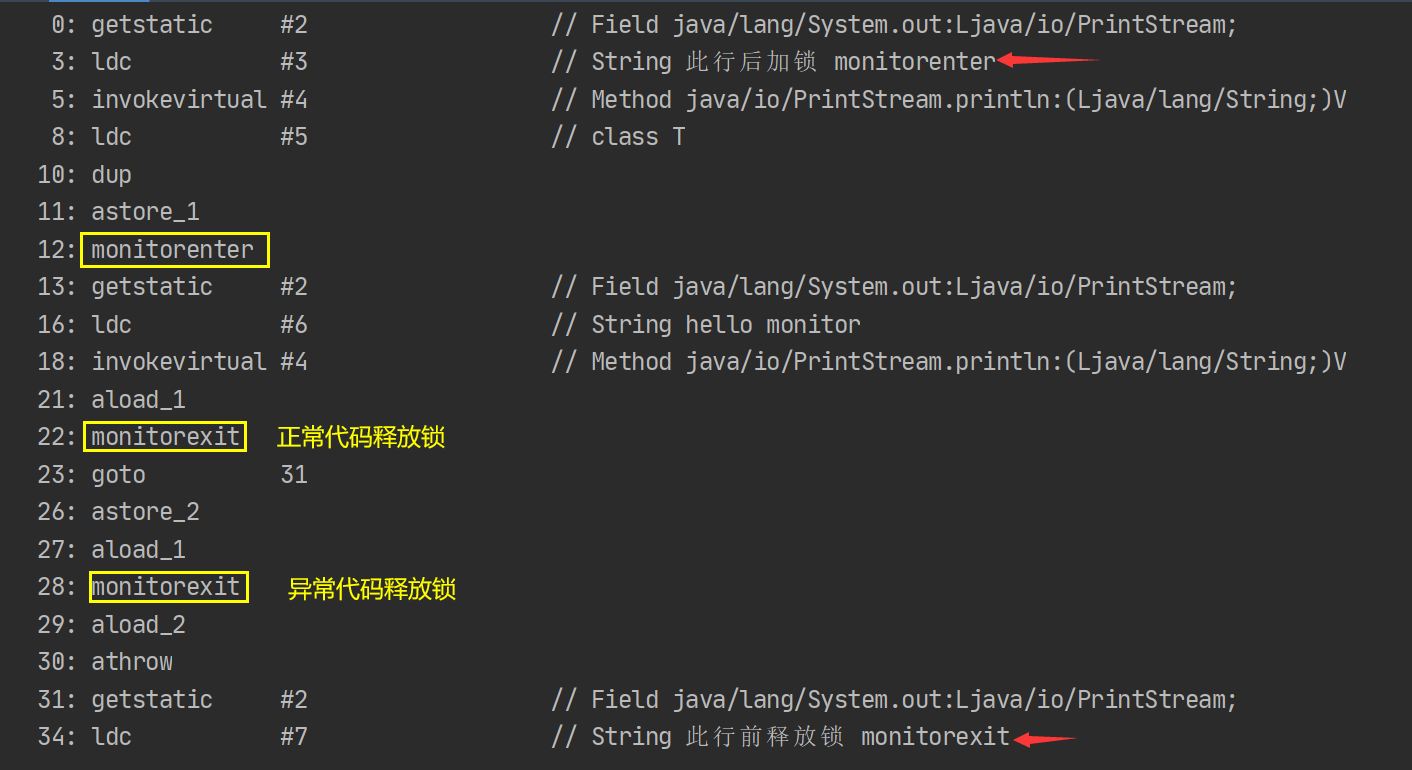
1. OLAP可视化实现(需要提前整合版本)
| Linux121 | Linux122 | Linux123 | ||
|---|---|---|---|---|
| jupyter | ✔ | |||
| spark | ✔ | ✔ | ✔ | |
| python3+SuperSet3.0 | ✔ | |||
| hive | ✔ | |||
| ClinckHouse | ✔ | |||
| Kafka | ✔ | ✔ | ✔ | |
| Phoenix | ✔ | |||
| DataX | ✔ | |||
| maxwell | ✔ | |||
| Hadoop | ✔ | ✔ | ✔ | |
| MySQL | ✔ | |||
| ZK | ✔ | ✔ | ✔ | |
| HBASE | ✔ | ✔ | ✔ |
1.1 安装Vmware,安装虚拟机集群
1.1.1 安装 (VMware-workstation-full-15.5.5-16285975)
许可证:
UY758-0RXEQ-M81WP-8ZM7Z-Y3HDA
1.1.2 安装 centos7






















123456


1.1.3 配置静态IP



vi /etc/sysconfig/network-scripts/ifcfg-ens33

:wq
systemctl restart network
ip addr

ping www.baidu.com
快照
安装jdk
mkdir -p /opt/lagou/software --软件安装包存放目录
mkdir -p /opt/lagou/servers --软件安装目录
rpm -qa | grep java
清理上面显示的包名
sudo yum remove java-1.8.0-openjdk上传文件jdk-8u421-linux-x64.tar.gz
chmod 755 jdk-8u421-linux-x64.tar.gz
解压文件到/opt/lagou/servers目录下tar -zxvf jdk-8u421-linux-x64.tar.gz -C /opt/lagou/serverscd /opt/lagou/servers
ll配置环境
vi /etc/profileexport JAVA_HOME=/opt/lagou/servers/jdk1.8.0_421
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
source /etc/profile
java -version
1.1.4 安装Xmanager
连接192.168.49.121:22密码:123456
1.1.5 克隆2台机器,并配置





vi /etc/sysconfig/network-scripts/ifcfg-ens33

systemctl restart network
ip addr
hostnamectl
hostnamectl set-hostname linux121关闭防火墙
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld关闭selinux
vi /etc/selinux/config

三台机器免密登录
vi /etc/hosts

192.168.49.121 linux121
192.168.49.122 linux122
192.168.49.123 linux123
第一步: ssh-keygen -t rsa 在centos7-1和centos7-2和centos7-3上面都要执行,产生公钥
和私钥
ssh-keygen -t rsa第二步:在centos7-1 ,centos7-2和centos7-3上执行:
ssh-copy-id linux121 将公钥拷贝到centos7-1上面去
ssh-copy-id linux122 将公钥拷贝到centos7-2上面去
ssh-copy-id linux123 将公钥拷贝到centos7-3上面去
ssh-copy-id linux121
ssh-copy-id linux122
ssh-copy-id linux123
第三步:
centos7-1执行:
scp /root/.ssh/authorized_keys linux121:$PWD
scp /root/.ssh/authorized_keys linux122:$PWD
scp /root/.ssh/authorized_keys linux123:$PWD
三台机器时钟同步
sudo cp -a /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.baksudo curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.reposudo yum clean all
sudo yum makecachesudo yum install ntpdatentpdate us.pool.ntp.orgcrontab -e*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org;快照
1.2 安装ZK,Hadoop,Hbase集群,安装mysql
1.2.1 安装hadoop集群(推荐2.7.3版本)
在/opt目录下创建文件夹
mkdir -p /opt/lagou/software --软件安装包存放目录
mkdir -p /opt/lagou/servers --软件安装目录
上传hadoop安装文件到/opt/lagou/software
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz

linux121节点
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/lagou/servers
ll /opt/lagou/servers/hadoop-2.7.3
yum install -y vim添加环境变量
vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
hadoop versionHDFS集群配置
cd /opt/lagou/servers/hadoop-2.7.3/etc/hadoop
vim hadoop-env.shexport JAVA_HOME=/opt/lagou/servers/jdk1.8.0_421
vim core-site.xml<!-- 指定HDFS中NameNode的地址 -->
<property><name>fs.defaultFS</name><value>hdfs://linux121:9000</value>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/lagou/servers/hadoop-2.7.3/data/tmp</value>
</property> vim slaveslinux121
linux122
linux123
vim mapred-env.shexport JAVA_HOME=/opt/lagou/servers/jdk1.8.0_421
mv mapred-site.xml.template mapred-site.xmlvim mapred-site.xml<!-- 指定MR运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
vi mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>linux121:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>linux121:19888</value></property>
vim yarn-env.shexport JAVA_HOME=/opt/lagou/servers/jdk1.8.0_421
vim yarn-site.xml<!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>linux123</value></property><!-- Reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
vi yarn-site.xml
在该文件里面增加如下配置。
<!-- 日志聚集功能使能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 日志保留时间设置7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.log.server.url</name><value>http://linux121:19888/jobhistory/logs</value></property>
chown -R root:root /opt/lagou/servers/hadoop-2.7.3
分发配置
三台都要
sudo yum install -y rsynctouch rsync-script
vim rsync-script#!/bin/bash#1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$#if((paramnum==0)); thenecho no params;exit;fi#2 根据传入参数获取文件名称
p1=$1file_name=`basename $p1`echo fname=$file_name#3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`echo pdir=$pdir#4 获取用户名称
user=`whoami`#5 循环执行rsyncfor((host=121; host<124; host++)); doecho ------------------- linux$host --------------
rsync -rvl $pdir/$file_name $user@linux$host:$pdirdonechmod 777 rsync-script
./rsync-script /home/root/bin
./rsync-script /opt/lagou/servers/hadoop-2.7.3
./rsync-script /opt/lagou/servers/jdk1.8.0_421
./rsync-script /etc/profile
在namenode,linux121上格式化节点hadoop namenode -formatssh localhost集群群起cd $HADOOP_HOME/sbin
start-dfs.sh
datanode可能起不来sudo rm -rf /opt/lagou/servers/hadoop-2.7.3/data/tmp/*hadoop namenode -formatsbin/start-dfs.sh
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该
在ResouceManager所在的机器上启动YARNsbin/start-yarn.shlinux121:
cd /opt/lagou/servers/hadoop-2.7.3
sbin/mr-jobhistory-daemon.sh start historyserver
地址:hdfs:http://linux121:50070/dfshealth.html#tab-overview日志:http://linux121:19888/jobhistorycd /opt/lagou/servers/hadoop-2.7.3
sbin/mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
测试
hdfs dfs -mkdir /wcinputcd /root/
touch wc.txtvi wc.txthadoop mapreduce yarnhdfs hadoop mapreducemapreduce yarn lagoulagoulagou保存退出
