/docs/reference/rest-api
- 一个搜索流端点返回请求的 字段值 的流
- https://quickwit.io/docs/reference/rest-api
搜索器接收到的搜索查询将按照以下步骤使用 Map-Reduce 方法执行:
- 搜索器根据请求的时间戳区间(参见时间分片)和标签(参见标签剪枝)来确定相关的分片。
- https://quickwit.io/docs/overview/concepts/querying#time-sharding
- https://quickwit.io/docs/overview/concepts/querying#tag-pruning
- 它使用 rendez-vous 哈希 在集群中的其他可用搜索器之间分发分片工作负载,以优化缓存和负载。
- https://en.wikipedia.org/wiki/Rendezvous_hashing
- 最后,它等待所有结果,合并它们,并将结果返回给客户端。
搜索流查询遵循与搜索查询相同的执行路径,除了最后一步:而不是等待每个搜索器的结果,搜索器一旦开始从某个搜索器接收结果就立即流式传输这些结果。
Time sharding(时间分片)
对于具有时间成分的数据集,Quickwit 将数据分片为具有时间戳感知的分片。借助此功能,Quickwit 能够在查询处理阶段之前过滤掉大部分分片,从而大幅减少处理查询所需的数据量。
以下查询参数可用于对您的查询应用时间戳剪枝:
startTimestamp: 限制搜索范围为具有timestamp >= start_timestamp的文档endTimestamp: 限制搜索范围为具有timestamp < end_timestamp的文档
Tag pruning(标签剪枝)
Quickwit 还提供了在第二个维度上进行剪枝的功能,这个维度被称为 tags。通过 将字段设置为带标签,Quickwit 将在索引时生成分片元数据,以便在查询时过滤出匹配请求标签的分片。请注意,这种元数据仅在字段基数小于 1,000 时生成。
* https://quickwit.io/docs/configuration/index-config
标签剪枝在多租户数据集中特别有用。
Partitioning(分区)
Quickwit 可以根据分区键将文档路由到不同的分片中。
此功能尤其适用于不同标签的文档混合在同一来源(通常是 Kafka 主题)的情况。
在这种情况下,仅仅将字段标记为标签对搜索没有积极影响,因为所有产生的分片几乎都包含所有标签。
partition_key 属性(在文档映射中定义)允许您配置 Quickwit 用来将文档路由到隔离分片的逻辑。
Quickwit 在合并过程中也会强制执行这种隔离。从某种意义上说,此功能类似于分片。
分区和标签经常用于:
- 在多租户应用程序中分离
tenants - 在观察日志情况下分离
team或application
生成大量分片可能会给 indexer 带来巨大压力。因此,
文档映射中的另一个参数 max_num_partitions 作为安全阀。如果分区数量接近超过 max_num_partitions,则创建一个额外的分区,
并将所有额外分区组合到这个特殊分区中。
如果您期望有 20 个分区,我们强烈建议您不要将 max_num_partitions 设置为 20,而是使用一个较大的值(例如 200)。
Quickwit 应该能够平稳地处理这么多分区的数量,并且可以避免由于少数错误的文档而导致属于不同分区的文档被组合在一起。
分区键 DSL
Quickwit 允许您使用简单的 DSL 配置文档的路由方式。以下是一些示例表达式及其结果的简短描述:
tenant_id: 每个tenant_id创建一个分区tenant_id,app_id: 每个tenant_id和app_id的唯一组合创建一个分区tenant_id,hash_mod(app_id, 8): 对于每个租户,最多创建 8 个分区,每个分区包含一些应用程序的相关数据hash_mod((tenant_id,app_id), 50): 总共创建 50 个分区,其中包含一些租户和应用程序的组合。
分区键 DSL 由以下语法生成:
RoutingExpr := RoutingSubExpr [ , RoutingExpr ]
RougingSubExpr := Identifier [ \( Arguments \) ]
Identifier := FieldChar [ Identifier ]
FieldChar := { a..z | A..Z | 0..9 | _ }
Arguments := Argument [ , Arguments ]
Argument := { \( RoutingExpr \) | RoutingSubExpr | DirectValue }
# We may want other DirectValue in the future
DirectValue := Number
