MYSQL索引
前言
Mysql 作为互联网中非常热门的数据库,其底层的存储引擎和数据检索引擎的设计非常重要,尤其是 Mysql 数据的存储形式以及索引的设计,决定了 Mysql 整体的数据检索性能。
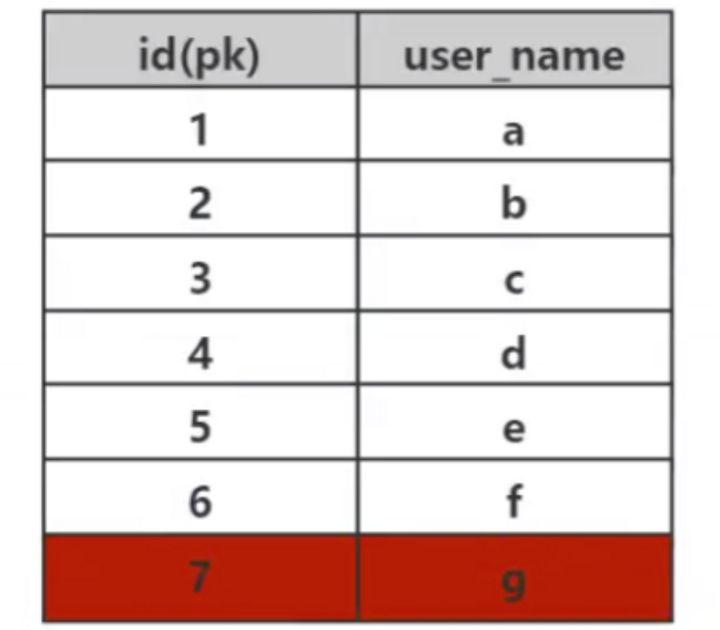
我们知道,索引的作用是做数据的快速检索,而快速检索的实现的本质是数据结构。通过不同数据结构的选择,实现各种数据快速检索。在数据库中,高效的查找算法是非常重要的,因为数据库中存储了大量数据,一个高效的索引能节省巨大的时间。比如下面这个数据表,如果 Mysql 没有实现索引算法,那么查找 id=7 这个数据,那么只能采取暴力顺序遍历查找,找到 id=7 这个数据需要比较 7 次,如果这个表存储的是 1000W 个数据,查找 id=1000W 这个数据那就要比较 1000W 次,这种速度是不能接受的。
MYSQL索引底层数据结构选型
1.哈希表
哈希表是做数据快速检索的有效利器。
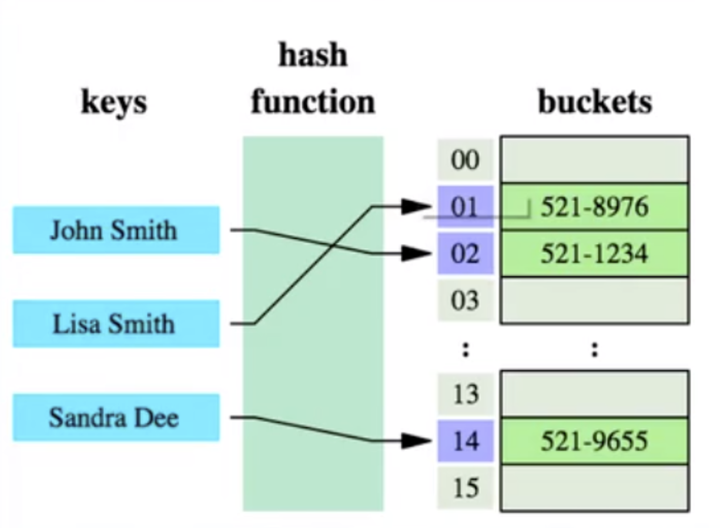
哈希算法:也叫散列算法,就是把任意值(key)通过哈希函数变换为固定长度的key地址,通过这个地址进行具体数据的数据结构。
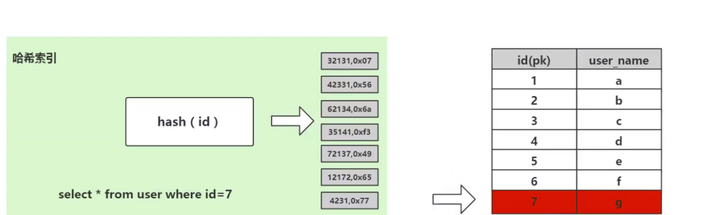
考虑这个数据库表 user,表中一共有 7 个数据,我们需要检索 id=7 的数据,SQL 语法是:
select * from user where id= 7;
哈希算法首先计算存储id=7的数据的物理地址 addr=hash(7)=4231,而4231映射的物理地址是077,077就是id=7存储的额数据的物理地址,通过该独立的地址就可以找到对应的user_name=’g‘这个数据。这就是哈希算法快速检索数据的计算过程。
但是哈希算法有个数据碰撞的问题,也就是哈希函数可能对不同的key会计算出同一个结果,比如hash(7)可能和hash(199)的哈希结果相同,也就是不同的key映射到同一个结果了,这就是碰撞问题。解决碰撞问题的一个常见处理方法就是链地址法,即用连表把碰撞数据连接起来。计算哈希值后,还需要检查该哈希值是否存在碰撞数据链表,有则一致遍历到链表尾,直到找到真正的key对应的数据为止。
