2024-09-22
确实这一块比前面有点难了,先看看这make_token函数在哪。
在nemu目录下执行指令grep -r "make_token",就可以得到这个函数所在路径。
然后看到enum和rule,结合文章可知,这里就是添加规则的地方。
先学一下正则表达式语法
正则表达式语法
.:匹配任意字符(除了换行符)*:匹配前一个字符零次或多次+:匹配前一个字符一次或多次?:匹配前一个字符零次或一次^:匹配字符串开头$:匹配字符串结尾[]:匹配括号内任意字符():创建一个捕获组\\:一个 \ 是转义字符,两个 \ 是表示匹配后面紧跟的字符
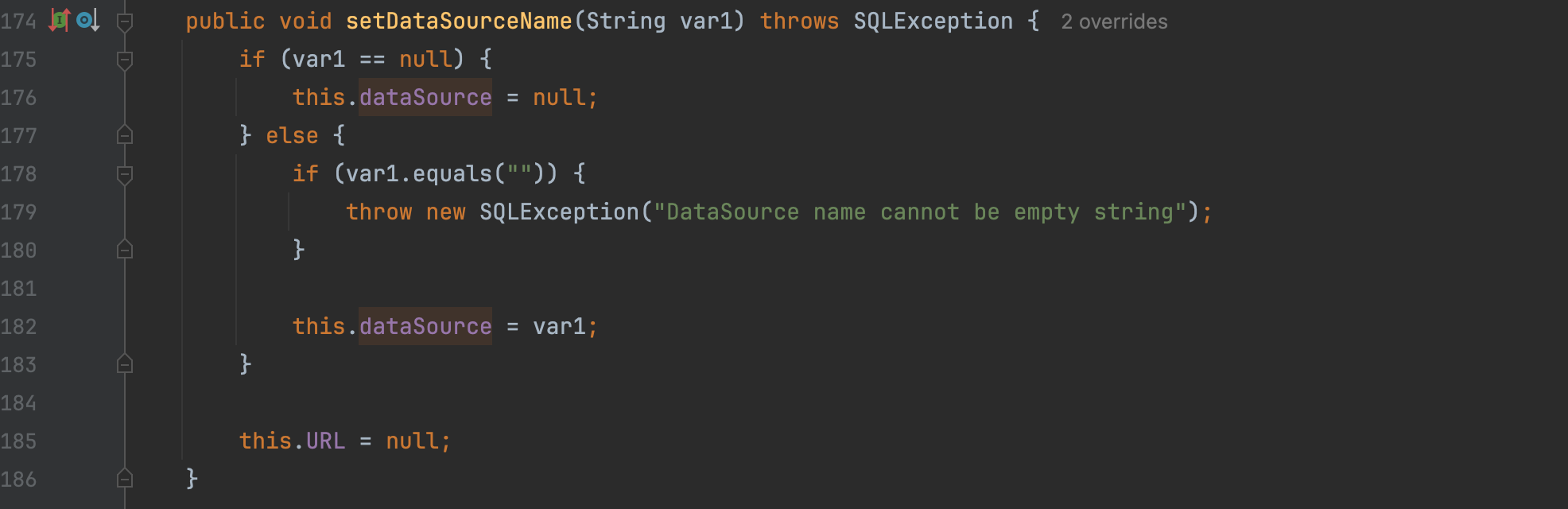
enum里面更改为
enum {TK_NOTYPE = 0, // " "TK_EQ = 1, // ==/* TODO: Add more token types */TK_LEFT = 2, // (TK_RIGHT = 3, // )TK_PLUS = 4, // +TK_MINUS = 5, // -TK_MUL = 6, // *TK_DIV = 7, // /TK_AND = 8, // &&TK_OR = 9, // ||TK_XOR = 10, // ^TK_AR = 11, // access registerTK_PD = 12, // pointer dereferenceTK_NUM = 13, // numberTK_HEX = 14, // hexadecimal
};rule里面更改为
static struct rule {const char *regex;int token_type;
} rules[] = {/* TODO: Add more rules.* Pay attention to the precedence level of different rules.*/{" +", TK_NOTYPE}, // spaces{"==", TK_EQ}, // equal{"\\(", TK_LEFT}, // left bracket{"\\)", TK_RIGHT}, // right bracket{"\\+", TK_PLUS}, // plus{"\\-", TK_MINUS}, // minus{"\\*", TK_MUL}, // multiply{"\\/", TK_DIV}, // divide{"&&", TK_AND}, // and{"||", TK_OR}, // or{"^", TK_XOR}, // xor{"\\$[a-z]?[0-9]+", TK_AR}, // access register{"[0-9]+", TK_NUM}, // number{"0[xX][0-9a-fA-F]+", TK_HEX}, // hexadecimal
};这里解释一下关于访问寄存器部分。可以找到nemu/src/isa/riscv32/reg.c这里关于寄存器的命名。除了一个$0其余都符合一个字符+一个数字的命名方式,所以就这样写了。
剩下一个存token的地方明天再说吧,不早了,得睡觉了。反正后面都得测试,现在对不对也问题不大