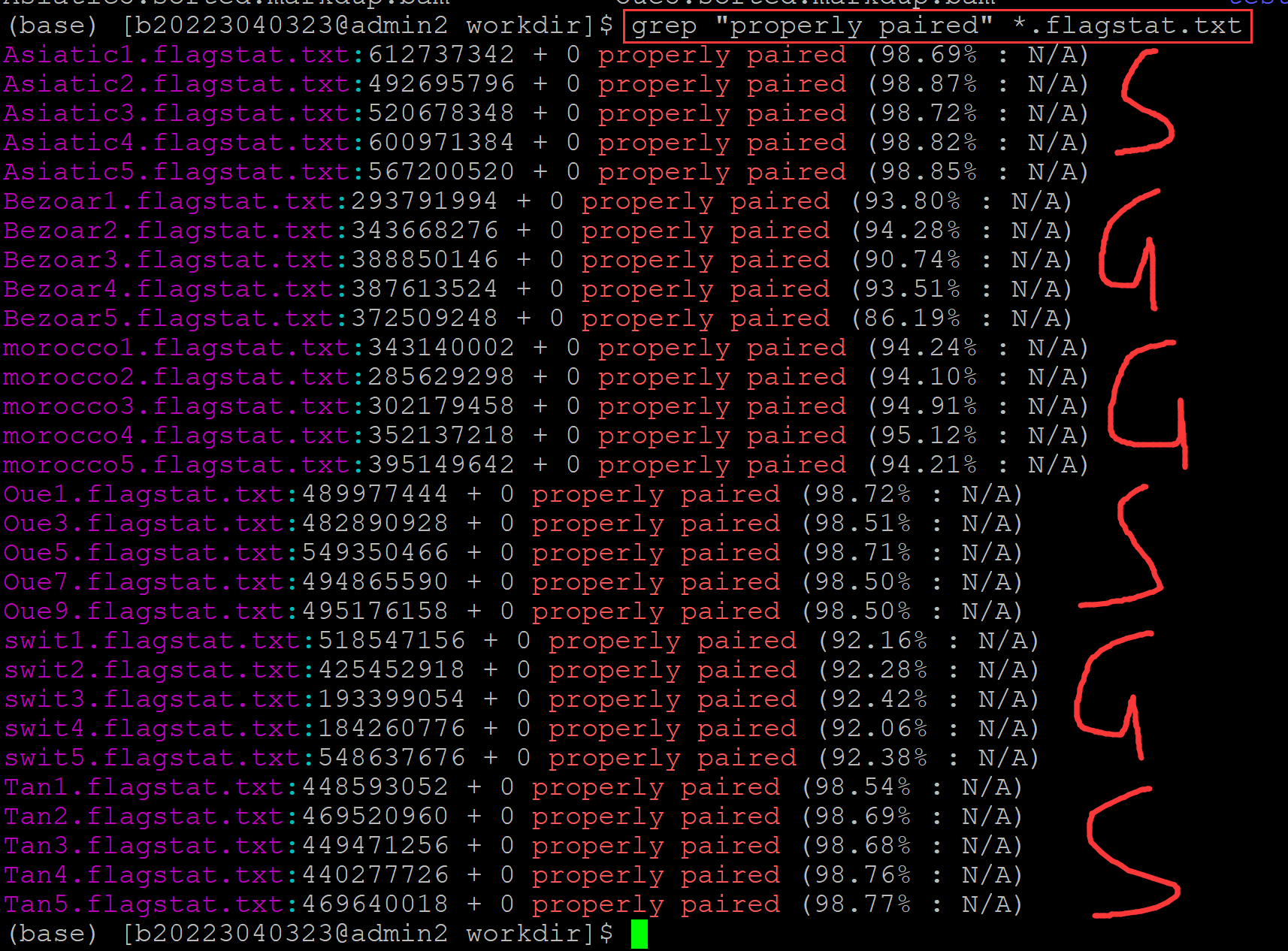
一、前言
经过数周的努力,第三次大作业也落下了帷幕,这三次大作业从第一次到第三次难度逐渐递增,需求不断地增加,对于初学JAVA的我无疑是一个巨大的考验。
第一次大作业,主要侧重类的简单设计,老师在最后一题给出了类的参考设计,算是对我们java的一个入门考验,既是考验,同时也促使我们根据题目提示去学习java的类设计,题目共有5道,就数量上是三次题目中最多的,但是整体难度不高,最后一题主要是考验设计正则表达式匹配输入信息和多个类的整体设计。
第二次大作业,前面几题考察类的有参构建、无参构建和列表的排序,最后一题的本质是第一次大作业最后一题的拓展,加入了列表的排序,并且增加试卷分数信息,与第一题相比加入了评分机制,而且要考虑试卷无效和题目未答的情况,同时还存在多张试卷和多张答卷的情况,设计更复杂,为了避免主类过于臃肿需要做好明确分工。
第三次大作业,在之前的基础上,加入了学生信息,并且输入字符串可能还会出现格式问题,因此,在接收字符串时需要加入格式匹配的判定,这对我们正则表达式的书写提出了更高要求,同时,由于存在试卷、答卷、问题、学生等多个信息,在答题类中,我们要考虑更多信息方面的处理,对代码的要求又上了一个台阶。
二、设计与分析
1、第一次大作业
第一次大作业在三次大作业中属于最简单的一次,第一题,关于风扇类的设计,我参考题目设置私有数据域,并创建有参构建、无参构建,顺利完成题目,之后的三道题目在这道题目的基础上层层推进,逐步完善了类中方法,加入了类自己的展示方法,并且一步步向第五题靠拢,第三题、第四题、本身就是第五题的一部分。
到了第五题,第五题要求我们设计答题判题程序,我们要处理的信息有两种,一种问题信息,一种答案信息,参考题目给出的建议,我设计了四个类:题目类、试卷类,答案类,主类。
概要设计分析
题目类:包含了题号、问题和标准答案三个私有数据域,负责存储题目信息,设置了有参构建方法,设置了获取题目信息的getter方法,有一个判断对错的方法isCorrect。
试卷类:包含了题目数量、还有题目类的列表两个私有数据域,负责存储所有题目,设置了有参构建方法,设置了获取试卷信息的getter方法,也有一个判断对错的方法isCorrect。
答卷类:包含试卷、答案列表、判题结果列表三个私有数据域,负责接收答案并进行判卷,设置了有参构建方法,设置了获取答卷信息的getter方法,在有参有参构建方法中加入了判卷代码,设置了答案输出方法和结果输出方法。
主类:初始化三个类的变量,负责处理接收的字符串,调用类的功能,实现题目需求。
整体类图如下:

