全文链接:https://tecdat.cn/?p=38046
原文出处:拓端数据部落公众号
分析师:Xinzu Du
人脸识别技术作为生物特征识别技术的重要组成部分,在近三十年里得到了广泛的关注和研究,已经成为计算机视觉、模式识别领域的研究热点。然而由于存在光线、背景、人脸遮挡等问题,如何准确识别出人脸存在一定的问题。
解决方案
任务/目标
为了提高人脸识别的准确性,拟采用VGG、RESNET模型。
数据源准备
数据来源于百度,一共有十位明星的图片。由于数据集的像素维度各不相同,需要进一步处理对图像进行变换。
特征转换
将所有图像进行归一化处理,保证图像都是一样的像素。
划分训练集和测试集
每十张图片取一张作为测试集,故训练集和测试集划分为9:1,并且为每张图片添加标签。
建模
VGG模型

RESNET模型
ResNet是一种残差网络,可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。
模型优化
1.上线之前的优化:特征提取,样本抽样,参数调参。

VGG模型测试集准确度
 RESNET模型测试集准确度
RESNET模型测试集准确度

CNN模型测试集准确度
2.上线之后的迭代,根据实际的A / B测试和业务人员的建议改进模型
在此案例中,RESNT模型在测试机上的准确度最高。所以在模型预测的时候都采用RESNET的模型。以下是部分预测的结果:


只是为了让结果看起来更加直观,所以抽了一些图片进行预测,实际上在进行预测的时候,准确度并不算高。判断影响准确度的最大因素是图片本身的质量不高,样本数量也不够大。如果想要继续提高预测准确度,应该使用数据增强的手段增加样本,或者继续修改模型。
如何在 Keras 中使用 VGGFace2 执行人脸识别|附数据代码
近年来,深度学习卷积神经网络在人脸识别领域取得了显著成果,其中由牛津大学视觉几何小组研发的 VGGFace 和 VGGFace2 模型颇具代表性。尽管这些模型实现难度较大且训练需大量资源,但借助免费的预训练模型和第三方开源库,可在 Keras 等标准深度学习库中得以应用,为人脸识别任务提供了有效的解决方案。
人脸识别相关概念及 VGGFace 系列模型
(一)人脸识别概述
人脸识别是从人脸照片中识别和验证人的一般性任务。2011 年出版的《人脸识别手册》提到了人脸识别的两种主要模式:人脸验证(给定面孔与已知身份的一对一映射,比如判断 “这是这个人吗?”)和人脸识别(给定人脸与已知人脸数据库的一对多映射,例如确定 “此人是谁?”)。人脸识别系统可在这两种模式中的一种或两种下运行,旨在自动识别图像和视频中的人脸。
(二)VGGFace 模型
Omkar Parkhi 在 2015 年题为《深度人脸识别》的论文中描述了 VGGFace 模型。该论文的一大贡献是阐述了如何开发一个庞大的训练数据集,用于训练基于现代卷积神经网络的人脸识别系统,使其能与 Facebook 和 Google 用于训练模型的大型数据集相竞争。此数据集后续成为开发深度 CNN 以完成人脸识别和验证等任务的基础,经在大型数据集上训练并在基准人脸识别数据集评估,证明该模型可有效从人脸生成泛化特征。
(三)VGGFace2 模型
Qiong Cao 等人在 2017 年的论文中描述了 VGGFace2 模型相关工作,将其描述为一个更大的数据集,收集目的在于训练和评估更有效的人脸识别模型。
keras-vggface 库的安装与使用
VGGFace2 的作者提供了模型的源代码及可通过标准深度学习框架(如 Caffe 和 PyTorch)下载的预训练模型,但缺少 TensorFlow 或 Keras 的示例。不过,可将模型转换为 TensorFlow 或 Keras 格式并开发模型定义以便使用。在 Keras 中使用 VGGFace2(和 VGGFace)模型的最佳第三方库是 Refik Can Malli 的 keras-vggface 项目和库。
- 查询已安装的软件包:
pip show keras-vggface此命令会总结包的详细信息,如名称、版本、摘要、主页、作者等。
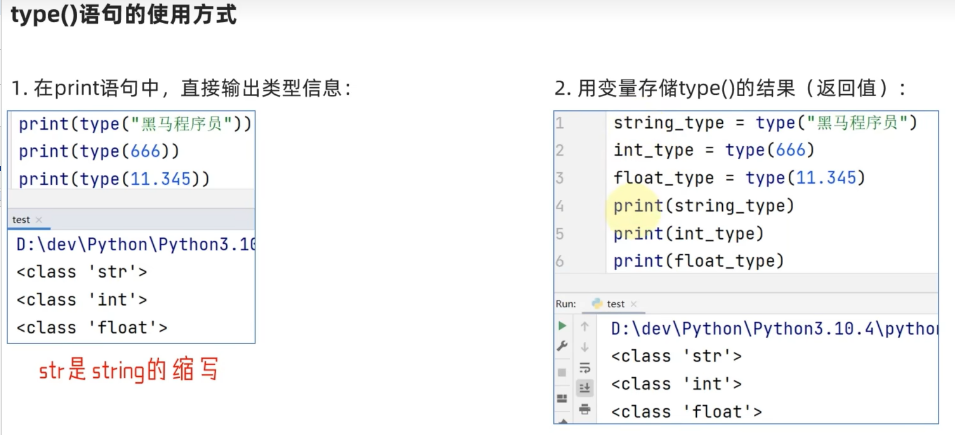
2. 在脚本中加载库并打印当前版本:
-
# 检查keras_vggface的版本
-
import keras_vggface
-
# 打印版本
-
print(keras_vggface.__version__)
运行上述示例可加载库并打印当前版本。
人脸检测方法
在执行人脸识别前,需先进行人脸检测,即自动在照片中定位人脸并通过在其范围周围绘制边界框来确定其位置的过程。本研究采用多任务级联卷积神经网络(MTCNN)进行人脸检测,它是一种先进的人脸检测深度学习模型,相关论文于 2016 年发表。
-
# 从文件加载图像
-
pixels = pyplot.imread(filename)
接着,创建 MTCNN 人脸检测器类并用于检测加载照片中的所有人脸:
-
# 创建探测器,使用默认权重
-
detector = MTCNN()
-
