目录
- 概
- 符号说明
- 所有参数的 Hessian 矩阵
- Block-wise Hessian
- 代码
Zhang Y., Chen C., Ding T., Li Z., Sun R. and Luo Z. Why transformers need adam: a hessian perspective. arXiv preprint, 2024.
概
本文从 Hessian 矩阵的角度回答为什么 Adam 相较于其它方法, 比如 SGD 在 transformer 的训练上格外有效.
符号说明
- 假设一个网络分为 \(L\) 个 block, 每个 block 有可学习的参数 \(w \in \mathbb{R}^{d_l}\);
- \(\mathcal{L}\), 损失函数, \(w = [w_1, w_2 ,\ldots, w_L]\) 记为所有的参数;
- \(\nabla^2 \mathcal{L} (w_l) \in \mathbb{R}^{d_l \times d_l}\), 第 \(l\) 个 block 的参数的所对应的 Hessian 矩阵
所有参数的 Hessian 矩阵
- 作者考虑 ResNet18, VGG16 在 ImageNet 上的实验, 以及 GPT2 在 OpenWebText 上的实验, ViT-base 在 ImageNet 上的hi眼, BERT 在 Cornell Movie-Dialogs Corpus 上的实验, GPT2-nano 在 English corpus 上的实验.
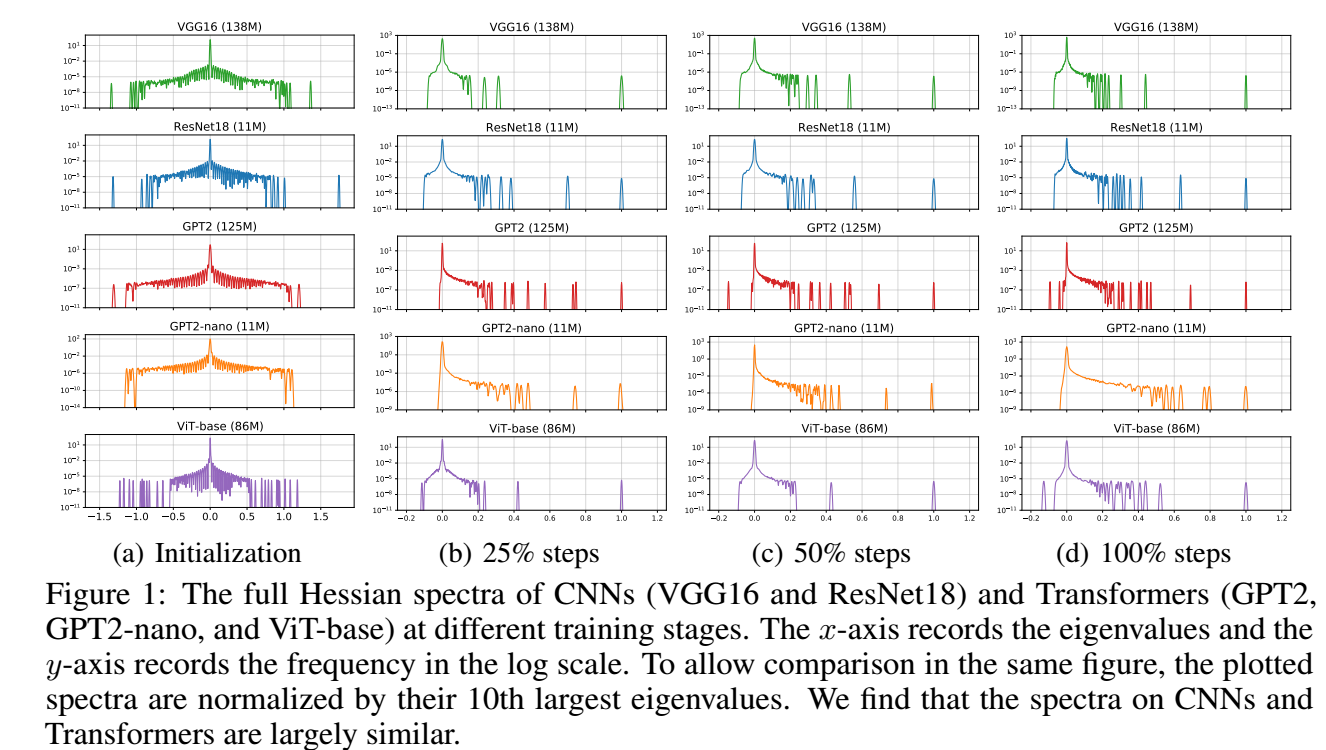
- 首先我们观察一下所有参数的 Hessian 上的差距, 从上图 (Adam, SGD 表现差不多, 所以作者只放了一个), 可以发现, 其实不同的模型, 即使一个是 CNN 另一个是 Transformer, 他们训练的时候的参数的 Hessian 矩阵的整体的谱是相差不大的. 所以我们没法直接从这个指标上回答为什么 Adam 会比 SGD 好一点.
