一、前馈神经网络
前馈神经网络(Feedforward Neural Networks, FNN)是人工神经网络中的一种,它的信息流动是单向的,从输入层到隐藏层,再到输入层,没有反向的连接。其中,隐藏层可以有多个,用于处理输入层的数据,且每一个隐藏层通常配合一个非线性的激活函数来进行训练。
前馈神经网络的架构如下:
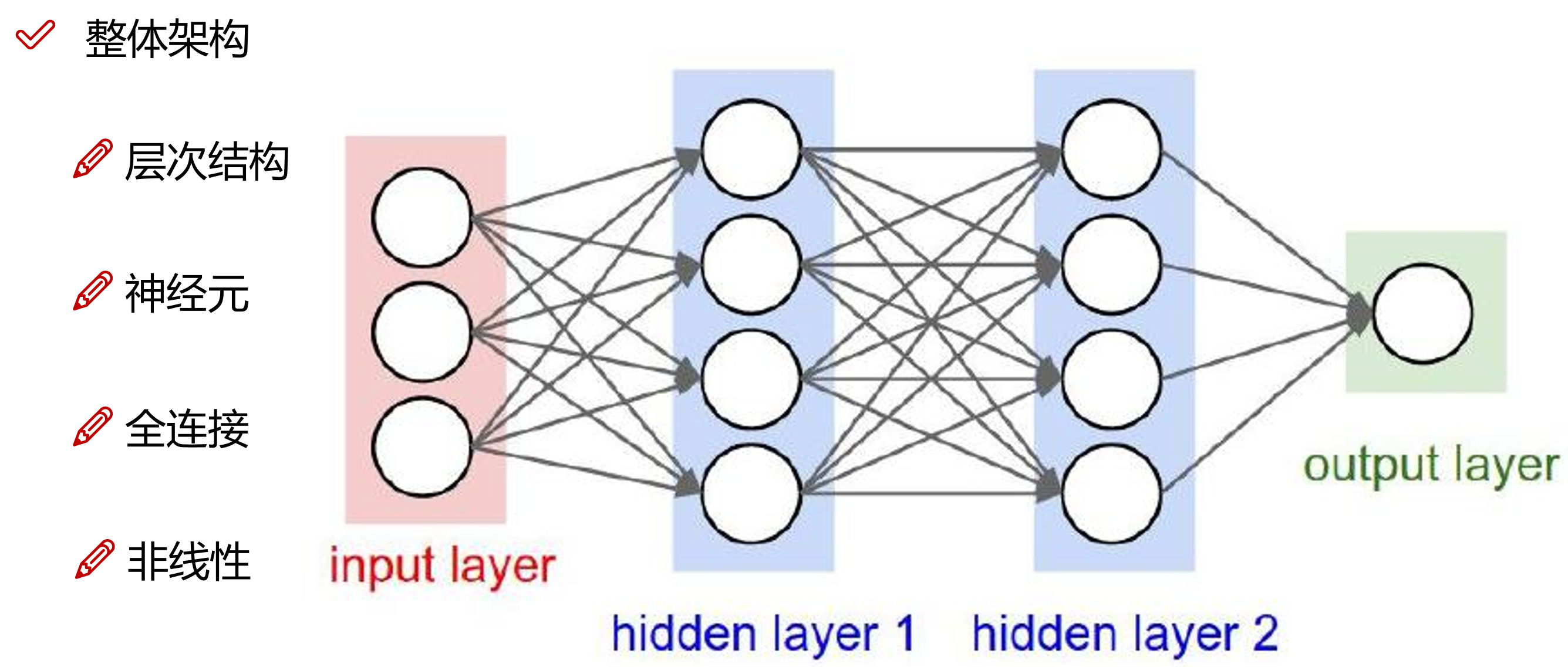
我们通过构建上图的网络模型来进行我们今天的气温预测任务。