: wq!hdfs dfs -put wc.txt /wcinputhadoop jar share/hadoop/mapreduce/hadoop mapreduce-examples-2.7.3.jar wordcount /wcinput /wcoutput
1.2.2 安装zk集群
上传并解压zookeeper-3.4.14.tar.gz tar -zxvf zookeeper-3.4.14.tar.gz -C ../servers/
修改配置⽂文件创建data与log⽬目录
#创建zk存储数据⽬目录
mkdir -p /opt/lagou/servers/zookeeper-3.4.14/data#创建zk⽇日志⽂文件⽬目录
mkdir -p /opt/lagou/servers/zookeeper-3.4.14/data/logs#修改zk配置⽂文件
cd /opt/lagou/servers/zookeeper-3.4.14/conf#⽂文件改名
mv zoo_sample.cfg zoo.cfgmkdir -p /opt/lagou/servers/zookeeper-3.4.14/data
mkdir -p /opt/lagou/servers/zookeeper-3.4.14/data/logs
cd /opt/lagou/servers/zookeeper-3.4.14/conf
mv zoo_sample.cfg zoo.cfgvim zoo.cfg#更更新datadirdataDir=/opt/lagou/servers/zookeeper-3.4.14/data#增加logdirdataLogDir=/opt/lagou/servers/zookeeper-3.4.14/data/logs#增加集群配置
##server.服务器器ID=服务器器IP地址:服务器器之间通信端⼝口:服务器器之间投票选举端⼝口
server.1=linux121:2888:3888
server.2=linux122:2888:3888
server.3=linux123:2888:3888#打开注释
#ZK提供了了⾃自动清理理事务⽇日志和快照⽂文件的功能,这个参数指定了了清理理频率,单位是⼩小时
autopurge.purgeInterval=1 cd /opt/lagou/servers/zookeeper-3.4.14/dataecho 1 > myid安装包分发并修改myid的值
cd /opt/lagou/servers/hadoop-2.7.3/etc/hadoop./rsync-script /opt/lagou/servers/zookeeper-3.4.14修改myid值 linux122echo 2 >/opt/lagou/servers/zookeeper-3.4.14/data/myid 修改myid值 linux123echo 3 >/opt/lagou/servers/zookeeper-3.4.14/data/myid 依次启动三个zk实例例
启动命令(三个节点都要执⾏行行)/opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh start查看zk启动情况
/opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh status集群启动停⽌止脚本vim zk.sh#!/bin/shecho "start zookeeper server..."if(($#==0));thenecho "no params";exit;fihosts="linux121 linux122 linux123"for host in $hostsdossh $host "source /etc/profile; /opt/lagou/servers/zookeeper-3.4.14/bin/zkServer.sh $1"donechmod 777 zk.shcd /root
./zk.sh start
./zk.sh stop
./zk.sh status1.2.3 安装Hbase集群(先启动Hadoop和zk才能启动Hbase)
解压安装包到指定的规划目录 hbase-2.4.15-bin.tar.gztar -zxvf hbase-2.4.15-bin.tar.gz -C /opt/lagou/servers修改配置文件
把hadoop中的配置core-site.xml 、hdfs-site.xml拷贝到hbase安装目录下的conf文件夹中
ln -s /opt/lagou/servers/hadoop-2.7.3/etc/hadoop/core-site.xml /opt/lagou/servers/hbase-2.4.15/conf/core-site.xml
ln -s /opt/lagou/servers/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /opt/lagou/servers/hbase-2.4.15/conf/hdfs-site.xml
修改conf目录下配置文件
cd /opt/lagou/servers/hbase-2.4.15/confvim hbase-env.sh#添加java环境变量
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_421#指定使用外部的zk集群
export HBASE_MANAGES_ZK=FALSEvim hbase-site.xml<configuration><!-- 指定hbase在HDFS上存储的路径 --><property><name>hbase.rootdir</name><value>hdfs://linux121:9000/hbase</value></property><!-- 指定hbase是分布式的 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- 指定zk的地址,多个用“,”分割 --><property><name>hbase.zookeeper.quorum</name><value>linux121:2181,linux122:2181,linux123:2181</value></property></configuration> vim regionserverslinux121
