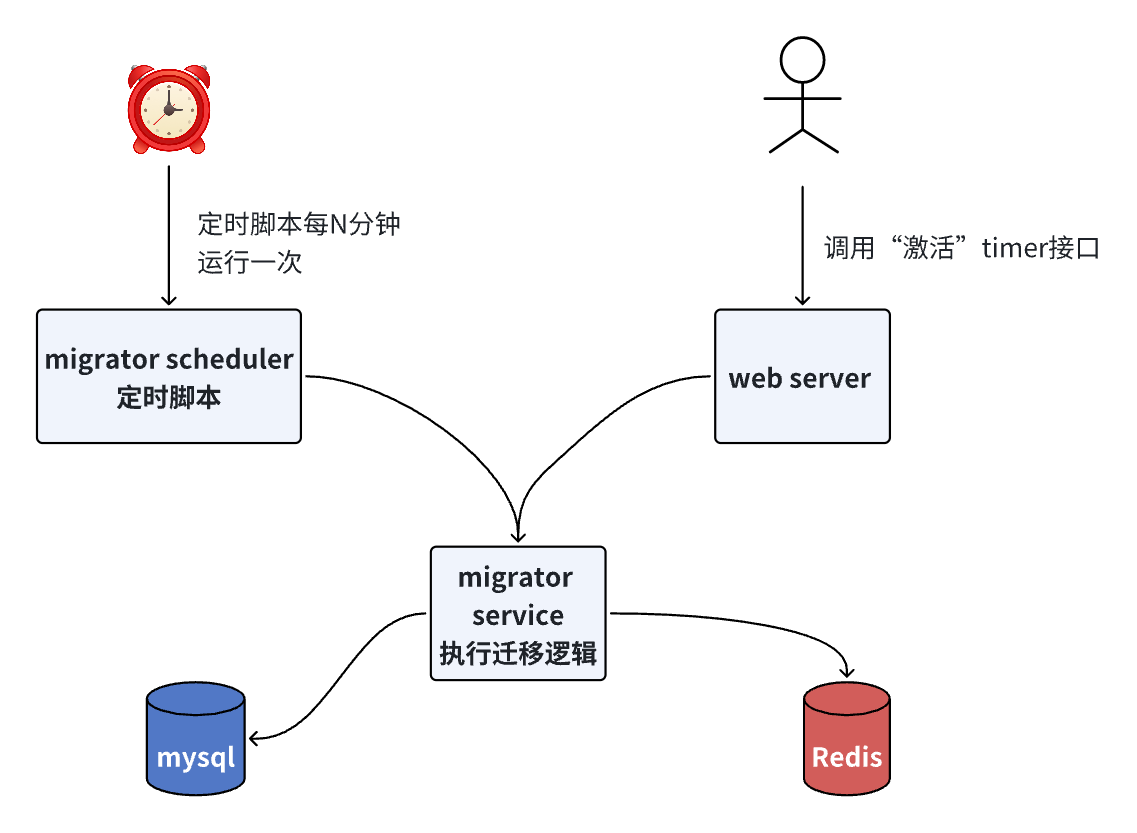
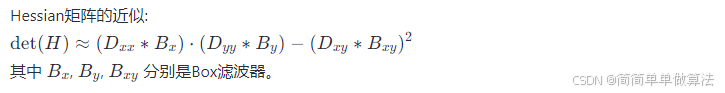好多看不懂的高数内容。。。
第2章 模型评估与选择
2.1 经验误差与过拟合
-
错误率(error rate):分类错误的样本数占样本总数的比例。
若在m个样本中有a个样本分类错误,则错误率\(E=a/m\);
而常说的 精度 则等于\(1-a/m\),即 “精度=1-错误率” ,常写为百分比形式。 -
训练误差(training error)/ 经验误差(empirical error):学习器在训练集上的误差。
-
泛化误差(generalization error):学习器在新样本上的误差。
-
过拟合(overfitting)/ 过配:学习器把训练样本学得“太好”,把训练样本自身的一些特点当作了潜在样本都会具有的一般性质的现象。是机器学习面临的关键障碍,无法彻底避免。
-
欠拟合(underfitting)/ 欠配:学习器对训练样本的一般性质尚未学好的现象。该现象较容易克服。
学习器的学习能力是否“过于强大”,是由学习算法和数据内涵共同决定的。
2.2 评估方法
我们使用“测试集”(testing set)来测试学习器对新样本的判别能力,以测试集上的“测试误差”(testing error)作为泛化误差的近似。
通常假设测试样本也是从样本真实分布中独立同分布采样而得,且测试集应尽可能与训练集互斥。
对包含\(m\)个样例的数据集\(D\)进行适当的处理,从中产生出训练集\(S\)和测试集\(T\),有以下几种常见做法:
2.2.1 留出法
留出法(hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集\(S\),另一个作为测试集\(T\)。
训练/测试集的划分要尽可能保持数据分布的一致性,避免数据划分过程引入额外的偏差而对最终结果产生影响。
- 分层采样(stratified sampling):保留类别比例的采样方式。
另外需要注意,即便在给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据集\(D\)进行分割。因此,单次使用留出法得到的估计结果往往不够稳定可靠。一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
2.2.2 交叉验证法
交叉验证法(cross validation)先将数据集\(D\)划分为\(k\)个大小相似的互斥子集,每个子集$ D_{i} \(都尽可能保持数据分布的一致性,即从\)D\(中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个自己作为测试集。这样就可获得\)k\(组训练/测试集来进行\)k\(次训练和测试,最终返回的是这\)k$个测试结果的均值。
由于交叉验证法评估结果的稳定性和保真性在很大程度上取决于\(k\)的取值,故交叉验证法也被称为“k折交叉验证”(k-fold cross validation)/ “k倍交叉验证”。

与留出法相似,将数据集\(D\)划分为\(k\)个子集存在多种划分方式。k折交叉验证通常要随机使用不同的划分重复p次,最终的评估结果是这 p次k折交叉验证 结果的均值。
假定数据集\(D\)中包含\(m\)个样本,若令\(k=m\),则得到了特例“留一法”(简称\(LOO\))。
