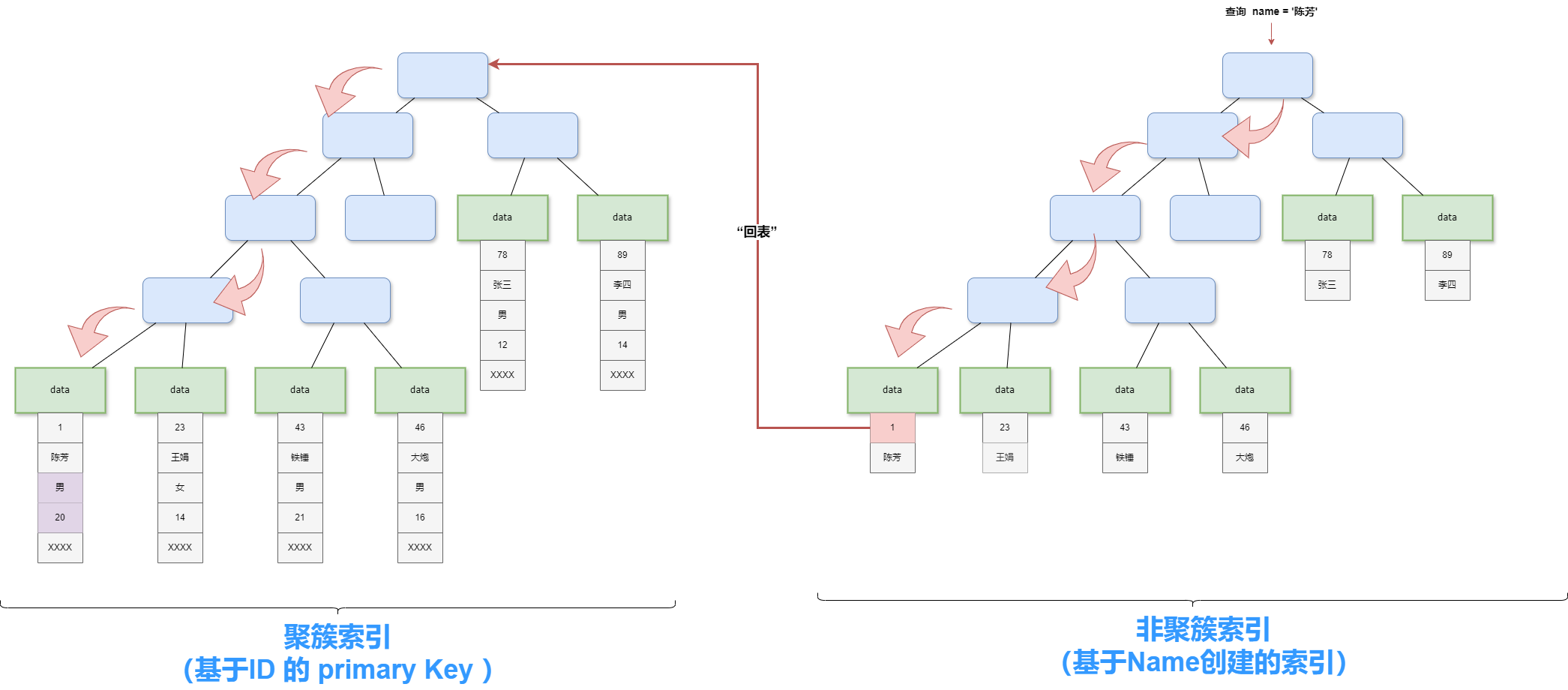
01 研究意义
Occupancy Network算法因为可以更好的克服感知任务中存在的长尾问题,以及更加准确表达物体的几何形状信息,而受到来自工业界和学术界越来越广泛的关注。
Occupancy Network算法本质上是一个3D分割任务,通过将想要感知的3D空间划分成固定大小的体素网格,并让算法去预测每个体素网格被占用的概率以及可能包含的目标类别从而实现对全场景的感知。因其是对空间中的所有体素进行分类,所以对于数据集中未被标注的物体(比如土堆、石块等目标也可以预测为General Objects,从而实现开放集的目标检测,即更好的克服检测中的长尾问题);同时与直接输出一个物体粗糙3D框的算法相比,由于是直接对空间中的每个体素进行预测,所以对于不规则形状的目标,Occupancy Network算法可以给出更加细粒度的形状表示,从而得到每个物体更加丰富的细节结构信息。