SourceMontor的生成报表如下:

具体设计分析:
1、题目类
题目类的信息接收主要通过有参构造来实现,题目类中虽然设置了判题方法,但是我并没有使用过这一方法,对于信息的处理主要在答卷类中实现,在代码中题目类只负责存储题目信息。
2、试卷类
试卷类的信息接收主要通过有参构造来实现,试卷类中虽然也设置了判题方法,但是我并没有使用过这一方法,对于信息的处理主要在答卷类中实现,在代码中题目类只负责存储题目数量和所有题目这两个信息。
3、答卷类
答卷类的信息接收主要通过有参构造来实现,但是它的有参构造只接收试卷信息和答案信息,判题结果信息通过在有参构造中设置代码来实现,截取部分代码如下:
LinkedList<Boolean> result = new LinkedList<>();
for (int i = 0; i < testpaper.getQuestions().size(); i++) {// 计算每个答案是否正确String userAnswer = answer.get(i);Question question = testpaper.getQuestions().get(i);result.add(userAnswer.equals(question.getStandardAnswer()));}this.result = result;
同时根据result这个布尔列表的值,对题目进行for循环,进行结果输出,答案输出则是遍历testpaper中的题目信息列表根据格式加上,result列表的答案进行输出。
4、主类
由于是第一次写最终java代码,主类中我也设置了处理输入信息的功能,由于题目数量已知且输入信息基本符合格式,我首先接收题目数量这一消息,然后用两个循环(判定条件但是接收题目数量或答案数量等于题目数量就退出循环)接收字符串并处理,题目信息放入题目类类型的列表,先排序再最终将它和题目信息放入试卷类的变量中,答案信息则和试卷类信息一起放入答卷类中,最后一起输出结果。
2、第二次大作业
第二次大作业在三次大作业中难度居中,共有四道题目,依旧是层层递进,前几道题主要加入了列表排序的概念,第四题是第一次大作业题目的升级版,这次我们要多处理类试卷分数信息,这一次经过努力,我最终设计了六个类:主类、题目类、试卷类和答案类、答题类、信息处理类,这一次主类只需要调用各个类的方法,本身并没有承担任务。
概要设计分析
题目类:包含了题号、问题和标准答案三个私有数据域,负责存储题目信息,设置了有参构建方法,设置了获取题目信息的getter方法,有一个判断对错的方法checkAnswer。
试卷类:包含了试卷号、题目号列表和题目分数三个私有数据域,负责存储试卷的题目分数信息、试卷号信息,设置了有参构建方法,设置了获取试卷分数信息、试卷号信息的getter方法,有一个获取试卷总分的方法getTotalScore。
答案类:包含了试卷号、试卷答案列表两个私有数据域,负责存储每张试卷的答案信息、试卷号信息,设置了有参构建方法,设置了获取试卷答案信息、试卷号信息的getter方法。
答题类:包含题目类列表、试卷类列表、答案类列表三个私有数据域,负责整合所有信息进行判卷,设置了有参构建方法,设置了私有的判卷方法和输出判卷结果的展示方法。
信息处理类:没有数据域,设置了题目、试卷、答案三种字符串的信息处理方法。
主类:初始化五个类的变量,调用各个类的方法,实现题目需求。
整体类图如下:

SourceMontor的生成报表如下:

具体设计分析:
1、题目类
题目类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中题目类只负责存储题目信息。
2、试卷类
试卷类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中试卷类只负责存储试卷的题目分数信息、试卷号信息。
3、答案类
答案类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中题答案类只负责存储每张试卷的答案信息、试卷号信息。
4、答题类
答题类的信息接收主要通过有参构造来实现,从SourceMontor报表内容可以看出,最大复杂度和最大深度均过于大,考虑到平均复杂度并不大,所有主要原因大概是由于我的私有的判卷方法过于复杂,判题方法通过输入的答卷参数,用一个flag标志数判定是否直到对应试卷,先遍历每张试卷,用if判定试卷和答卷的试卷号是否对应,对应后再用一个嵌套循环查找题目判定对错,并记录分数,找到则输出题目信息和判题结果,没找到就提示不知道题目答案,最后输出分数。这私有方法由展示方法调用,部分代码如图:

5、信息处理类
信息处理类主要是存放了通过正则表达式处理对应字符串的方法,我先在主类中进行判定,在调用对应的处理函数,这样做的好处是简化了主类的内容,主类无需承担过多的功能,只需要调用接收输入,然后交给信息处理类来处理。
6、主类
初始化五个类的变量,将信息处理类处理的结果传入各个类的有参构造方法中,最后由答题类承担所有信息的处理并输出结果,实现题目需求
3、第三次大作业
第三次大作业是最难的,我最终没能拿到满分,前两道题也是对最后一题的功能的部分实现,整体设计上我沿用了第二次大作业的最后一题的框架,最后一题又多了两类信息的处理,分别是学生信息和输出题目信息,并且对题目出现空缺或输出的情况做出了更多的判定要求,而且还加入输入字符串格式错误这一情况,对正则表达式匹配提出了更高要求,因此我设计了十一个类:主类、题目类、试卷类、试卷分数类、答案类、答案信息类、答题类、信息处理类、删除题目类、学生类、学生信息类。
概要设计分析
题目类:包含了题号、问题和标准答案三个私有数据域,负责存储题目信息,设置了有参构建方法,设置了获取题目信息的getter方法,有一个判断对错的方法checkAnswer。
试卷类:包含了试卷号、试卷分数类列表两个私有数据域,负责存储试卷的所有题目分数信息、试卷号信息,设置了有参构建方法,设置了获取试卷分数信息、试卷号信息的getter方法,有一个获取试卷总分的方法getTotalScore。
试卷分数类:包含了题号、题目分数两个私有数据域,负责存储单个题目分数信息、题号信息,设置了有参构建方法,设置了获取单个题目分数信息、题号信息的getter方法。
答案类:包含了试卷号、答案信息列表两个私有数据域,负责存储每张试卷的答案信息、试卷号信息,设置了有参构建方法,设置了获取试卷答案信息、试卷号信息的getter方法。
答案信息类:包含了题号、题目答案两个私有数据域,负责存储单个题目答案信息、题号信息,设置了有参构建方法,设置了获取单个题目答案信息、题号信息的getter方法。
学生类:包含了学生信息类列表一个两个私有数据域,负责存储所有学生的信息,设置了有参构建方法,设置了获取所有学生信息列表的getter方法。
学生信息类:包含了学生的学号、姓名两个私有数据域,负责存储单个学生信息,设置了有参构建方法,设置了获取单个学生信息的getter方法。
删除题目类:包含了删除题目题号列表一个私有数据域,负责存储删除题目题号信息,设置了有参构建方法,设置了获取删除题目题号信息的getter方法。
答题类:包含题目类列表、试卷类列表、答案类列表、删除题目类列表、学生类列表、错误格式题目列表六个私有数据域,负责整合所有信息进行判卷,设置了有参构建方法,设置了多个私有的判卷方法、一个总的判卷方法和输出判卷结果的展示方法。
信息处理类:没有数据域,设置了题目信息、试卷信息、答案信息、学生信息、删除题目信息五种字符串的信息处理方法,不符合格式返回null。
主类:初始化十个类的变量,调用各个类的方法,并负责进行对输入格式的判定,实现题目需求。
整体类图如下:

SourceMontor的生成报表如下:

具体设计分析:
1、题目类
题目类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中题目类只负责存储题目信息。
2、试卷类
试卷类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中试卷类只负责存储试卷的所有题目分数信息、试卷号信息。
3、试卷分数类
试卷分数类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中试卷分数类只负责存储单个题目分数信息、题号信息。
4、答案类
答案类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中答案类只负责存储试卷的所有答案信息、试卷号。
5、答案信息类
答案信息类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中答案信息类只负责单个题目答案信息、题号信息。
6、学生类
学生类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中学生类只负责存储所有学生的信息。
7、学生信息类
学生信息类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中学生信息类只负责存储单个学生信息。
8、删除题目类
删除题目类的信息接收主要通过有参构造来实现,对于信息的处理主要在答题类中实现,在代码中删除题目类只负责存储删除题目题号信息。
9、答题类
答题类的信息接收主要通过有参构造来实现,从SourceMontor报表内容可以看出,最大复杂度和最大深度均过于大,考虑到平均复杂度并不大,所有主要原因大概是由于我的私有的判卷方法过于复杂,判题方法通过传入的答卷参数,遍历试卷进行判定,这次我将对题目、题目答案的处理用其他函数实现,总的判卷方法对各种情况进行判定,判断函数有:题目为空判定、题目不存在判定、题目已删除判定,如果都不满足判定条件,就进行正常判题,最终输出结果,结构与第二题代码类似,只是用函数,封装了部分功能。
部分判定如图:
题目为空判定:
private String getStudentAnswer(List<Answer> answers, int id) {if(id<answers.size()) return answers.get(id).getAnswer();return null; // 没有答案时返回空字符串}
题目不存在判定;
private Testpaper findTestpaperById(int testId) {for (Testpaper testpaper : testpapers) if (testpaper.getId() == testId) return testpaper;return null; // 未找到}
题目已删除判定:
private boolean isQuestionDeleted(int questionId) {for (DeleteQuestion dq : deleteQuestions) if (dq.getQid().contains(questionId)) return true;return false;}
10、信息处理类
信息处理类主要是存放了通过正则表达式处理对应信息的方法,我先在主类中进行判定,在调用对应的处理函数,这样做的好处是简化了主类的内容,主类无需承担过多的功能,只需要调用接收输入,然后交给信息处理类来处理。
11、主类
初始化五个类的变量,将信息处理类处理的结果传入各个类的有参构造方法中,最后由答题类承担所有信息的处理并输出结果,实现题目需求
三、踩坑心得
1、第一次大作业
第一次大作业,由于第一次编写这样的程序,不太熟悉,所有我不加思考地模仿老师的参考设计,但是在细节上没有做到位,导致在每个类中或多或少地存在方法未被使用过的情况,而且主类承担了处理字符串的任务,所以主类的代码显得有些臃肿。
在正则表达式的书写上,我开始没有考虑题目内容前的多余空格情况,所以在测试时总是通不过这个测试点,在修改后我在题目内容的前面加入"//s*"用于吸收空格,最终解决了这个问题,但是三次大作业我的功能具体实现的代码缺乏详尽的注释,导致我需要花费更多时间来理解我自己设计的代码意图。
新的正则表达式如下:
"^#N:\\s*(\\d+)\\s*#Q:\\s*(.*)\\s*#A:\\s*(.*)$"
在接收信息的处理上,我只是简单采用for循环遍历的方法,不具有普适性,第二次大作业就不得不修改了
for (int i = 0; i < num; i++) {String line = scanner.nextLine();Question question = null;//正则表达式频谱部分,省略}questions.add(question);}
2、第二次大作业
第二次大作业,我本来开始想使用第一次大作业的框架,但是在完善代码时,我走入了一个误区,在试卷类的编写时,我想要为试卷类加入更多功能,以减轻答题类的代码量,但是在添加途中,试卷类被我加入了各种类作为私有数据域,到后来,它不仅有试卷相关的处理,同时还承担了大部分答题类的功能,但是由于设计初衷是只为处理试卷相关信息,所以框架套不上,为此,我直接删除试卷类,使它只承担存储试卷信息的功能,最终才顺利完成代码,但是代价是答题类存储大量信息。因此对第三次大作业,我决定,根据输入信息的类型,各建一个类存储信息,在整合进答题类进行处理,但是这也为之后由于信息过多,难以处理埋下伏笔。
3、第三次大作业
第三次大作业信息多,判断复杂,由于我将对信息的全部处理放入一个类中,最终,尽管我艰难完成了代码的完善,但是面对未通过的测试点,我想重新修改的难度就变得非常大,我从中得到的教训是不能将所有功能全部交给一个类来实现,应该在设计之初,就尽量控制单个类的功能数量,同时设计正则表达式时要考虑是否都能匹配,要主动测试它的适用性,这一点可以通过搜索正则表达式匹配工具来辅助实现。
以下是SourceMontor的生成报表,可以看到最大复杂度和平均复杂度相差过大,说明存在一个类过于复杂:

四、改进建议
1、代码注释一定要详细,这样不仅有助于理解代码功能,同时也方便日后改进。
2、对于一个包含多个类的设计框架,对于类的设计一定要慎重,不应让类承担过多功能,也不能将所有处理全部写在一个方法内,尽量避免多个循环嵌套,多个循环不仅难以更改而且任意出错,牵一发而动全身。
3、可以使用多种数据结构,不应该局限在List、数组上,在我的第三次大作业中,由于设计的类过多,我自己都需要先找到类的位置,才能知道类的信息,但是有些类其实可以使用HashMap进行代替,这样可以大大提高效率,因此我们需要主动学习、理解、使用更多的数据结构,才能不至于“书到用时方恨少”,要用的时候都不知道去哪找。
4、在编写代码时,我们就要主动考虑异常情况,提前做好准备,这样即便出现错误也不至于没有头绪。
五、总结
这三次大作业题目逐渐递进,我从开始的摸着石头过河到最后能有一定的思考,我的java编码能力得到了提升,学习了不少编码知识,其中我最大的提升是java类的设计和正则表达式的匹配。
第一次大作业我只能照着老师的参考设计各个类,类与类之间功能重合,而且只是利用for循环处理接收数据,第二次大作业就不适用了,正则表达式方面处理较为简单,且需要处理的信息较少,最后虽然完成了,但是还是存在不足。
第二次大作业,加入了新的信息,并且由于第一次大作业的设计缺陷,在多次在原有类基础上修改失败的情况下,我重新设计类,明确了类的分工,虽然不完美,但是新的类设计还能进行使用,而且第二次类设计,我的思路更为清晰,有了自己的想法,也算是有了小小的进步。
第三次大作业,我最大的收获是对正则表达式的使用,我针对不同的情况,设计新的正则表达式,并匹配信息,最开始DEBUG的时候总是出现部分信息缺失,到后来至少能够接收所有信息,我对正则表达式的使用有了一定的进步。
我现在最需要进一步学习的是类的设计,对于多个类的使用,我们必须平衡好各个类承担的任务,才能降低处理问题的难度。同时,对于数据结构的掌握也是我现在迫切需要的,我现在在题目中使用的数据结构主要都是List、LinkedList,对于如HashMap等数据结构的理解不多,这变相为我的编码增加了难度。
我觉得老师可以在课上结合之前的PTA,讲讲一些新的知识点和新的思路,这样有利于提高编码水平,同时也可以有助于掌握课程内容。






![基于ESP32的桌面小屏幕实战[1]:需求分析与方案选型](https://img2023.cnblogs.com/blog/3361035/202408/3361035-20240825143756523-1683294872.png)