留一法的评估结果往往被认为比较准确,但它也有自己的缺陷:数据集较大时,训练\(m\)个模型计算开销可能太大。
2.2.3 自助法
“自助法”(bootstrapping)直接以自助采样法为基础。它能够减少训练样本规模不同造成的影响,还能比较高效地进行实验估计。
给定包含\(m\)个样本的数据集\(D\),对其采样产生数据集\(D^{'}\):每次随机从\(D\)中挑选一个样本,将其拷贝放入\(D^{'}\),然后再将该样本放回初始数据集\(D\)中,使该样本下次采样时仍可能被采到。这个过程重复执行\(m\)次后,即可得到包含\(m\)个样本的数据集\(D^{'}\)。
我们将\(D^{'}\)用作训练集,\(D\) \ \(D^{'}\)用作测试集。
- 包外估计(out-of-bag estimate):实际评估的模型与期望评估的模型都使用\(m\)个训练样本,但仍有部分没在训练集中出现的样本用于测试。
自助法在数据集较小、难以有效划分训练/测试集时很好用。且能从初始数据集中产生多个不同的训练集,对集成学习等方法有很大好处。但自助法产生的数据集改变了初始数据集的分布,这将会引入估计偏差。
所以,在初始数据量足够时,留出法和交叉验证法更常用一些。
2.2.4 调参与最终模型
- 调参(parameter tuning)/ 参数调节:对算法参数(parameter)进行设定。
我们通常将学得模型在实际使用中遇到的数据称为测试数据。
模型评估与选择中用于评估测试的数据集常称为“验证集”(validation set)。也就是说,训练的数据集将被划分为训练集与验证集,测试集是指实际使用时遇到的数据。
模型选择和调参是基于验证集上的性能进行的。
2.3 性能度量
- 性能度量(performance measure):衡量模型泛化能力的评价标准。
在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。即模型的“好坏”是相对的。
- 预测任务中,评估学习器\(f\)的性能,即把学习器预测结果\(f(x)\)与真实标记\(y\)进行比较。
- 回归任务中,使用均方误差(mean squared error)进行性能度量。
- 分类任务中,性能度量的方式更多:
- 错误率与精度
- 查准率、查全率与\(F1\)
- ROC与AUC
- 代价敏感错误率与代价曲线
2.4 比较检验
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据。
有几种常用的机器学习性能比较方法:
- 假设检验
- 交叉验证\(t\)检验
- McNemar 检验
- Friedman 检验 与 Nemenyi 后续检验
2.5 偏差与方差
"偏差-方差分解"(bias-variance decomposition)是解释学习算法泛化性能的一种重要工具。
泛化误差可分解为偏差、方差与噪声之和。
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
- 噪声:表达了当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定的。
但是,偏差与方差之间有着冲突,这称为偏差-方差窘境(bias-variance dilemma)。
学习器训练不足时,偏差主导泛化错误率;随着训练程度加深,方差会逐渐主导泛化错误率。