linux122
linux123vim backup-masterslinux122vim /etc/profileexport HBASE_HOME=/opt/lagou/servers/hbase-2.4.15
export PATH=$PATH:$HBASE_HOME/bin分发hbase目录和环境变量到其他节点
cd /opt/lagou/servers/hadoop-2.7.3/etc/hadoop
./rsync-script /opt/lagou/servers/hbase-2.4.15
./rsync-script /etc/profile
让所有节点的hbase环境变量生效
在所有节点执行 source /etc/profile
cd /opt/lagou/servers/hbase-2.4.15/binHBase集群的启动和停止
前提条件:先启动hadoop和zk集群
启动HBase:start-hbase.sh
停止HBase:stop-hbase.sh
HBase集群的web管理界面
启动好HBase集群之后,可以访问地址:HMaster的主机名:16010
hbase shelllinux121:16010
1.2.4 安装mysql
卸载系统自带的mysqlrpm -qa | grep mysqlrpm -e --nodeps mysql-libs-5.1.73-8.el6_8.x86_64安装mysql-community-release-el6-5.noarch.rpmrpm -ivh mysql-community-release-el6-5.noarch.rpm
安装mysql 服务器
yum -y install mysql-community-server启动服务
service mysqld start如果出现:serivce: command not found
安装serviceyum install initscripts配置数据库
设置密码
/usr/bin/mysqladmin -u root password '123'
# 进入mysql
mysql -uroot -p123# 清空 mysql 配置文件内容
>/etc/my.cnf
修改
vi /etc/my.cnf[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8重启查看,授权远程连接service mysqld restart
mysql -uroot -p123
show variables like 'character_set_%';
# 给root授权:既可以本地访问, 也可以远程访问
grant all privileges on *.* to 'root'@'%' identified by '123' with grant
option;
# 刷新权限(可选)
flush privileges;
开启Mysql 的binlog日志vim /etc/my.cnf[mysqld]
log-bin=/var/lib/mysql/mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 slaveId 重复systemctl restart mysqldmysql -root -p123
show variables like '%log_bin%';查看是否生产binlog
cd /var/lib/mysql/
快照
1.3 安装Phoenix,来创建hbase表,安装datax来导入数据到hbase
1.3.1 数据初始化
运行资料中的talents.sql文件
1.3.2 Phoenix安装(按对应hbase版本下载)
https://www.apache.org/dyn/closer.lua/phoenix/phoenix-4.16.1/phoenix-hbase-1.3-4.16.1-bin.tar.gz
下载解压phoenix-hbase-1.3-4.16.1-bin.tar.gztar -xvzf phoenix-hbase-1.3-4.16.1-bin.tar.gz -C ../servers/
拷贝Phoenix整合HBase所需JAR包
cd /opt/lagou/servers/phoenix-hbase-1.3-4.16.1-bin
cp phoenix-server-hbase-1.3-4.16.1.jar /opt/lagou/servers/hbase-2.4.15/libscp phoenix-server-hbase-1.3-4.16.1.jar linux122:/opt/lagou/servers/hbase-2.4.15/libscp phoenix-server-hbase-1.3-4.16.1.jar linux123:/opt/lagou/servers/hbase-2.4.15/lib
cd /opt/lagou/servers/phoenix-hbase-1.3-4.16.1-bin/bin将hbase的配置文件hbase-site.xml、 hadoop/etc/hadoop下的core-site.xml 、hdfs-site.xml放到
phoenix/bin/下,替换phoenix原来的配置文件# 备份原先的 hbase-site.xml文件
mv hbase-site.xml hbase-site.xml.bak
ln -s $HBASE_HOME/conf/hbase-site.xml .
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml .
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml .开启二级索引
登录到RegionSever节点,修改hbase-site.xml配置文件,加入如下配置vi /opt/lagou/servers/hbase-2.4.15/conf/hbase-site.xml
