Delete、Drop 和 Truncate
- delete、truncate 仅仅删除表里面的数据,drop会把表的结构也删除
- delete 是 DML 语句,操作完成后,可以回滚,truncate 和 drop 是 DDL 语句,删除之后立即生效,不能回滚
- 执行效率:drop > truncate > delete
MyISAM 与 InnoDB
- InnoDB 支持事务,MyISAM 不支持
- InnoDB 支持外键,MyISAM 不支持
- InnoDB 是聚集索引,数据文件是和索引绑定一起的
- MyISAM 是非聚簇索引,索引和数据文件是分离的,索引保存的是数据的指针
- InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描
- MyISAM 用一个变量保存整个表的行数,执行上述语句时只需要读出改变量即可,速度很快
- InnoDB 支持表、行(默认)级锁,MyISAM 支持表级锁
Join 语句
left join、right join、inner join 的区别:
left join(左连接):
- 返回包括左表中的所有记录和右表中联结字段相等的记录
- 左表是驱动表,右表是被驱动表
right join(右连接):
- 返回包括右表中的所有记录和左表中联结字段相等的记录
- 右表是驱动表,左表是被驱动表
innner join(等值连接):
- 只返回两个表中联结字段相等的行
- 数据量比较小的表作为驱动表,大表作为被驱动表
join 查询在有索引条件下:
- 驱动表有索引不会使用到索引
- 被驱动表建立索引会使用到索引、
所以在以小表驱动大表的情况下,给大表建立索引会大大提高查询效率
Join 原理:
Simple Nested-Loop:
- 驱动表中的每一条记录与被驱动表中的记录进行比较判断(笛卡尔积)
- 对于两表联结来说,驱动表只会被访问一遍,但驱动表却要被访问到好多遍
Index Nested-Loop:
- 基于索引进行连接的算法
- 他要求被动表驱动表上有索引,可以通过索引来加速查询
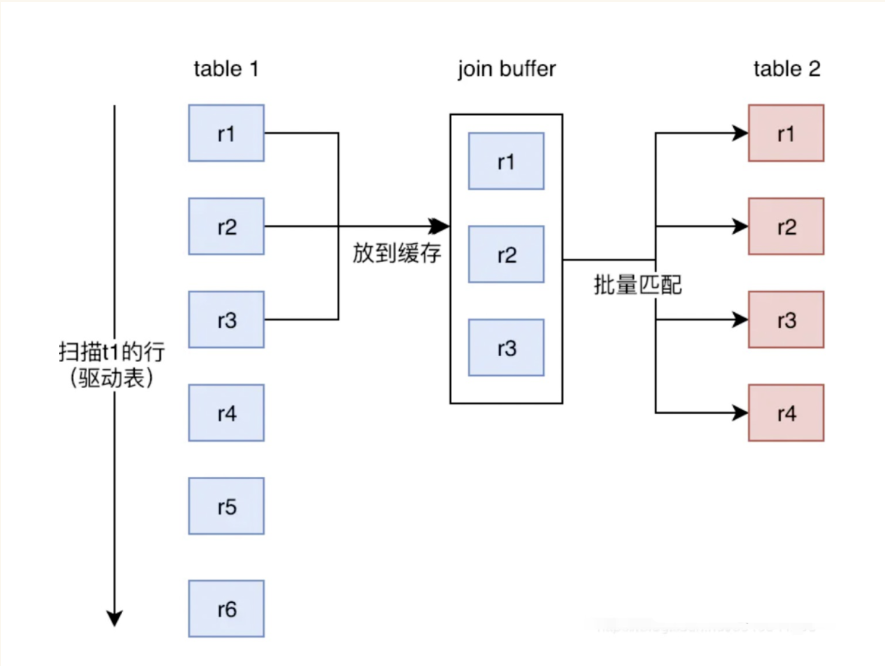
Block Nested-Loop:
- 它使用 Join Buffer 来减少内部循环读取表的次数
- Join Buffer 用以缓存联接需要的列
选择 Join 算法优先级:
- Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
当不使用 Index Nested-Loop Join 的时候,默认使用 Block Nested-Loop Join
分页查询优化
select * from table
where
type = 2
and level = 9
order by id asc
limit 190289,10;
延迟关联:
通过 where 条件提取出主键,再将该表与原数据表关联,通过主键 id 提取数据行,而不是通过原来的二级索引提取数据行
select a.* from table a, (select id from table where type = 2 and level =9 order by id asc limit 190289,10 ) b where a.id = b.id;书签方式:
找到 limit 第一个参数对应的主键值, 在根据这个主键值再去过滤并 limit
select * from table where id > (select * from table where type = 2 and level = 9 order by id asc limit 190289, 1) limit 10;





![[CVPR2024]DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets](https://img2023.cnblogs.com/blog/3039442/202409/3039442-20240922204641858-1290751669.png)