02 存在问题
尽管目前Occupancy Network相比于之前的基于BEV的3D感知算法有更好的感知优势,但因其将所要感知的环境空间利用3D体素特征进行中间表示,避免不了的会引入3D卷积等算子进行特征提取,无疑会大大增加模型的运算量和内存开销,从而为模型的上车部署造成不小的困难,严重影响了Occupancy Network算法的落地。
为此针对Occupancy network模型的轻量化是非常有必要的。
03 数据集选择
目前,在3D目标检测中开源的数据集包括kitti,nuscenes,waymo,lyft,scannet,s3dis,sunrgbd,智能驾驶行业内没有统一的评测数据集,根据目前开源的基础数据集包括kitti,nuscenes,waymo其中nuscenes数据集应用较多,目前科研领域内采用CVPR2023占用预测挑战赛的Occ3D-nuScenes数据集的论文屡见不鲜。
04 主干网络部分
4.1 选择更合适的主干网络
目标检测任务中常见的主干网络包括:Resnet,Swin-transformer,ViT,Efficientnet,Vovnet,ShuffleNet,MobileNet,GhostNet,其中Resnet,Swin-transformer,Vovnet较为常见,Resnet-101,Resnet-50网络更是大多数模型的主干网络。
ResNet(Residual Network)是由微软亚洲研究院的Kaiming He等人提出的,它在2015年的ILSVRC比赛中斩获了冠军,成为了经典的深度学习骨干网络之一。下面我们将对ResNet进行详细介绍。
EfficientNet是由谷歌研究团队提出的一种基于复合缩放的神经网络架构,其主要特点是在不增加计算复杂度的情况下提升模型性能。EfficientNet使用了一种称为复合缩放(Compound Scaling)的方法,同时调整网络的深度、宽度和分辨率,从而在不增加计算成本的情况下提高了模型的效果。
虽然传统ResNet在一定程度上改善了传统深层网络的训练困难问题,但相比EfficientNet,ResNet仍然存在参数量大、计算量大的问题,使得在移动设备等资源受限的环境下应用时性能不尽如人意。实际应用中,不同的骨干网络具有各自的优势和局限性。EfficientNet在目标检测任务中表现出色,尤其适合资源受限的场景;而ResNet虽然在一些任务上表现较好,但对于目标检测任务来说可能存在训练速度较慢的问题。


4.2 FlashOcc主干网络
在FlashOcc中主干网络对输入的环视图像进行多尺度的特征提取,2D主干网络采用的是ResNet-50。
需要注意的是,由于当前的config配置是将时序上连续的三帧环视图像一起输入到网络模型当中,所以模型对于不同帧的处理方式是不同的。
如果当前时刻标记为t,那么对于t-2时刻的环视图像,2D主干网络只会输出降采样四倍的特征图用于后续进行双目立体的深度估计,代码中定义降采样4倍的特征为Stereo Feature。
但是对于t和t-1时刻,2D主干网络在输出降采样4倍Stereo Feature的同时,还会输出降采样16倍和32倍的特征图,用于后续完成多尺度特征的信息融合。
05 前后向投影模式
该模式由FB-Occ提出,在精度预测和推理速度上在当时都是领先的存在,该模式包含两部分:前向投影和后向投影模式。
5.1 前向投影
使用前向投影来生成3D体素表示
将 3D 体素表⽰压缩为扁平化的BEV特征图 3)最后将 3D 体素表⽰和优化的 BEV 表⽰的融合特征输⼊到后续任务头中
前向投影总结:相对原来的LSS是投影到BEV空间中,这里是投影到3D体素空间中

5.2 后向投影
3D体素表示压缩为BEV表示,从⽽结合更强的语义
利⽤了投影阶段的深度分布,能够更精确地建模投影关系
后向投影总结:灵感来源于BEVFormer
与使⽤随机初始化参数作为 BEV 查询的 BEVFormer 不同
在推理阶段使用了深度分布,从而保证了更加精确的