修改<property><name>hbase.zookeeper.quorum</name><value>linux121,linux122,linux123:2181</value>
</property>新增
<property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property><property><name>hbase.table.sanity.checks</name><value>false</value><description>Disables sanity checks on HBase tables.</description>
</property>stop-hbase.sh
start-hbase.sh重启
stop-hbase.sh./zk.sh stop
mr-jobhistory-daemon.sh stop historyserverstop-yarn.sh stop-dfs.shstart-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
./zk.sh start
start-hbase.sh简单的:hbase clean --cleanAll
stop-hbase.sh
start-hbase.sh测试:cd /opt/lagou/servers/phoenix-hbase-1.3-4.16.1-bin/bin./sqlline.py linux121:2181可能会内存不足
free -h1.3.3 Phoenix创建业务表
--用户表
DROP TABLE IF EXISTS "dim_account";
create table "dim_account" (
"id" varchar primary key,
"user"."sex" varchar,
"user"."age" varchar,
"user"."expectcity" varchar,
"user"."expectpositionname" varchar,
"user"."expectpositionnametype1" varchar,
"user"."expectpositionnametype2" varchar,
"user"."expectsalarys" varchar,
"user"."highesteducation" varchar,
"user"."latest_schoolname" varchar,
"user"."_c10" varchar,
"user"."latest_companyname" varchar,
"user"."is_famous_enterprise" varchar,
"user"."work_year" varchar,
"user"."status" varchar) column_encoded_bytes=0;--公司表
DROP TABLE IF EXISTS "dim_company";
create table "dim_company" (
"cid" varchar primary key,
"cy"."companyname" varchar,
"cy"."is_famous_enterprise" varchar,
"cy"."financestage" varchar,
"cy"."city" varchar,
"cy"."companysize" varchar,
"cy"."industryfield" varchar) column_encoded_bytes=0;-- 职位表
DROP TABLE IF EXISTS "dim_position";
create table "dim_position" (
"id" varchar primary key,
"position"."positionname" varchar,
"position"."positionfirstcategory" varchar,
"position"."positionsecondcategory" varchar,
"position"."positionthirdcategory" varchar,
"position"."workyear" varchar,
"position"."education" varchar,
"position"."salarymin" varchar,
"position"."salarymax" varchar,
"position"."city" varchar,
"position"."companyid" varchar,
"position"."createtime" varchar,
"position"."lastupdatetime" varchar) column_encoded_bytes=0;测试
SELECT * FROM "dim_position";
1.3.4 DataX安装
上传并解压datax.tar.gz
tar -xvzf datax.tar.gz -C ../servers/
配置环境变量vi /etc/profileexport DATAX_HOME="/opt/lagou/servers/datax"
export PATH=$PATH:${DATAX_HOME}/binsource /etc/profile
1.3.5 DataX实现全量同步
方便直接查询相应的字段变成json内容
SELECT GROUP_CONCAT('"' , COLUMN_NAME , '"' ORDER BY ORDINAL_POSITION SEPARATOR ',\n')
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'talents' AND TABLE_NAME = 'lg_account';找Phoenix对应的写入包
