论文链接:https://arxiv.org/pdf/2408.15777
复旦大学,王龑博士后领衔,发布《静态与动态情感的面部表情识别》(A Survey on Facial Expression Recognition of Static and Dynamic Emotions)综述,对基于图像的静态面部表情识别(SFER)和基于视频的动态面部表情识别(DFER)方法进行了全面综述,从模型导向的发展到挑战聚焦的分类进行了系统分析。
论文首先对近期的综述进行批判性比较,介绍了常用的数据集和评估标准,并深入探讨了FER的工作流程,以建立坚实的研究基础。接着,系统性地回顾了应对SFER的八大主要挑战(如表情干扰、不确定性、复合情绪和跨域不一致性)以及应对DFER的七大主要挑战(如关键帧采样、表情强度变化和跨模态对齐)的代表性方法。此外,分析了近期的进展、基准表现、主要应用及伦理考量。最后,提出了五个有前景的未来研究方向和发展趋势,以指导后续研究。本论文的项目页面可访问:https://github.com/wangyanckxx/SurveyFER。
研究背景
情感计算在关键国家领域具有深远的影响和重要性。英国创新署(Innovate UK)将“人工智能(AI)情感和表情识别”列为2024年对英国经济和社会产生深刻影响的50项新兴技术之首。中国科学技术协会也隆重发布了2024年的重大科学问题,其中,具有情感和情感智能的数字人和机器人研究被选为十大前沿科学问题之一。显然,AI情感和表情识别技术的发展已成为通用人工智能、数字计算和多学科研究的必然要求。