# 检测图像中的人脸
-
results = detector.detect_faces(pixels)
结果是一个边界框列表,每个边界框定义了其左下角坐标以及宽度和高度。若假设照片中只有一张人脸进行实验,可按如下方式确定边界框的像素坐标并提取人脸:
-
# 从第一张脸提取边界框
-
x1, y1, width, height = results[0]['box']
-
x2, y2 = x1 + width, y1 + height
-
# 提取人脸
-
face = pixels[y1:y2, x1:x2]
然后,使用 PIL 库将提取的小面部图像调整为模型所需的大小(如 224×224):
-
# 将像素调整到模型大小
-
image = Image.fromarray(face)
-
image = image.resize((224, 224))
-
face_array = asarray(image)
将上述步骤整合到函数 extract_face()中,可从给定照片文件名中加载并返回提取的人脸
通过从维基百科下载 Sharon Stone 于 2013 年拍摄的照片(文件名为 “sharon_stone1.jpg”)进行测试,运行如下示例可加载照片、提取人脸并绘制结果:
-
# 用mtcnn进行人脸检测的示例
-
from matplotlib import pyplot
-
from PIL import Image
-
from numpy import asarray
-
from mtcnn.mtcnn import MTCNN
-
-
# 从给定照片中提取单张人脸
-
def extract_face(filename, required_size=(224, 224)):
-
# 从文件加载图像
-
pixels = pyplot.imread(filename)
-
# 创建探测器,使用默认权重
-
detector = MTCNN()
-
# 检测图像中的人脸
-
results = detector.detect_faces(pixels)
-
# 从第一张脸提取边界框
-
x1, y1, width, height = results[0]['box']
-
x2, y2 = x1 + width, y1 + height
-
# 提取人脸
-
face = pixels[y1:y2, x1:x2]
-
# 将像素调整到模型大小
-
image = Image.fromarray(face)
-
image = image.resize(required_size)
-
face_array = asarray(image)
-
return face_array
-
-
# 加载照片并提取人脸
-
pixels = extract_face('sharon_stone1.jpg')
-
# 绘制提取的人脸
-
pyplot.imshow(pixels)
-
# 显示绘制结果
-
pyplot.show()

运行上述示例后,可正确检测和提取人脸,且此函数可作为后续 VGGFace 人脸识别模型示例的基础。

使用 VGGFace2 进行人脸识别
(一)创建 VGGFace2 模型
VGGFace 模型可使用 VGGFace()构造函数创建,并通过 “model” 参数指定要创建的模型类型。keras-vggface 库提供了三个预训练的 VGGModels,包括默认的 VGGFace1 模型(model='vgg16')以及两个 VGGFace2 模型('resnet50' 和'senet50')。以下示例创建了一个 'resnet50'VGGFace2 模型,并总结了输入和输出的形状:
-
# 创建人脸嵌入的示例
-
from keras_vggface.vggface import VGGFace
-
-
# 创建一个vggface2模型
-
model = VGGFace(model='resnet50')
-
# 总结输入和输出形状
-
print('Inputs: %s' % model.inputs)
-
print('Outputs: %s' % model.outputs)
首次创建模型时,库会下载模型权重并保存在主目录的 “./keras/models/vggface/” 目录中,“resnet50” 模型的权重大小约为 158 兆字节,下载时间取决于互联网连接速度。运行上述示例会打印出模型的输入和输出张量的形状,该模型需要形状为 224×224 的人脸输入彩色图像,输出将是 8,631 人的类预测,这是因为预训练模型是在 MS-Celeb-1M 数据集(相关信息可在 CSV 文件中列出)中的 8,631 个身份上进行训练的。
(二)进行人脸识别预测
创建好模型后,可直接用于预测给定面孔属于 8000 多位已知名人中的一位或多位的概率,示例如下:
-
# 进行预测
-
yhat = model.predict(samples)
做出预测后,可利用 keras-vggface 库中的 decode_predictions()函数将类整数映射到名人的姓名,并检索概率最高的前五个姓名,代码如下:
-
# 将预测结果转换为姓名
-
results = decode_predictions(yhat)
-
# 显示最有可能的结果
-
for result in results[0]:
-
print('%s: %.3f%%' % (result[0], result[1]*100))
在用人脸进行预测之前,需按照拟合 VGGFace 模型时准备数据的相同方式对像素值进行缩放,即使用训练数据集中的平均值在每个通道上居中,可通过 keras-vggface 库中提供的 preprocess_input()函数并指定 “version=2” 来实现,示例如下:
-
# 将一张脸转换为样本
-
pixels = pixels.astype('float32')
-
samples = expand_dims(pixels, axis=0)
-
# 为模型准备人脸,如居中像素
-
samples = preprocess_input(samples, version=2)
以下是完整的使用 VGGFace2 模型进行人脸识别的示例,通过下载 Sharon Stone 的照片(“sharon_stone1.jpg”)进行测试,提取单个人脸并预测其身份,然后显示前五个最高概率的名称。
注意:考虑到算法或评估过程的随机性质,或者数值精度的差异,您的结果可能会有所不同(可参考相关资料了解详情)。建议多次运行该示例并比较平均结果。例如,通过上述示例对 Sharon Stone 的照片进行测试,模型正确地识别出这张脸属于 Sharon Stone,可能性为 99.642%。同样,可下载 Channing Tatum 的照片(“channing_tatum.jpg”)进行测试,更改代码加载新照片后,模型可正确将人脸识别为属于 Channing Tatum,概率为 94.432%。

使用 MTCNN 模型从 Sharon Stone 的照片中检测到的人脸
如何使用 VGGFace2 进行人脸识别
(一)VGGFace2 模型的创建及输入输出形状
在利用 VGGFace2 模型进行人脸识别时,首先需创建该模型。VGGFace 模型可借助 VGGFace()构造函数来创建,通过 “model” 参数可指定要创建的具体模型类型。keras - vggface 库提供了三个预训练的 VGGModels,其中默认的是通过 “model = 'vgg16'” 的 VGGFace1 模型,另外还有两个 VGGFace2 模型,分别是 “resnet50” 和 “senet50”。
以下示例展示了创建 “resnet50” VGGFace2 模型并总结其输入和输出形状的过程:
-
# 创建人脸嵌入的示例
-
from keras_vggface.vggface import VGGFace
-
-
# 创建一个vggface2模型
-
model = VGGFace(model='resnet50')
-
# 总结输入和输出形状
-
print('Inputs: %s' % model.inputs)
-
print('Outputs: %s' % model.outputs)
当首次创建该模型时,库会自动下载模型权重并将其保存在主目录下的 “./keras/models/vggface/” 目录中。“resnet50” 模型的权重大小约为 158 兆字节,下载所需时间取决于您的互联网连接速度。运行上述示例后,会打印出模型的输入和输出张量的形状。我们可以得知,该模型需要输入形状为 224×224 的人脸彩色图像,输出则是针对 8,631 人的类预测。这是因为预训练模型是在 MS - Celeb - 1M 数据集(相关详细信息可在此数据集对应的 CSV 文件中查看,具体链接可参考文中提及的相关网址)中的 8,631 个身份上进行训练的。示例运行结果如下:
-
Inputs: [<tf.Tensor 'input_1:0' shape=(?, 224, 224, 3) dtype=float32>]
-
Outputs: [<tf.Tensor 'classifier/Softmax:0' shape=(?, 8631) dtype=float32>]
(二)利用 VGGFace2 模型进行人脸识别预测
创建好 VGGFace2 模型后,便可利用其进行人脸识别预测。此 Keras 模型可直接用于预测给定面孔属于 8000 多位已知名人中的一位或多位的概率。具体预测过程如下:
-
# 进行预测
-
yhat = model.predict(samples)
在做出预测之后,可通过 keras - vggface 库中的 “decode_predictions()” 函数将预测得到的类整数映射到名人的姓名,并且能够检索出概率最高的前五个姓名,代码及操作如下:
-
# 将预测结果转换为姓名
-
results = decode_predictions(yhat)
-
# 显示最有可能的结果
-
for result in results[0]:
-
print('%s: %.3f%%' % (result[0], result[1]*100))
(三)数据预处理
在用人脸进行预测之前,需要对像素值进行特定的预处理操作。具体而言,像素值必须按照拟合 VGGFace 模型时准备数据的相同方式进行缩放,也就是要使用训练数据集中的平均值在每个通道上使像素值居中。这一操作可通过 keras - vggface 库中提供的 “preprocess_input()” 函数并指定 “version = 2” 来实现,目的是使用用于训练 VGGFace2 模型的平均值(而非 VGGFace1 模型的默认值)来缩放图像。以下是相关代码示例:
-
# 将一张脸转换为样本
-
pixels = pixels.astype('float32')
-
samples = expand_dims(pixels, axis=0)
-
# 为模型准备人脸,比如使像素居中
-
samples = preprocess_input(samples, version=2)
(四)实例分析及结果展示
为了更清晰地展示 VGGFace2 模型在人脸识别中的应用效果,我们以下载的 Sharon Stone 照片(文件名 “sharon_stone1.jpg”)为例进行测试。以下是完整的示例代码:
-
# 用vggface2模型进行人脸检测的示例
-
from numpy import expand_dims
-
from matplotlib import pyplot
-
from PIL import Image
-
from numpy import asarray
-
from mtcnn.mtcnn import MTCNN
-
from keras_vggface.vggface import VGGFace
-
from keras_vggface.utils import preprocess_input
-
from keras_vggface.utils import decode_predictions
-
-
# 从给定照片中提取单张人脸
-
def extract_face(filename, required_size=(224, 224)):
-
# 从文件加载图像
-
pixels = pyplot.imread(filename)
-
# 创建探测器,使用默认权重
-
detector = MTCNN()
-
# 检测图像中的人脸
-
results = detector.detect_faces(pixels)
-
# 从第一张脸提取边界框
-
x1, y1, width, height = results[0]['box']
-
x2, y2 = x1 + width, y1 + height
-
# 提取人脸
-
face = pixels[y1:y2, x1:x2]
-
# 将像素调整到模型大小
-
image = Image.fromarray(face)
-
image = image.resize(required_size)
-
face_array = asarray(image)
-
return face_array
-
-
# 加载照片并提取人脸
-
pixels = extract_face('sharon_stone1.jpg')
-
# 将一张脸转换为样本
-
pixels = pixels.astype('float32')
-
samples = expand_dims(pixels, axis=0)
-
# 为模型准备人脸,比如使像素居中
-
samples = preprocess_input(samples, version=2)
-
# 创建一个vggface模型
-
model = VGGFace(model='resnet50')
-
# 进行预测
-
yhat = model.predict(samples)
-
# 将预测结果转换为姓名
-
results = decode_predictions(yhat)
-
# 显示最有可能的结果
-
for result in results[0]:
-
print('%s: %.3f%%' % (result[0], result[1]*100))
运行上述示例代码,将会加载照片,提取出我们已知存在的单个人脸,然后对该人脸的身份进行预测,并显示出概率最高的前五个姓名。
-
b' Sharon_Stone': 99.642%
-
b' Noelle_Reno': 0.085%
-
b' Elisabeth_R\xc3\xb6hm': 0.03%
-
b' Anita_Lipnicka': 0.026%
-
b' Tina_Maze': 0.019%
我们还可以用另一位名人,比如男性 Channing Tatum 的照片(文件名 “channing_tatum.jpg”)来测试该模型。首先需将其下载并保存在当前工作目录中,然后更改代码以加载该照片,示例如下:
pixels = extract_face('channing_tatum.jpg')使用新照片运行示例后,我们可以看到模型正确地将人脸识别为属于 Channing Tatum,概率为 94.432%,具体结果如下:
-
b' Channing_Tatum': 94.432%
-
b' Eoghan_Quigg': 0.146%
-
b' Les_Miles': 0.113%
-
b' Ibrahim_Afellay': 0.072%
-
b' Tovah_Feldshuh': 0.07%
注意:此部分关于 Sharon Stone 和 Channing Tatum 人脸识别示例的运行结果可参考图 1

通过对不同名人照片的测试,我们发现这个模型虽然并不完美,但对于那些它较为熟悉的名人来说,还是能够有效地进行识别的。同时,您也可以尝试模型的其他版本,比如 “vgg16” 和 “senet50”,然后比较不同版本的结果。例如,在对 Oscar Isaac 的照片进行测试时,发现 “vgg16” 版本是有效的,但 VGGFace2 模型可能效果不佳。此外,该模型还可用于识别新面孔,一种可行的方法是使用新的人脸数据集重新训练模型,可能只需重新训练模型的分类器部分即可。
VGGFace2 模型用于人脸验证
(一)计算人脸嵌入
VGGFace2 模型同样可用于人脸验证,其过程首先涉及计算新给定人脸的人脸嵌入。具体操作如下:
首先,我们可以在没有分类器的情况下加载 VGGFace 模型,通过将 “include_top” 参数设置为 “False”,“input_shape” 参数指定输出的形状,并将 “pooling” 参数设置为 “avg”,这样便可使用全局平均池化将模型输出端的滤波器映射减少为向量,代码如下:
-
# 创建一个vggface模型
-
model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg')
然后,利用此模型进行预测,该预测将会返回作为输入提供的一个或多个人脸的人脸嵌入,代码如下:
-
# 进行预测
-
yhat = model.predict(samples)
我们还可以定义一个新函数 “get_embeddings()”,给定包含人脸的照片的文件名列表,该函数会通过上一节中开发的 “extract_face()” 函数从每张照片中提取一张人脸,由于 VGGFace2 模型的输入需要进行预处理,可通过调用 “preprocess_input()” 函数来实现,之后再预测每个模型的人脸嵌入。以下是 “get_embeddings()” 函数的具体实现代码:
-
# 提取人脸并计算人脸嵌入,针对一组照片文件
-
def get_embeddings(filenames):
-
# 提取人脸
-
faces = [extract_face(f) for f in filenames]
-
# 转换为样本数组
-
samples = asarray(faces, 'float32')
-
# 为模型准备人脸,比如使像素居中
-
samples = preprocess_input(samples, version=2)
-
# 创建一个vggface模型
-
model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg')
-
# 进行预测
-
yhat = model.predict(samples)
-
return yhat
(二)验证人脸匹配
在得到人脸嵌入之后,便可通过计算已知身份的嵌入与候选人脸的嵌入之间的余弦距离来执行人脸验证操作。这一计算可通过 “cosine() SciPy 函数” 来实现。两个嵌入之间的最大距离为 1.0,而最小距离为 0.0。在人脸识别应用中,常见的截止值介于 0.4 和 0.6 之间,比如 0.5,但该值应根据具体的应用程序进行调整。
为了实现人脸验证并解释验证结果,我们定义了 “is_match()” 函数,其具体实现代码如下:
-
# 确定候选人脸是否与已知人脸匹配
-
def is_match(known_embedding, candidate_embedding, thresh=0.5):
-
# 计算嵌入之间的距离
-
score = cosine(known_embedding, candidate_embedding)
-
if score <= thresh:
-
print('>face is a Match (%.3f <= %.3f)' % (score, thresh))
-
else:
-
print('>face is NOT a Match (%.3f > %.3f)' % (score, thresh))
(三)实例分析及结果展示
以下是一个完整的人脸验证代码示例,我们以 Sharon Stone 的照片(如 “sharon_stone1.jpg”)作为已知身份的代表,其他照片(如 “sharon_stone2.jpg”、“sharon_stone3.jpg”、“channing_tatum.jpg”)作为正片和负片用于验证:
-
# 用VGGFace2模型进行人脸验证的示例
-
from matplotlib import pyplot
-
from PIL import Image
-
from numpy import asarray
-
from scipy.spatial.distance import cosine
-
from mtcnn.mtcnn import MTCNN
-
from keras_vggface.vggface import VGGFace
-
from keras_vggface.utils import preprocess_input
-
-
# 从给定照片中提取单张人脸
-
def extract_face(filename, required_size=(224, 224)):
-
# 从文件加载图像
-
pixels = pyplot.imread(filename)
-
# 创建探测器,使用默认权重
-
detector = MTCNN()
-
# 检测图像中的人脸
-
results = detector.detect_faces(pixels)
-
# 从第一张脸提取边界框
-
x1, y1, width, height = results[0]['box']
-
x2, y2 = x1 + width, y1 + height
-
# 提取人脸
-
face = pixels[y1:y2, x1:x2]
-
# 将像素调整到模型大小
-
image = Image.fromarray(face)
-
image = image.resize(required_size)
-
face_array = asarray(image)
-
return face_array
-
-
# 提取人脸并计算人脸嵌入,针对一组照片文件
-
def get_embeddings(filenames):
-
# 提取人脸
-
faces = [extract_face(f) for f in filenames]
-
# 转换为样本数组
-
samples = asarray(faces, 'float32')
-
# 为模型准备人脸,比如使像素居中
-
samples = preprocess_input(samples, version=2)
-
# 创建一个vggface模型
-
model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg')
-
# 进行预测
-
yhat = model.predict(samples)
-
return yhat
-
-
# 确定候选人脸是否与已知人脸匹配
-
def is_match(known_embedding, candidate_embedding, thresh=0.5):
-
# 计算嵌入之间的距离
-
score = cosine(known_embedding, candidate_embedding)
-
if score <= thresh:
-
print('>face is a Match (%.3f <= %.3f)' % ( score, thresh))
-
else:
-
print('>face is NOT a Match (%.3f > %.3f)' % (score, thresh))
-
-
# 定义文件名
-
filenames = ['sharon_stone1.jpg', 'sharon_stone2.jpg',
-
'sharon_stone3.jpg', 'channing_tatum.jpg']
-
# 获取嵌入文件的文件名
-
embeddings = get_embeddings(filenames)
-
# 定义Sharon Stone
-
sharon_id = embeddings[0]
-
# 验证已知的Sharon Stone照片
-
print('Positive Tests')
-
is_match(embeddings[0], embeddings[1])
-
is_match(embeddings[0], embeddings[2])
-
# 验证其他人员的已知照片
-
print('Negative Tests')
-
is_match(embeddings[0], embeddings[3])
运行上述示例,我们可以看到系统在给定 Sharon Stone 照片的情况下,能够正确验证两个阳性病例,具体结果如下:
-
Positive Tests
-
>face is a Match (0.418 <= 0.500)
-
>face is a Match (0.295 <= 0.500)
-
Negative Tests
-
>face is NOT a Match (0.709 > 0.500)
关于分析师

在此对 Xinzu Du 对本文所作的贡献表示诚挚感谢,他在中国农业大学完成了数据科学与大数据技术专业的本科学位,专注深度学习领域。擅长 Python、SQL。