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","sex","age","expectcity","expectpositionname","expectpositionnametype1","expectpositionnametype2","expectsalarys","highesteducation","latest_schoolname","c10","latest_companyname","is_famous_enterprise","work_year","status"],"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop1:3306/talents"],"table": ["lg_account"]}],"password": "123456","username": "root"}},"writer": {"name": "hbase11xsqlwriter","parameter": {"batchSize": "256","column": ["id","sex","age","expectcity","expectpositionname","expectpositionnametype1","expectpositionnametype2","expectsalarys","highesteducation","latest_schoolname","_c10","latest_companyname","is_famous_enterprise","work_year","status"],"hbaseConfig": {"hbase.zookeeper.quorum": "hadoop4","zookeeper.znode.parent": "/hbase"},"nullMode": "skip","table": "dim_account"}}}],"setting": {"speed": {"channel": "5"}}}
}
--公司表
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["cid","companyname","is_famous_enterprise","financestage","city","companysize","industryfield"],"connection": [{"jdbcUrl": ["jdbc:mysql://linux123:3306/talents"],"table": ["lg_company"]}],"password": "123","username": "root"}},"writer": {"name": "hbase11xsqlwriter","parameter": {"batchSize": "256","column": ["cid","companyname","is_famous_enterprise","financestage","city","companysize","industryfield"],"hbaseConfig": {"hbase.zookeeper.quorum": "linux122","zookeeper.znode.parent": "/hbase"},"nullMode": "skip","table": "dim_company"}}}],"setting": {"speed": {"channel": "5"}}}
}
--职位表
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","positionname","positionfirstcategory","positionsecondcategory","positionthirdcategory","workyear","education","salarymin","salarymax","city","companyid","createtime","lastupdatetime"],"connection": [{"jdbcUrl": ["jdbc:mysql://linux123:3306/talents"],"table": ["lg_position"]}],"password": "123","username": "root"}},"writer": {"name": "hbase11xsqlwriter","parameter": {"batchSize": "256","column": ["id","positionname","positionfirstcategory","positionsecondcategory","positionthirdcategory","workyear","education","salarymin","salarymax","city","companyid","createtime","lastupdatetime"],"hbaseConfig": {"hbase.zookeeper.quorum": "linux122","zookeeper.znode.parent": "/hbase"},"nullMode": "skip","table": "dim_position"}}}],"setting": {"speed": {"channel": "5"}}}
}测试cd $DATAX_HOME/bin
vim $DATAX_HOME/job/mysql2phoenix_account.json
vim $DATAX_HOME/job/mysql2phoenix_company.json
vim po$DATAX_HOME/job/mysql2phoenix_position.json
python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/mysql2phoenix_account.json
python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/mysql2phoenix_company.json
python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/mysql2phoenix_position.json1.3.6 Kafka安装