面部表情是人类情感表达的主要和直接手段,在人际互动中频繁使用,且具有极其重要的意义。面部表情通过非语言的方式传达比声音、手势和身体姿势更丰富的情感信息。面部情感的概念最早由达尔文在其著作《人类与动物的表情》中提出,表情被认为是天生的,是动物和人类在进化和生存过程中适应性动作的遗留物。Ekman和Friesen提出了六种基本情感:快乐、愤怒、悲伤、惊讶、恐惧和厌恶,并发现了特定面部肌肉模式与情感类型之间的普遍关联,这在跨文化中是一致的。
近年来,随着AI技术的进步,面部情感识别(FER)方法迅速发展,并在心理研究、医学诊断和智能人机交互等领域广泛应用。FER旨在通过分析面部表情来识别个体的情感状态。根据用于捕捉表情的数据类型,FER可以分为基于图像的静态FER(SFER)和基于视频的动态FER(DFER)。SFER主要解决姿态遮挡、跨域不一致性、标签不确定性、数据量不足和跨模态等挑战。研究人员还通过各种数据增强技术和正则化方法来缓解数据量不足和标签不确定性的问题。此外,通过跨模态信息融合,提高了表情识别的鲁棒性和准确性。
SFER关注瞬时表情,而DFER则关注面部表情的时间变化,以准确描述和理解情感转变的全过程。处理视频序列中的表情识别,DFER面临关键帧提取、时空特征提取、表情强度变化和跨模态融合的主要挑战。为捕捉动态表情信息,DFER模型不仅关注单帧中的静态特征,还结合了连续帧之间的时间关系。