Number := { 0..9 } [ Number ]
目前支持的函数包括:
hash_mod(RoutingExpr, Number): 对RoutingExpr进行哈希运算,并将结果除以Number,只保留余数。
当使用 hash_mod 与键元组(如 hash_mod((tenant_id,app_id), 50))时,请注意这可能会将文档路由到一起,从而使标签效果降低。
例如,如果 tenant_1,app_1 和 tenant_2,app_2 都被发送到第 1 个分区,而 tenant_1,app_2 被发送到第 2 个分区,则对 tenant_1,app_2 的查询
仍然会在第 1 个分区中搜索,因为它会被标记为 tenant_1,tenant_2,app_1 和 app_2。因此,您应该更倾向于使用像
hash_mod(tenant_id, 10),hash_mod(app_id, 5) 这样的分区键,这样会生成同样数量的分片,但具有更好的标签。
搜索流查询限制
搜索流查询可能占用大量的 RAM。Quickwit 默认将每个分片的并发搜索流数量限制为 100。您可以通过设置搜索器配置文件中名为 max_num_concurrent_split_streams 的属性值来调整此限制。
Caching(缓存)
Quickwit 在许多地方使用缓存以实现高性能的查询引擎。
- Hotcache 缓存:一种静态缓存,用于存储关于分片文件内部表示的信息。它有助于加快打开分片文件的速度。其大小可通过
split_footer_cache_capacity配置参数定义。 - 快速字段缓存:快速字段通常被用户频繁访问,尤其是在流请求中。它们被缓存在 RAM 中,其大小可以通过
fast_field_cache_capacity配置值限制。 - 部分请求缓存:在某些情况下,例如使用仪表板时,可能会发出非常相似的请求,只有时间戳边界发生变化。可以缓存一些部分结果以使这些请求更快并减少向存储发出的请求。它们被缓存在 RAM 中,其大小可以通过
partial_request_cache_capacity配置值限制。
Scoring(排序)
Quickwit 支持按 BM25 分数对文档进行排序。为了按分数查询,必须为字段启用 fieldnorms。默认情况下,BM25 排序处于禁用状态以提高查询延迟,但可以通过在查询中将 sort_by 选项设置为 _score 来启用。
- https://quickwit.io/docs/configuration/index-config#text-type
Deletes(删除)
Quickwit 通过 delete API 支持删除操作。需要注意的是,此功能主要用于遵守 GDPR(通用数据保护条例),并且应谨慎使用,因为删除操作成本较高:通常建议每小时或每天执行几次查询即可。
- https://quickwit.io/docs/reference/rest-api#delete-api
Delete tasks(删除任务)
针对特定索引的删除任务将在删除任务创建之前创建的所有分片上执行。如果删除查询匹配多个分片中的文档,这可能是一个持续很长时间的任务,可能需要几个小时。
为了跟踪执行进度,每个删除任务都会分配一个唯一的递增标识符,称为“操作戳记”或 opstamp。所有现有分片都将接受删除操作,并且在成功后,每个分片的元数据将更新为相应的操作戳记。
在删除任务创建之后创建的所有分片将具有大于或等于删除任务 opstamp 的 opstamp(如果有其他删除任务同时创建,则更大)。
Quickwit 对给定分片批量执行删除操作:例如,如果某个分片的删除 opstamp = n,而最新创建的删除任务的 opstamp = n + 10,那么将在该分片上一次性执行十个(10)删除查询。
Delete API
删除任务通过 Delete REST API 创建。
- https://quickwit.io/docs/reference/rest-api#delete-api
Pitfalls(常见问题)
Immature splits(不成熟的分片)
删除操作仅应用于“成熟的”分片,即不再进行合并的分片。分片是否成熟取决于 合并策略。可以定义 maturation_period,在此期间之后分片将变为成熟。因此,在 t0 时刻创建的删除请求将首先应用于成熟的分片,并且在最坏的情况下,将等待至 t0 + maturation_period 时刻,让不成熟的分片变得成熟。
- https://quickwit.io/docs/configuration/index-config#merge-policies
Monitoring and dev XP(监控和开发体验)
目前无法监控删除操作。已有一个 issue 开启以改善开发体验,欢迎添加您的评论并关注其进展。
- https://github.com/quickwit-oss/quickwit/issues/2494