Block-wise Hessian
- 接着, 我们检查每一个 block, 这里的 block 可以简单理解为 PyTorch 自带的分割, 比如 MLP, Query/Key/Value projection, embedding layer 等.
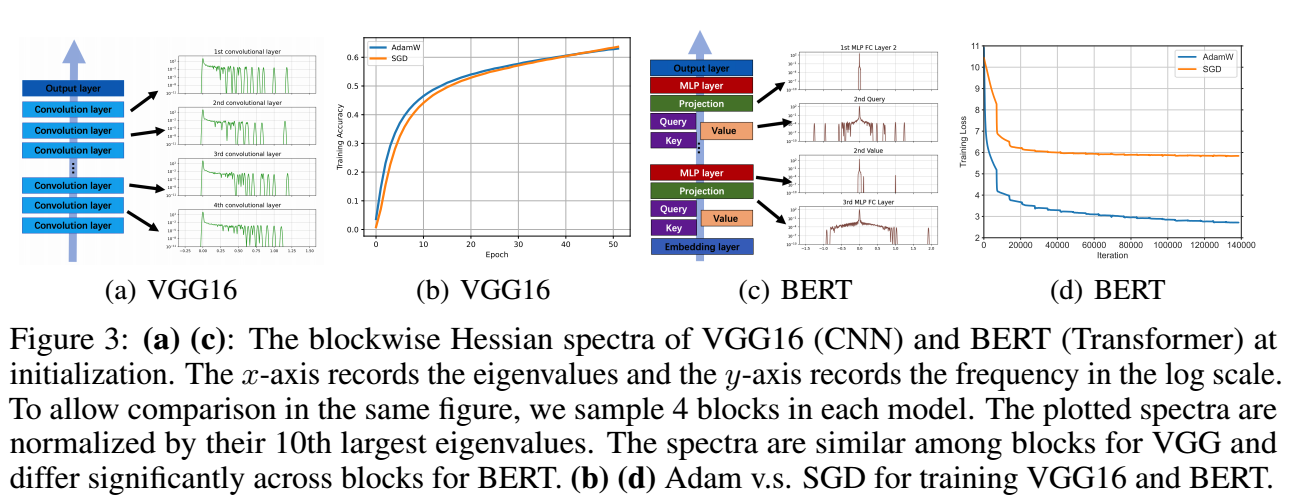
- 可以很明显地发现, Transformer 的不同 block 的谱 (分布) 相差是很大的, 而 CNN 的则很一致.
-
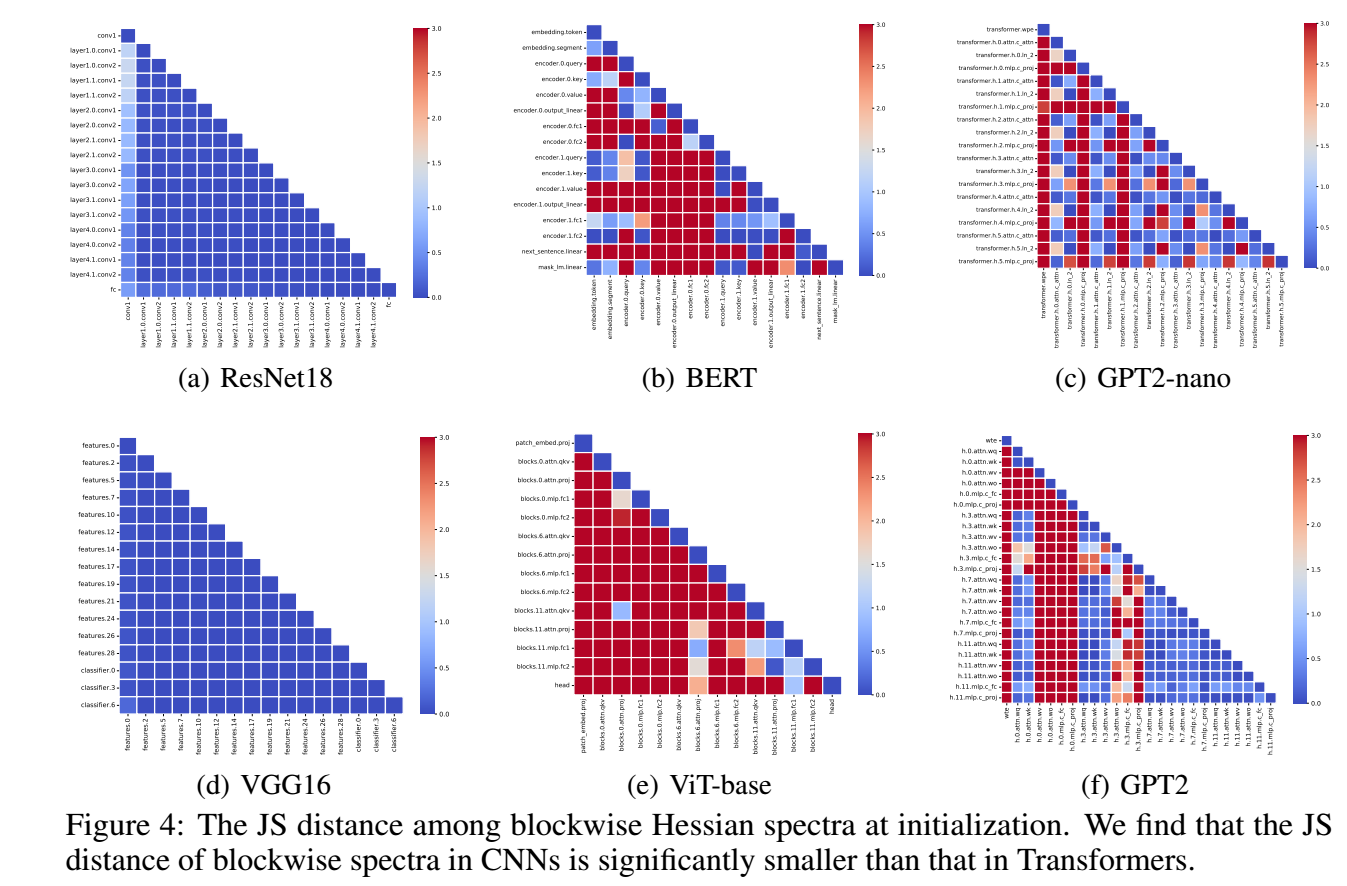
进一步, 我们可以计算不同模型的不同 block 的 hessian 的谱间的 Jensen-Shannon 距离, 可以发现, CNN 的模型一致地低, 而 Transformer 模型不同 block 间差异很大.