面部表情研究分类
本文系统总结了面部表情识别(FER)研究的现状,并通过层次化分类体系,将现有的FER研究按输入类型(基于图像的SFER和基于视频的DFER)、任务挑战和网络结构进行组织,如图1所示。对于SFER,我们识别了八个关键挑战,如干扰、不确定性、复合标签、跨域适应性和跨模态问题,并总结了现有方法中常用的应对这些挑战的模型结构。对于DFER,我们还结合了七个额外的考虑因素,如关键帧提取、表情强度变化、静态与动态一致性、半监督学习和跨域对齐,并总结了当前方法的解决方案。
我们进一步分析并讨论了典型方法在基准数据集上的最新进展。此外,我们还在GitHub仓库中总结了基准数据集、评估指标、文献、代码、工作流程和相关讨论。为了构建这一分类体系,我们广泛回顾了2016年至2024年间的大量研究论文。图2展示了2016年至2024年间与基于图像的SFER和基于视频的DFER相关的出版物和引用趋势。从2019年开始,出版物和引用量显著增加,并持续增长到2023年,并预计在2024年继续上升。这反映了对SFER和DFER领域的兴趣和进展的日益增长。
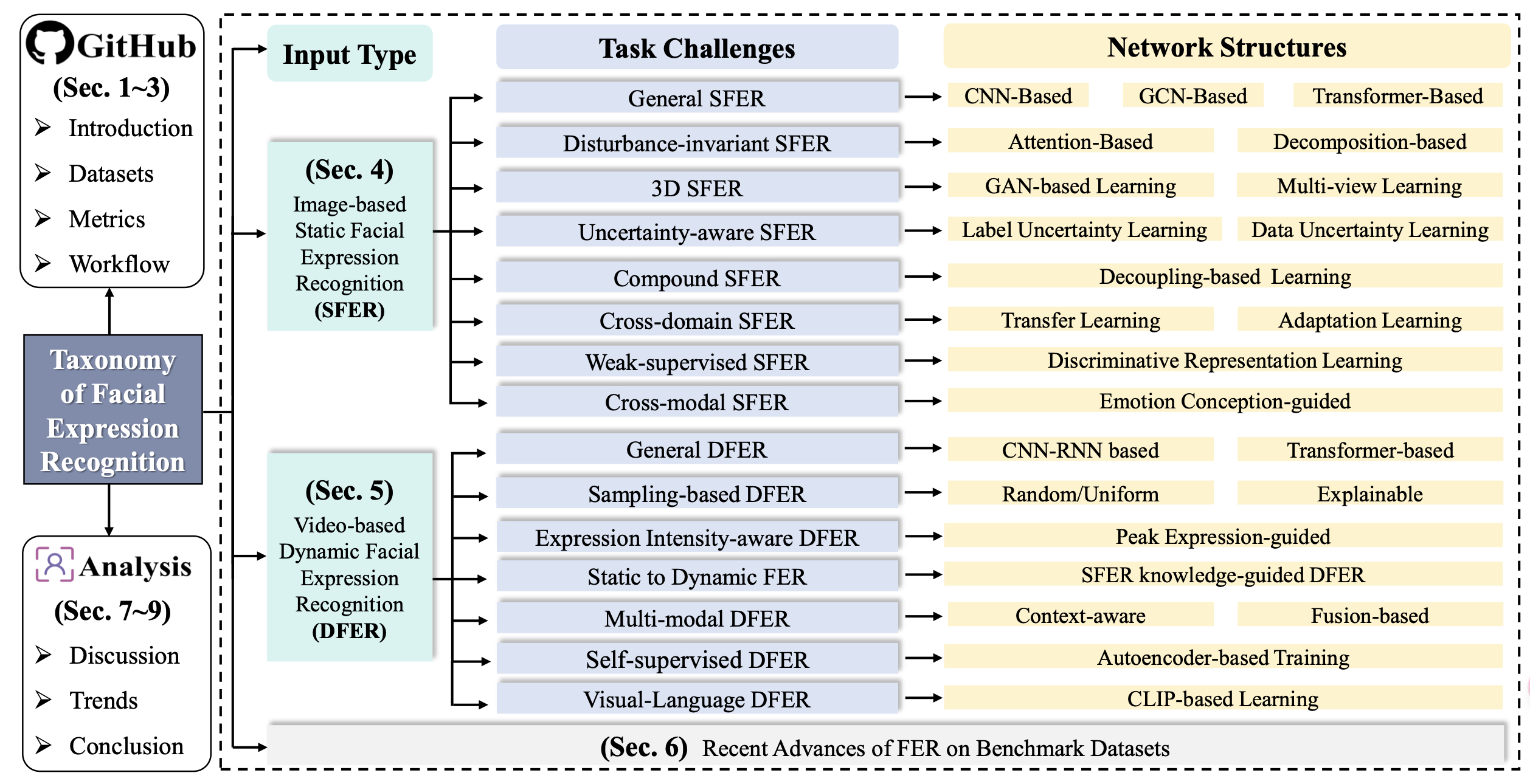
图1:静态和动态情感的面部表情识别(FER)分类体系。我们提出了一个层次化分类体系,在系统框架内根据输入类型、任务挑战和网络结构对现有的FER模型进行分类,旨在提供当前FER研究全貌的全面概述。