首先,我们需要去下载对应的数据集,我们可以通过下面的网址下载到世界上基本所有国家的历史以及实时气温数据:https://rp5.ru
以广州(机场)气象站的气温数据为例,下载 2005.2.1 - 2023.12.31 期间的数据作为训练集,2024.1.1-2024.11.02 期间的数据作为验证集,最后预测 2024.11.03 的温度。
在上述网址下载了数据后,对数据进行简单地手工处理,结果如下:
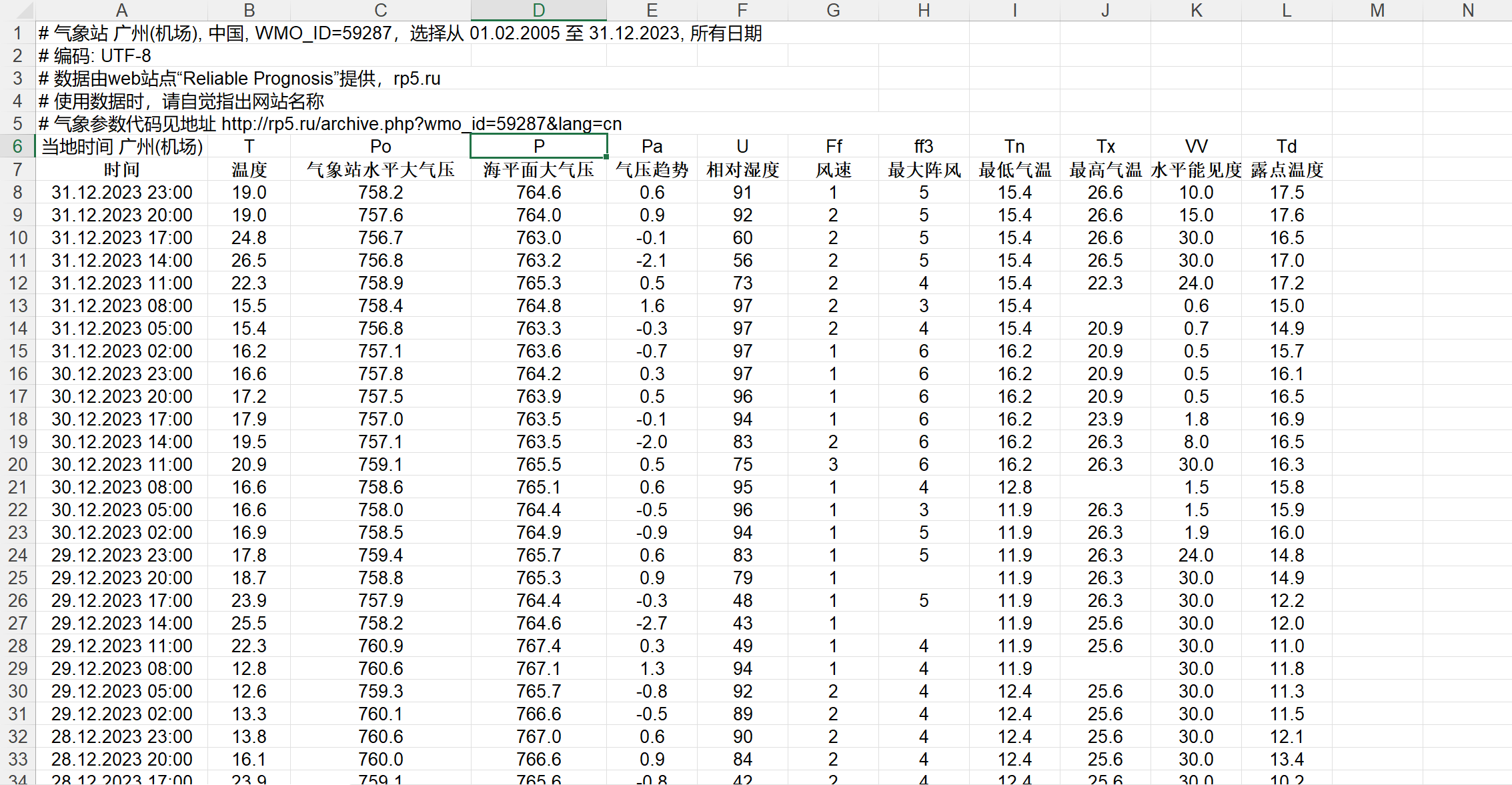
下载完数据集后,我们就可以开始搭建网络进行训练了!