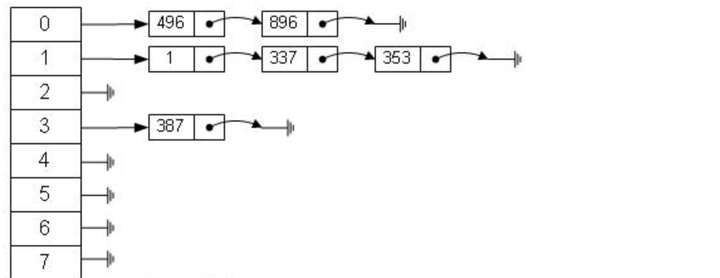
从算法时间复杂度分析来看,哈希算法时间复杂度为 O(1),检索速度非常快。比如查找 id=7 的数据,哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?
因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
select * from user where id>3;
针对以上这个语句,我们希望找出id>3的数据,这是典型的范围查找。如果使用哈希算实现的索引
,实现范围查找只能一次性把所有数据找出来加载到内存,然后再在内存内筛选目标范围内的数据。但是这种方法太笨重,效率很低。
所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效率范围查找,因此哈希索引不适合做MYSQL底层的数据结构。
2.二叉查找树(BST)
二叉查找树是一种支持数据快速查找的数据结构,如图:
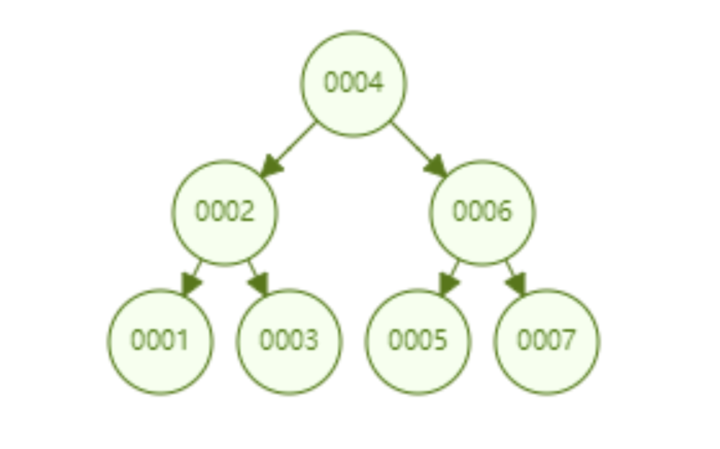
二叉查找树的时间复杂度是O(lgn),比如针对上面这个二叉树结构,我们需要计算比较3次就可以检索到id=7的数据,相对于直接遍历查询节省了一半时间,从检索的效率上能做到快速检索。同时,二叉树结构可以解决哈希算法不能实现 的范围查找,二叉树的叶子节点都是按序排列的,从左到右依次升序排列,如果我们需要id>5的数据,只需要找到节点为6的节点及其右子树就可以了,范围查找也较容易实现。
但是普通的二叉树有个致命的缺点:在极端的情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂度退化为O(n),检索性能急剧下降。比如以下例子,二叉树已经极度不平衡了,已经退化为链表了,检索性能大大降低。此时查询id=7的次数已经变为7.