首先,我们将数据集、评估指标和工作流程(包括文献和代码)引入了一个公共的GitHub仓库中(第1、2和3节)。接着,基于图像的SFER(第4节)和基于视频的DFER(第5节)通过不同的学习策略和模型设计来克服不同的任务挑战。随后,我们分析了FER在基准数据集上的最新进展(第6节)。最后,我们讨论并总结了FER中的一些重要问题和潜在趋势,并强调了未来发展的方向(第7、8和9节)。
综述优势
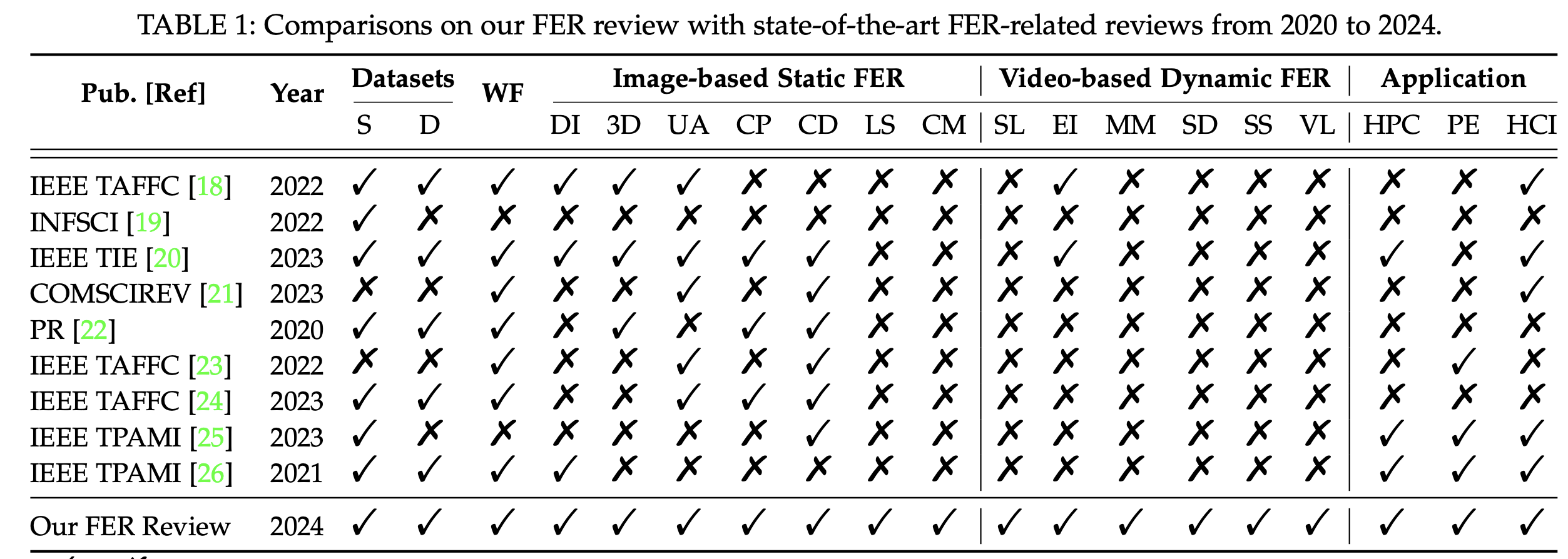
S、D 和 WF 分别表示静态、动态和工作流程。
DI、3D、UA、CP、CD、LS 和 CM 分别表示静态、动态和工作流程。
SL、EI、MM、SD、SS 和 VL 分别表示采样、表情强度、多模态、静态到动态、半监督和视觉-语言。
HPC、PE 和 HCI 分别表示健康与心理咨询、个性化教育和人机交互。
贡献点
为了阐明面部表情识别(FER)的发展并激发未来研究,本综述涵盖了研究背景、数据集、通用工作流程、任务挑战、方法、性能评估、应用、伦理问题以及发展趋势。总的来说,本工作的主要贡献如下:
-
据我们所知,这是第一个将FER研究分为基于图像的静态FER(SFER)和基于视频的动态FER(DFER)的综合性综述,从模型导向的发展扩展到挑战导向的分类,并深入分析了实际环境中的挑战与解决方案。
-
我们系统回顾了SFER中涉及的八大主要挑战(如表情干扰、不确定性、跨域不一致性)和DFER中涉及的七大主要挑战(如关键帧提取、表情强度变化、跨模态对齐)的最新代表性方法。