1 导入数据并对数据进行预处理
我们首先在代码中假如如下语句,如有 GPU 则用 GPU 训练,这样能大大提高训练的速度:
# 如有 GPU 则用 GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
然后我们利用 pandas 库中的函数 read_excel 对 excel 中的数据进行读取:
# 导入训练集和验证集
train_file_name = './data/FNN/temperature_history.xls'
valid_file_name = './data/FNN/temperature_2024.xls'
train_features = pd.read_excel(train_file_name, skiprows=6) # 跳过前 6 行无效数据
valid_features = pd.read_excel(valid_file_name, skiprows=6)
由于我们下载的 excel 数据中含有年份时间数据,我们要将其拆分为月、日、时,并舍弃年份,并入到原来的数据中:
# 定义一个函数来拆分日期和时间
def split_datetime(date_str):date_part, time_part = date_str.split(' ')date_parts = date_part.split('.')time_parts = time_part.split(':')return pd.Series([ int(date_parts[1]), int(date_parts[0]), int(time_parts[0])])# 拆分日期和时间,但不保留年份
train_features[['月', '日', '时']] = train_features['时间'].apply(split_datetime)
valid_features[['月', '日', '时']] = valid_features['时间'].apply(split_datetime)# 删除原始的 '时间' 列
train_features.drop('时间', axis=1, inplace=True)
valid_features.drop('时间', axis=1, inplace=True)
查看处理后的数据我们会发现,其中有一些行的特征是空值,我们需要将其剔除,以免影响训练效果:
# 删除包含 NaN 的行(若有特征不存在则删除改行)
train_features.dropna(inplace=True)
valid_features.dropna(inplace=True)
然后,我们通过 print 语句来打印一下,看看我们处理后的数据:
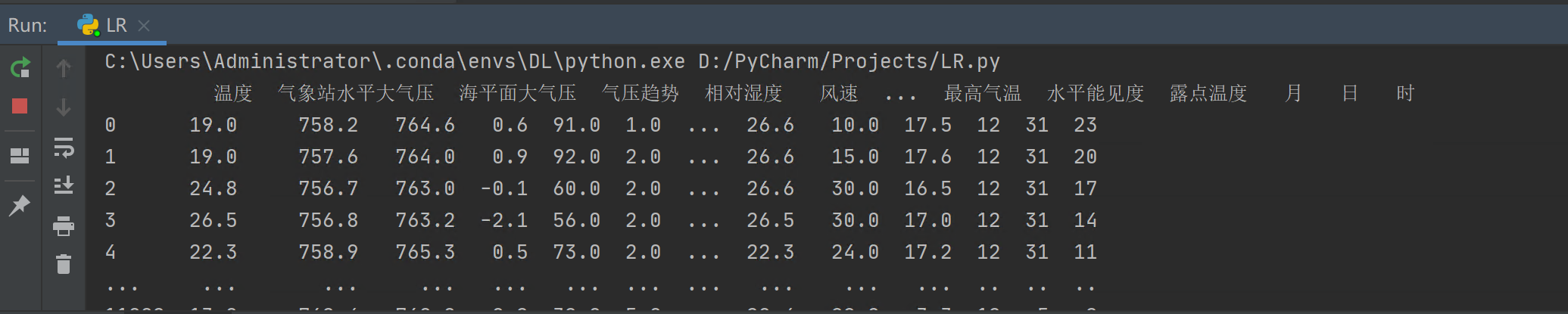
接下来,我们需要将标签从数据中剥离出来,并将数据格式转换为 ndarry(即 numpy 格式):
# 从 features 中取出标签列并转换为 numpy 数据格式
train_labels = np.array(train_features['温度'], dtype=np.float32).reshape(-1, 1)
valid_labels = np.array(valid_features['温度'], dtype=np.float32).reshape(-1, 1)# 从 features 中剔除 ‘温度' 标签列
train_features = train_features.drop('温度', axis=1)
valid_features = valid_features.drop('温度', axis=1)# 将 features 转化为 numpy 数据格式
train_features = np.array(train_features, dtype=np.float32)
valid_features = np.array(valid_features, dtype=np.float32)