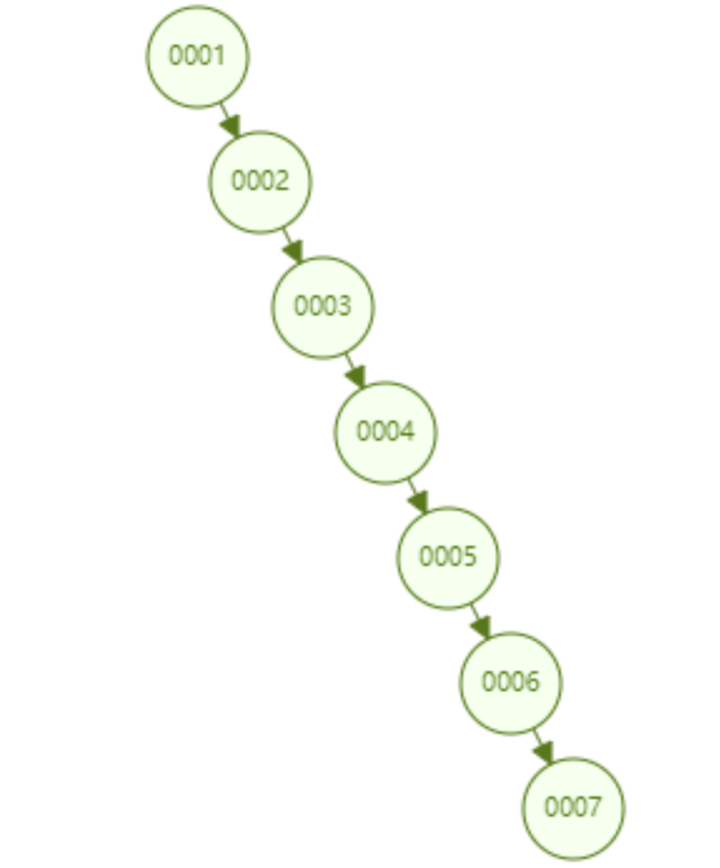
在数据库中,数据的自增是一个常见的形式,比如一个表的主键是id,而主键一般默认都是自增的,如果采取二叉树这种结构作为索引,那么以上的不平衡状态导致的线性查找的问题是必然的。因此,简单的二叉树存在不平衡导致了MYSQL的底层不能使用其作为索引。
3.AVL树和红黑树
红黑树,这是一颗会自动调整树形态的树结构,比如当二叉树处于一个不平衡状态时,红黑树就会自动左旋右旋节点以及节点变色,调整树的形态,使其保持基本的平衡状态(时间复杂度为O(lgn)),也就保证了查找效率不会降低,比如从1到7升序插入数据节点,如果是普通二叉树则会退化为链表,但是红黑树会不断调整树的形态,使其保持平衡状态,如下图所示。
红黑树拥有不错的平均查找效率,也不存在极端的O(n)情况,但是红黑树也存在一些问题。
红黑树顺序插入1~7个节点,查找id= 7时需要计算的节点数为4.
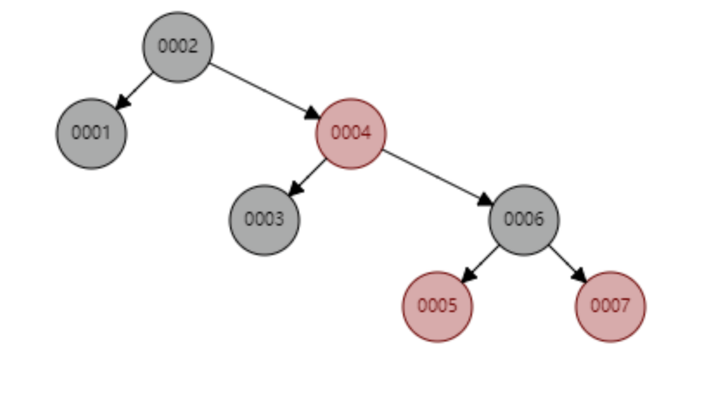
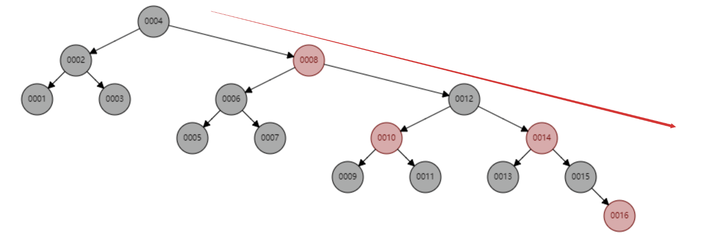
红黑树顺序插入1~16个节点,查找id=16需要比较的节点数为6次,观察以下这个树的形态,当数据按照顺序插入是,一直保持右倾的趋势。从根本上看,红黑树并没有完全解决二叉查找树,虽然右倾趋势远远没有二叉查找树退化为链表的矿长,但是数据库的基本主键自增操作,主键一般都是数百万数千万的,如果红黑树存在这种问题,对于查找性能来说也是巨大的消耗,我们的数据库不可能忍受这种无意义的等待。
AVL树是一个绝对平衡的二叉树,因此它在调整二叉树的形态上消耗的性能更多。
AVL树顺序插入1~7个节点,查找id=7索要比较的节点次数为3.