-
我们可以这么认为, 因为 transformer 不同 block 差异很大, 所以很难通过设定一个学习率去统一, 所以需要 Adam 这种每个位置单独设定学习的优化器.
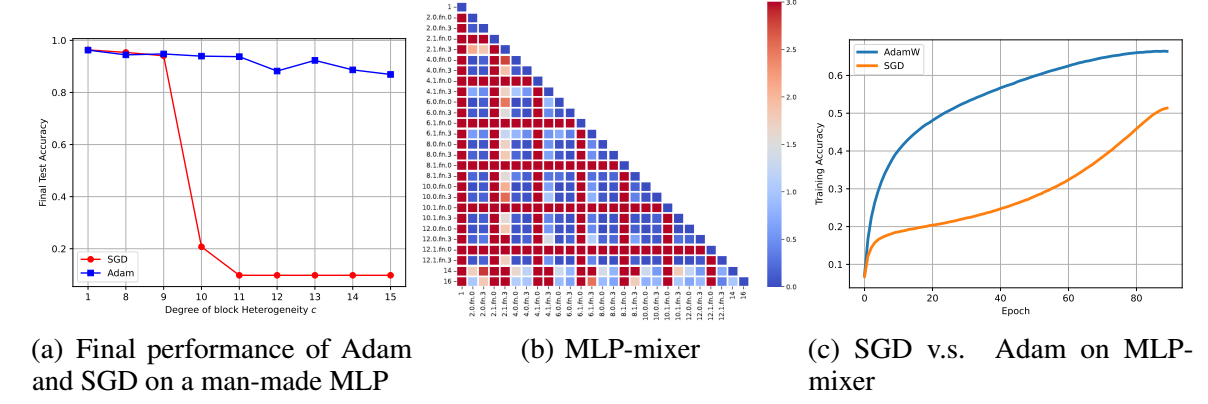
- 作者认为, 这主要和 Transformer 的层次的堆叠不那么具有序列性有关, 一个简单的例子是, MLP-mixer, 它仅由 MLP 组成, 但是运算方式是模仿 Transformer 的, 可以发现, 它的不同 block 间的距离也呈现类似的情况.

-
上表列出了不同 block 的一个平均 JS 距离.
-
作者进一步给出了一个二次方程的优化的例子, 并给予了理论分析, 有兴趣的可以回看原文.
代码
[official]