在将数据传入到 GPU 训练之前,我们还有一步重要的操作要做,那就是对数据进行标准化操作(以原点为中心对称,缩小取值范围和维度差异)。这是由于,在人工神经网络中,模型并不知道我们传入的特征哪些是重要的,哪些是不重要的,模型会潜在的认为特征值越大就表示该特征越重要,从而会把它所谓的重要的特征学的越大,而实际上,不同维度的取值范围可能会差异很大,所以不同维度的取值范围并不具备参考意义,为了降低模型的误解,需要对数据进行标准化操作:
input_train_features = preprocessing.StandardScaler().fit_transform(train_features)
input_valid_features = preprocessing.StandardScaler().fit_transform(valid_features)
然后我们就可以将 ndarry 格式的数据转为 tensor 格式,传入到 GPU 或 CPU 中:
# 将输入数据从 ndarray 转换成 tensor 并传入 GPU 或 CPU
train_inputs = torch.tensor(input_train_features, dtype=torch.float32).to(device)
valid_inputs = torch.tensor(input_valid_features, dtype=torch.float32).to(device)
train_labels = torch.tensor(train_labels, dtype=torch.float32).to(device)
valid_labels = torch.tensor(valid_labels, dtype=torch.float32).to(device)
二、构建模型
首先我们按照开篇给的网络模型来进行构建:
# 定义模型结构
class FNN(nn.Module):def __init__(self): # 定义模型的构造函数super(FNN, self).__init__() # 调用父类的构造函数self.linear1 = nn.Linear(13, 50) # 输入层到隐藏层1self.linear2 = nn.Linear(50, 100) # 隐藏层1到隐藏层2self.linear3 = nn.Linear(100, 1) # 隐藏层2到输出层self.relu = nn.ReLU() # 非线性激活函数def forward(self, x): # 定义模型的前向传播函数x = self.relu(self.linear1(x)) # 通过第一个隐藏层并激活x = self.relu(self.linear2(x)) # 通过第二个隐藏层并激活x = self.linear3(x) # 通过输出层return x
在这个模型中,我们定义了两个隐藏层(全连接层),每层后面加入了一个非线性激活函数,最后通过输出层进行输出,得到一个预测值。定义好模型结构后,我们将模型进行实例化,并输入到 GPU 或 CPU:
# 初始化模型并把模型输入到 GPU 或 CPU
model = FNN().to(device)
三、设定模型的超参数
接下来我们需要为模型设定超参数,分别是迭代次数、学习率、优化器和损失函数:
epochs = 50000 # 迭代次数
learning_rate = 0.0001 # 学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 优化器
criterion = nn.MSELoss() # 损失函数(均方误差)
四、训练模型并保存参数
设定好超参数之后,我们就可以进行模型的训练了:
# 训练模型
for epoch in range(epochs):epoch += 1# 每次迭代之前将梯度清零optimizer.zero_grad()# 进行前向传播train_outputs = model(train_inputs)# 计算损失train_loss = criterion(train_outputs, train_labels)# 反向传播train_loss.backward()# 更新权重参数optimizer.step()# 每 1000 个 epoch 打印一次损失,跑一次验证集if epoch % 1000 == 0:# 打印损失print('epoch: {0}, train loss: {1}'.format(epoch, train_loss.item()))# 在验证集上评估模型model.eval() # 将模型设置为评估模式with torch.no_grad(): # 关闭梯度计算# 将验证集输入模型,并计算损失valid_outputs = model(valid_inputs)valid_loss = criterion(valid_outputs, valid_labels)# 计算准确率correct = (torch.abs(valid_outputs - valid_labels) < 1.5).sum().item() # 温度误差上下 1.5° 为准确total = valid_labels.size(0)accuracy = correct / total * 100print('epoch: {0}, valid loss: {1}, accuracy: {2:.4f}%\n'.format(epoch, valid_loss.item(), accuracy))model.train() # 将模型转回训练模式
在训练过程中,我们设置每隔 1000 次就去验证集上跑一下损失和准确率,当验证集上跑出的预测温度和实际温度误差在 1.5° 以内,我们就定义为预测正确,然后计算出正确率。
当模型训练完后,我们需要将模型训练好的参数进行保存:
# 训练好后对模型参数进行保存
torch.save(model.state_dict(), './data/FNN/model.pk1')
五、加载模型和训练好的参数用于预测
我们的模型参数训练完毕后已经保存到了本地,之后就可以随时利用本地已经训练好的参数来进行实际温度的预测:
# 如有 GPU 则用 GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 加载模型参数
pred_model = FNN().to(device) # 加载模型到 GPU 或 CPU
pred_model.load_state_dict(torch.load('./data/FNN/model.pk1')) # 加载模型参数
pred_model.eval() # 将模型设置为评估模式# 创建单个数据的输入张量,并添加批次维度,输入数据特征对应如下:
# Po(气象站水平大气压)、P(海平面大气压)、Pa(气压趋势)、U(相对湿度)、Ff(风速)
# ff3(5) 、Tn(最低气温)、Tx(最高气温)、VV(水平能见度)、Td(露点温度)、月、日、时
# 当日上午 8 点的实际温度为:22.3
single_data = [757.7, 764.0, 1.0, 69, 2, 4, 19.7, 27.5, 30, 16.3, 11, 3, 8]
actual_temp = 22.3# 将 list 数据格式转为 numpy 数据格式,并将数据从一维提升到二维
single_data = np.array(single_data, dtype=np.float32).reshape(1, -1)# 对数据进行标准化处理
single_data = preprocessing.StandardScaler().fit_transform(single_data)# 将 numpy 数据格式转为 tensor 数据格式并传入 GPU 或 CPU
inputs = torch.tensor(single_data, dtype=torch.float32).to(device)# 进行预测
with torch.no_grad():prediction = pred_model(inputs)# 输出预测结果
print('2024-11-03 8:00 的实际温度为:{},模型预测温度为:{}'.format(actual_temp, prediction.item()))
输出的预测结果如下:
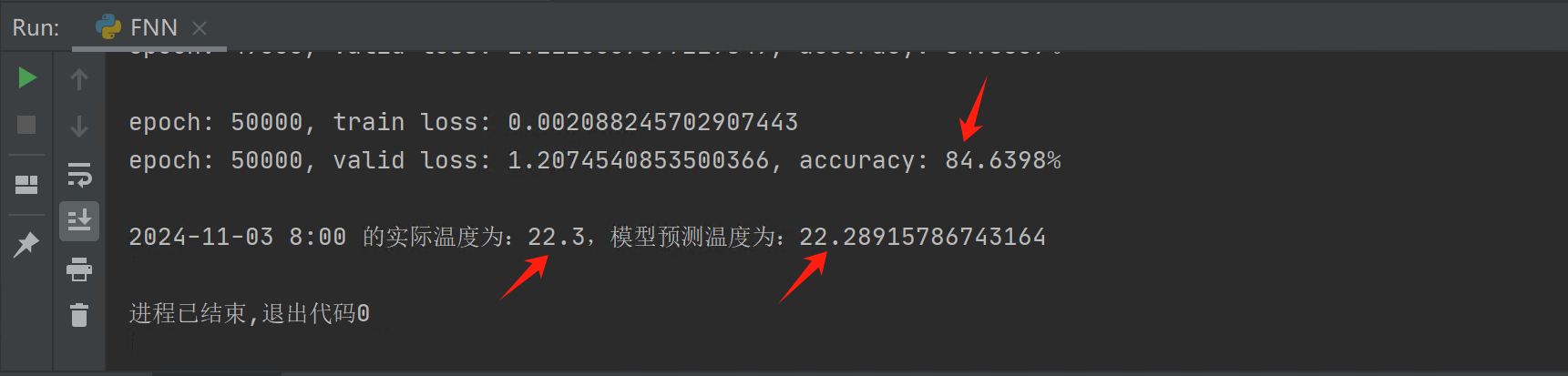
可以从上图看到,我们将学习率设置为 0.0001,并迭代了 50000 次后,能够在验证集上跑出 84.6398% 的准确率,并且我们加载训练好的参数,对 2024-11-03 8:00 时的气温进行了预测,和实际温度基本一致,说明模型训练的效果还算可以。