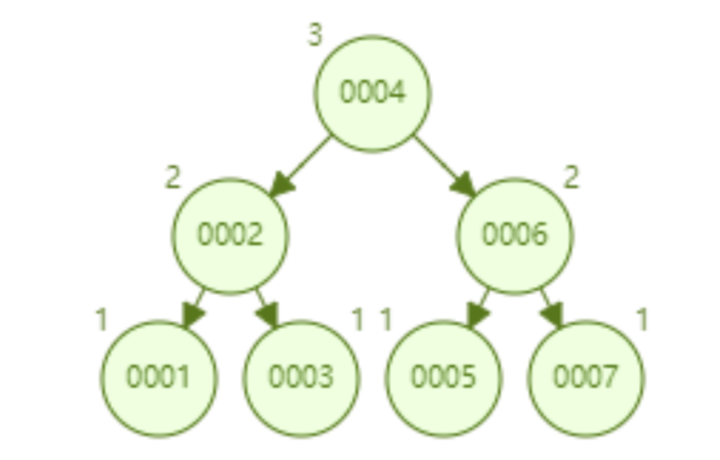
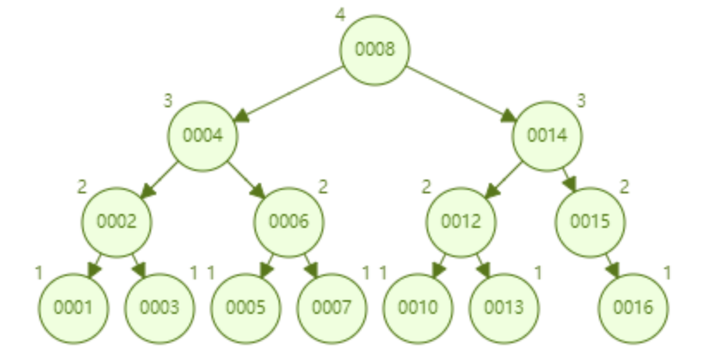
AVL树顺序插入1~16个节点,查找id=16需要比较的次数为4.从查找效率而言,AVL树的查找速度要比红黑树快。从树的形态来看,AVL树不存在右倾问题,也就是说,大量的插入不会导致性能的降低,这从根本上解决了红黑树的问题。
总结一下AVL树的优点:
- 不错的查找性能(O(lgn)),不存在极端的低效查找的情况。
- 可以实现范围查找,数据排序。
看起来AVL树作为数据查找的数据结构很不错,但是AVL树并不适合做MYSQL数据库的索引数据结构,因为考虑以下的问题:
数据库查询数据的瓶颈在于磁盘IO,如果使用的时AVL树,我们每一个树节点只存储了一个数据,我们的一次磁盘IO只能去一个节点上的数据加载到内存,如果查询id=7这个数据,我们就需要IO3次,这是很消耗时间的,所以,设计数据库索引时,首先考虑怎么尽可能减少磁盘IO的次数。
磁盘IO有个特点,就是从磁盘读取1B和1KB的数据所消耗的时间是一致的,所以根据这个思路,我们可以在树的一个节点上尽可能多的存储数据,一次磁盘IO就多加载点数据到内存,这就是B树,B+树的设计原理。
4.B树
B树,每个节点限制最多存储两个key,一个节点如果超过两个key就会自定分裂。比如下面这个存储了7个数据的B树,只需要查询两个节点就可以知道id=7这个数的具体位置,也就是两次磁盘IO就可以查询到指定数据,效率高于AVL树。
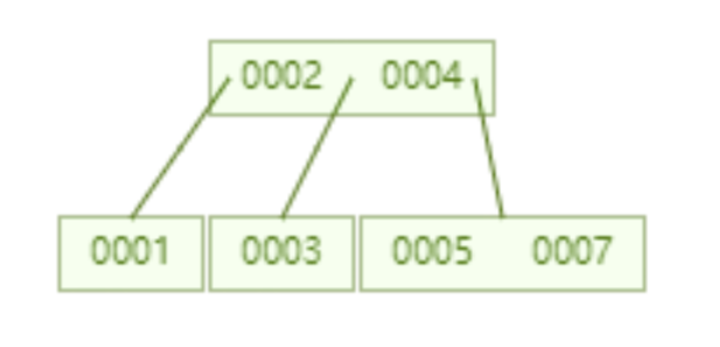
下面是一个存储了 16 个数据的 B 树,同样每个节点最多存储 2 个 key,查询 id=16 这个数据需要查询比较 4 个节点,也就是经过 4 次磁盘 IO。看起来查询性能与 AVL 树一样。