-
我们总结、分析并讨论了FER在不同基准数据集上的最新进展和技术挑战,涵盖了实验室内FER、自然环境中的SFER和自然环境中的DFER的设置。
-
本综述总结了三个领域的应用和伦理问题,并讨论了发展趋势(如零样本FER和具身面部表情生成),旨在为FER系统提供新的视角和指导。
数据集

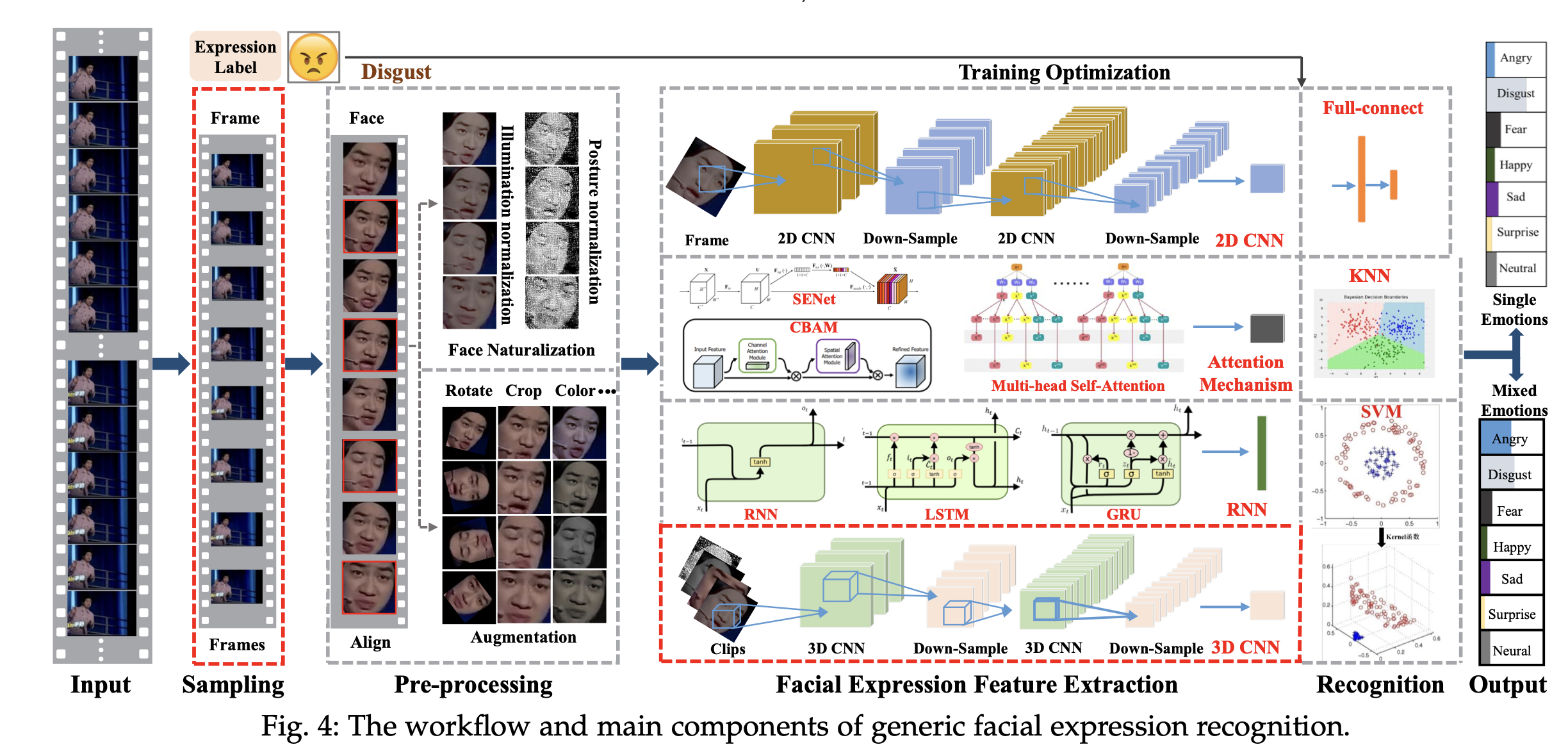
表情识别标准流程
深度学习网络架构
基于图像的静态面部表情识别(SFER)涉及从单张图像中提取特征,这些特征捕捉了与面部表情相关的复杂空间信息,如面部标志点及其几何结构和关系。接下来,我们将首先介绍SFER的一般架构,然后从挑战解决的角度详细说明SFER方法的具体设计,包括抗干扰的SFER、3D SFER、考虑不确定性的SFER、复合SFER、跨域SFER、弱监督SFER和跨模态SFER。
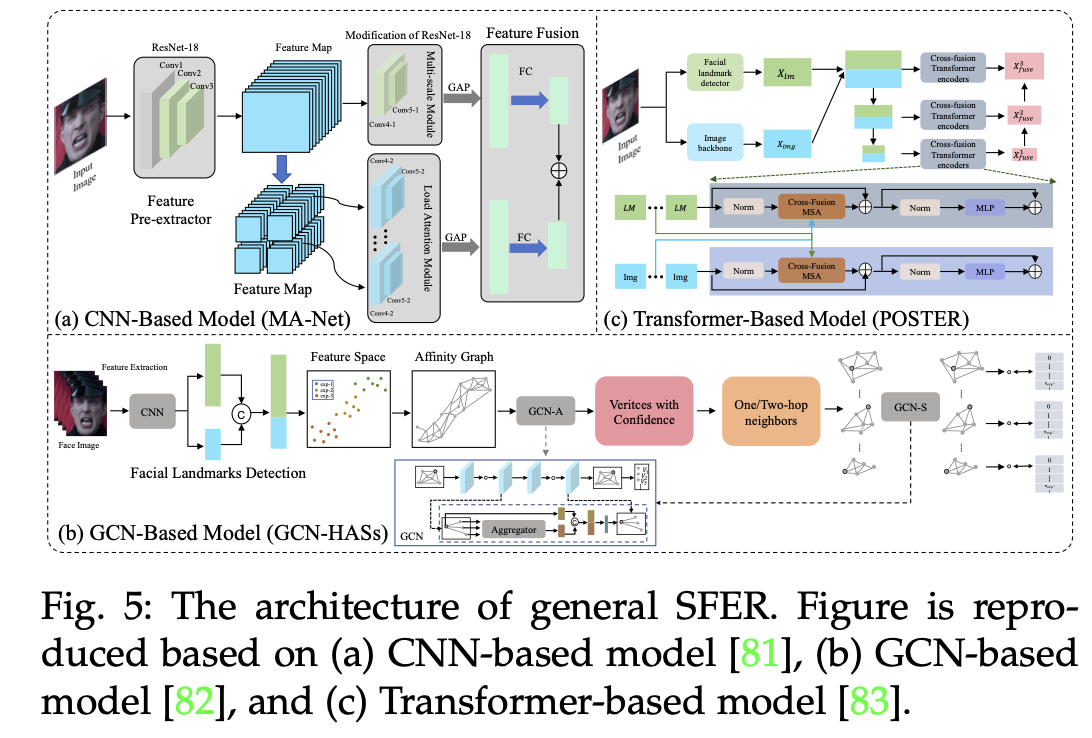
更多类型网络架构图参考论文 https://arxiv.org/pdf/2408.15777
通用的动态面部表情识别(DFER)方法主要通过提取时空特征来分析表情的动态变化。基于CNN-RNN的模型通常结合卷积神经网络(CNN)和递归神经网络(RNN),而基于Transformer的方法则利用深度注意力机制来处理更复杂的动态关系。
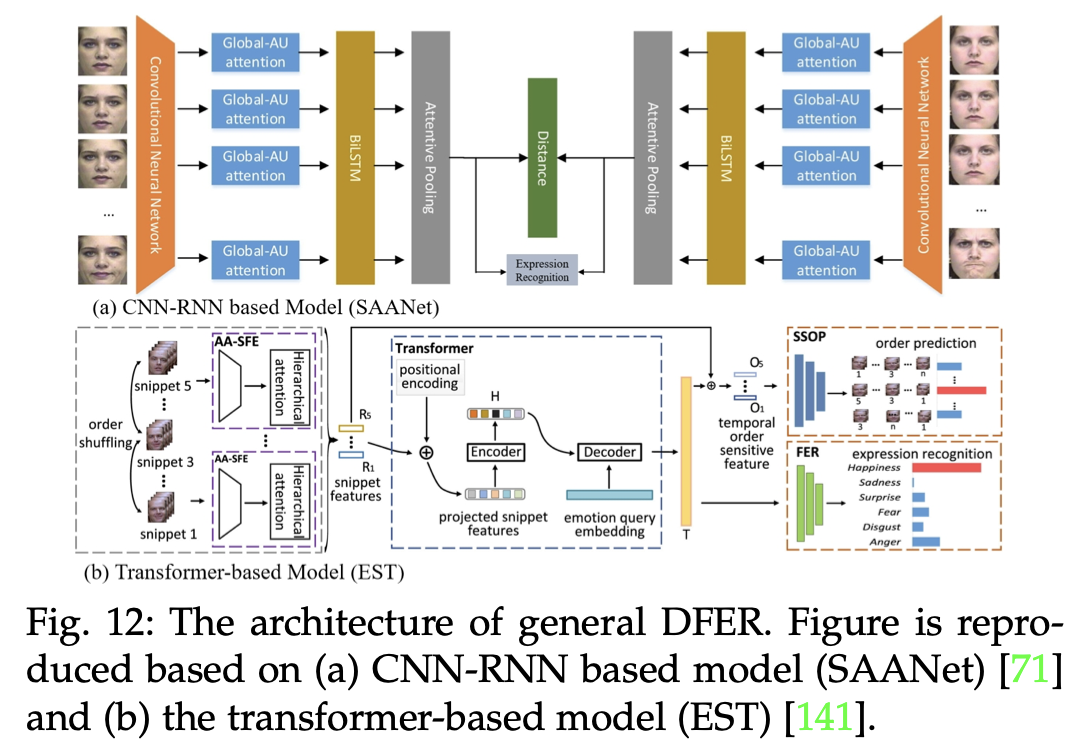