最后获得3D体素表示和优化后的BEV表示后, 通过扩展BEV特征的过程将他们组合起来, 从而产生最终的3D体素。
06 BEV特征解码
在三维空间中对提升的体素特征进行直接解码相比,由于维度的减少,二维BEV解码器会比三维解码器速度更快。将三维体素特征的z dim与其嵌入通道结合即,得到2D BEV特征B‘∈R(C2×Z2)×H2×W2如下图所示:

然后用2D FCN将B‘解码为BEV特征B∈RC3×H2×W2,如图下所示。

这在很大程度上降低了计算的复杂度。具体可以减少Sj的计算量:

07 测评指标
7.1 BEV分割指标
对于传统OGM中的二进制分割(将网格划分为占用和空闲),大多数以前的工作使用精度作为简单的度量。对于语义分割,主要度量是每个类的IoU和所有类的mIoU。

7.2 BEV预测指标
MotionNet通过将每个网格单元与BEV地图中的位移向量相关联来编码运动信息,并通过将非空网格单元分类为三个速度范围来提出运动预测的度量:静态、慢速(≤5m/s)和快速(>5m/s)。在每个速度范围内,已利用预测位移和真实位移之间的平均和中值L2距离。
7.3 3D占用率预测指标
语义场景补全的主要度量是所有语义类的mIoU,在场景补全时使用IoU、Precision和Recall来评估几何重建质量。3D占用预测挑战测量F得分作为完整性Pc的调和平均值,精度Pa,F得分计算如下:

08 轻量化典型模型案例:FlashOcc
8.1 基本思想
Flash-Occ算法(算法流程图如下)抛弃了长耗时、难部署的3D卷积模块,继续使用2D卷积模块来完成特征的提取任务。同时,为了减少模型的计算量,Flash-Occ不再使用Voxel体素特征,而是继续使用BEV特征来建模需要感知的3D空间。但为了完成Occupancy Network在3D空间的预测,Flash-Occ算法设计了一个通道-高度转换模块实现将BEV空间的输出结果提升到3D体素空间,完成最终的结果预测。

8.2 网络结构
整体来看,Flash-Occ的网络结构包括2D主干网络、Neck网络、深度估计模块、视角转换模块、2D BEV Encoder、Occupancy Head模块、通道高度转换模块、训练过程的Loss计算等部分组成。整体框架如下图所示。

通道高度转换模块也是本文所提出的核心插件。原理十分简单,即Occupancy Head的预测头将语义特征和高度联合在一起进行预测,最后通过Tensor的view操作实现2D特征转换为3D的体素预测结果
#我们将2D BEV Encoder模块的输出到如下2D卷积层
occ_pred = self.final_conv(img_feats).permute(0, 3, 2, 1)
#联合语义特征和高度联合在一起进行预测
#输出结果格式:Tensor([bs, H, W, height×num_classes ])
occ_pred = self.predicter(occ_pred) #通道高度转换模块
occ_pred = occ_pred.view(bs, Dx, Dy, Dz, num_classes)
# 其中
# Dx = BEV空间的大小;
# Dy = BEV空间的大小;
# Dz = 体素高度;
# num_classes = 类别数目
8.3 效果
Occ3D-nuScenes数据集上的可视化效果如下:

FlashOcc在Occ3D-nuScenes数据集上的SSC miou评估精度如下:


上表表示Occ3D-nuScenes 估值数据集上的 3D 占用预测性能。符号 ∗ 表示模型是从预训练的 FCOS3D 主干初始化的。“Cons. Veh”代表工程车辆,“Dri.Sur“是可驱动表面的缩写。“火车。Dur.“ 是训练持续时间的缩写。“Mem.”表示推理过程中的内存消耗。• 表示主干由 nuScense 分割预训练。每秒帧数 (FPS) 指标使用 RTX3090 进行评估,采用 FP16 精度的 TensorRT 基准测试。“FO”是代表 FlashOcc 的首字母缩写词,“FO()”代表以“”命名的相应模型的插件替换。†表示在训练期间使用相机面罩报告性能。符号 ⋄ 表示使用类平衡权重进行占用分类损失
下图和表展示了该方法的推理时间与显内占用上


GitHub 代码:https://github.com/Yzichen/FlashOCC
论文地址:https://arxiv.org/abs/2311.12058