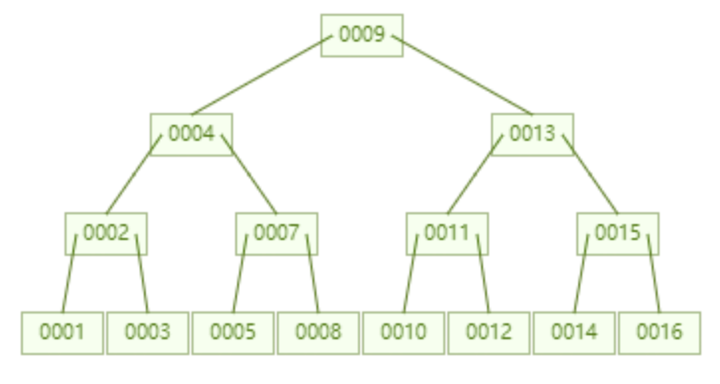
但是考虑到磁盘IO读一个数据和读100个数据所消耗的时间基本一致,那我们优化的思路就可以改为:尽可能多的再一次磁盘IO读取数据到内存中。这个直接反映的树的结构就是,每个节点存储的key可以适当增加。
当我们把单个节点限制的key个数设置为6之后,一个存储了7个数据的B树,查询id=7这个数所需要进行的磁盘IO只需要2次。
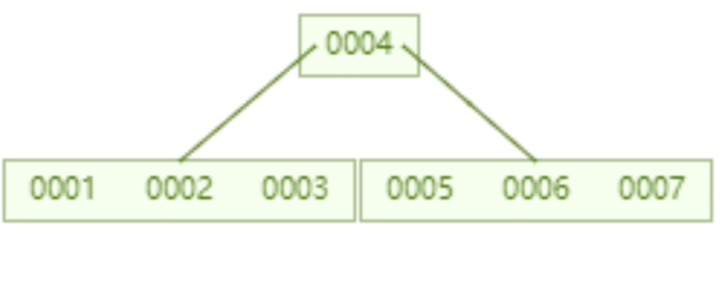
一个存储了16个数据的B树,查询id=7这个数据要进行的磁盘IO次数为2.相比于AVL树,性能提升了1倍。

所以数据库索引数据结构的选型而言,B树是一个很好的选择。
总结B树用作MYSQL数据库索引有以下优点:
- 优秀的检索速度,时间复杂度:B树的查找性能等于O(h*logn),其中h为树高,n为每个节点关键词个数。
- 尽可能减少磁盘IO次数,加快了检索速度。
- 可以支持范围查询。
5.B+树
B+树和B树有什么不同?
第一,B树一个节点里存储的是数据,而B+树存储的是索引(地址),所以B树里一个节点存不了很多个数据,但是B+树一个节点可以存储很多索引,B+树叶节点村所有的数据。
第二,B+树的叶子节点的数据用了一个链表串联起来,便于范围查找。

通过B树和B+树的对比来看,B+树节点存储的是索引,在单个节点存储数据有限的情况下,单节点也可以存储大量索引,使得整个B+树的高度降低,减少了磁盘IO次数。其次,B+树真正存储数据的的地方是其叶子节点,叶子节点用了链表串联起来,这个链表本身就是有序的,在数据范围查找时,效率更高。因此MYSQL的索引用的就是B+树,B+树在查找效率,范围查找中都有着很不错的性能。