更多类型网络架构图参考论文 https://arxiv.org/pdf/2408.15777
发展趋势
面部动作单元(AUs)辅助的FER通过捕捉细微的肌肉动作,提升了表情识别的准确性和跨文化适应性,并增强了模型的可解释性和透明度。
零样本FER旨在识别未见过的情感类别,解决传统FER模型难以扩展到新情感类别的局限,利用视觉语言模型实现广泛的情感识别。
多模态情感识别通过整合面部表情、声音、手势等多种渠道,提供更全面的情感理解,减少单一模态系统的局限性,展现出更强的鲁棒性和准确性。
具身FER系统结合互动技术,实现对多视角和动态环境的实时情感检测和响应,增强了用户体验,并在复杂环境中展现出更高的适应性。
具身面部表情生成通过AIGC和马达驱动两种方式,使机器人能够更逼真地模仿人类表情,未来研究将专注于提升其真实性和表现力。
结论
面部表情识别(FER)在AI领域受到广泛关注,并在人与机器协作和具身智能方面展现出广阔的应用前景。本综述从多个角度对FER进行了深入审视,包括背景、数据集、通用工作流程、挑战导向的最新方法分类、近期进展、应用、伦理问题和新兴趋势。我们通过表格和图表系统地比较和总结了FER的数据集、任务挑战、方法和性能评估,提供了该领域最新进展的清晰概览。这一全面分析为不同学科的研究人员提供了重要参考,帮助他们快速理解该领域的挑战和进展,进而促进在通用FER系统开发方面的合作。
本文由博客一文多发平台 OpenWrite 发布!