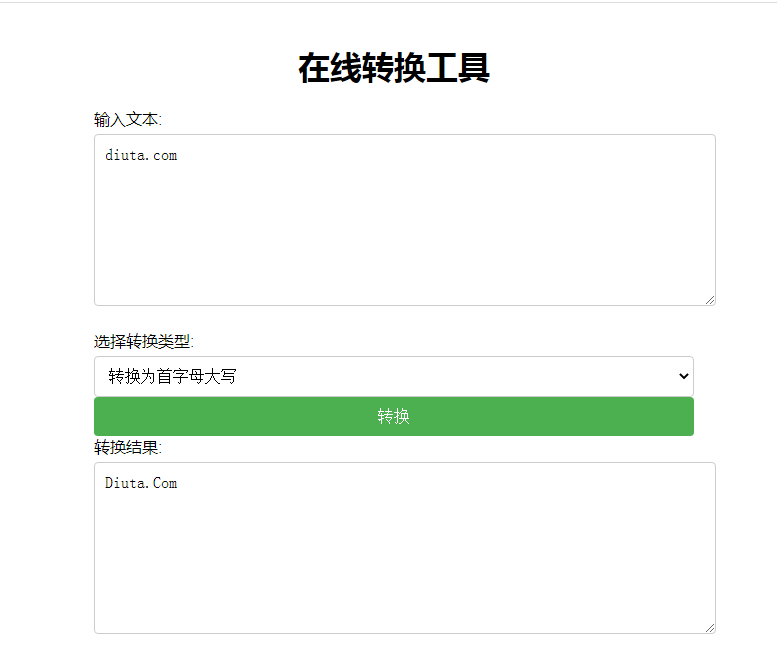
一前言
环境:win10 mysql 5.7.32
记录一些sql中平时容易弄错的或不明白一些知识点
二 正文
1 select语句执行顺序
FROM→WHERE→GROUP BY→HAVING→SELECT→ORDER BY
--一个大概的执行顺序,具体执行顺序根据数据库管理系统S的不同而不同
如下成绩表score


如上,可以看出,avg()函数只统计了0003同学两门得分50的课程,得分80的课程并没有被统计
根据上面的执行顺序,应该是先执行where,即把成绩大于60所在行数据踢出去,再执行的group语句,所以0003同学得分为80的成绩自然未被统计
2 关于分组 group by
2.1 作为select查询结果的列名对应的限制
如果查询语句使用了group by,那么和group by所对应的select 后面的列只能属于三种情况
即select xxx1,xx2,xxn from table group by c1
xxx1,xxx2,xxn只能是结果为单一值的下面4种情况
- 常数
- 聚合函数:如sum() count(*) max()
- 与 紧跟在 group by后指定的列一致
- 虽然与group by后指定的不一致,但group by后 结果为单一值得列(好像只有在mysql才行)
如下,有成绩表score2

现在要查出每个subject成绩排前三的数据
尝试写出下列部分语句时却报错

事后细察,原因就出在select后面的 a.name, , a.score,因为以subject分组时,同一个组内,有多个name的值,系统不知道要显示哪一个。 有group by, 对应select查询结果只能是单一值
改成下面这样就不报错
2.2 group by中的列名不能用别名
如 select xx2 as c2 from table group by c2
这样写是错误的,因为执行顺序的原因,会先执行group by,就导致系统不知道c2是个什么东西
2.3 count(分组字段)是可以的
select count(性别) from table group by 性别
如上,之前,因为同一组性别的值都是相同的,就一直隐隐感觉分组字段放在聚合函数会有问题。
其实是对count()函数的作用没理解清楚,count()和值基本无关,count()值会统计字段列的行数。
此时count(性别)和count(*)就是等价的
3 count(1),count(*), count(字段xxx)
count()是用来统计行数的
简单点,可以把count(1)与count(*)看成等价的,针对所有列计算其行数,不会忽略任何行
count(字段xxx),针对该字段所在列计算其行数,如果该列在某行的值为null,则会忽略,而count(*)与count(1)不会忽略null



4 where中不能使用聚合函数
比如 现有一张班级学生成绩表。 要查询成绩小于班级平均成绩的同学信息
selext xxxx from table where 成绩<avg(平均成绩)
#上面这样下意识觉得没有啥问题,但却不符合where的使用规则# 采用子查询的方式来得到where后需要统计函数计算的字段
select xxx from tablewhere 成绩<(select avg(平均成绩) from table)
5 distinct的作用范围
select ditinct xx1
select sum(distinct xx)
如上,distinct放在一个单独的字段前面或聚合函数里面,都是只对该字段起作用,只会在该字段所在列的结果行上删除重复的行(null值也被视为一类数据)
distinct也可以放在多个字段的最前面,会将多个字段的值进行组合,如果组合值有重复则会被删掉
select distinct xx1, xx2 from table
#此时distinct不是对xx1起作用,而是对xx1 xx2的组合起作用另外要注意distinct的位置,除非放在聚合函数的括号里面,否则distinct只能放在第一个列名字段之前

![[JLOI2015] 骗我呢——一类经典反射容斥](https://s1.ax1x.com/2018/10/18/iwUt1O.png)