上传kafka_2.12-1.0.2.tgz到服务器并解压:tar -xvzf kafka_2.12-1.0.2.tgz -C ../servers/安装包分发cd /opt/lagou/servers/hadoop-2.7.3/etc/hadoop
./rsync-script /opt/lagou/servers/kafka_2.12-1.0.2
配置环境变量
vim /etc/profileexport KAFKA_HOME=/opt/lagou/servers/kafka_2.12-1.0.2
export PATH=$PATH:$KAFKA_HOME/bin配置分发
./rsync-script /etc/profile配置生效
source /etc/profile修改linux121的配置文件vim $KAFKA_HOME/config/server.propertiesbroker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux121:9092
log.dirs=/var/lagou/kafka/kafka-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/myKafka分发配置文件./rsync-script $KAFKA_HOME/config/server.properties修改linux122的配置文件broker.id=1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux122:9092
log.dirs=/var/lagou/kafka/kafka-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/myKafka修改linux123的配置文件broker.id=2
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://linux123:9092
log.dirs=/var/lagou/kafka/kafka-logs
zookeeper.connect=linux121:2181,linux122:2181,linux123:2181/myKafka启动kafka集群,每台机器都执行
kafka-server-start.sh $KAFKA_HOME/config/server.properties
测试
cd /opt/lagou/servers/zookeeper-3.4.14/bin
./zkCli.sh
# 查看每个Broker的信息
get /myKafka/brokers/ids/0
get /myKafka/brokers/ids/1
get /myKafka/brokers/ids/2
1.3.7 Maxwell安装(Linux123)
上传解压maxwell-1.29.0.tar.gztar -xvzf maxwell-1.29.0.tar.gz -C ../servers/cd ../servers/maxwell-1.29.0
编写任务配置文件
vim driver.properties
######### binlog ###############
log_level=INFO
producer=kafka
host = linux123
user = maxwell
password = 123456
producer_ack_timeout = 600000
######### binlog ###############
######### output format stuff ###############
output_binlog_position=true
output_server_id=true
output_thread_id=true
output_commit_info=true
output_row_query=true
output_ddl=false
output_nulls=true
output_xoffset=true
output_schema_id=true
######### output format stuff ###############
############ kafka stuff #############
kafka.bootstrap.servers=linux121:9092,linux122:9092,linux123:9092
kafka_topic=mysql_incre
kafka_partition_hash=murmur3
kafka_key_format=hash
kafka.retries=5
kafka.acks=all
producer_partition_by=primary_key
############ kafka stuff #############
############## misc stuff ###########
bootstrapper=async
############## filter ###############
filter=exclude:*.*, include:talents.*新增maxwell用户
mysql -uroot -p123
INSTALL PLUGIN validate_password SONAME 'validate_password.so';
set global validate_password_policy=LOW;
set global validate_password_length=4;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
CREATE USER 'maxwell'@'linux123' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT ALL ON maxwell.* TO 'maxwell'@'linux123';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'linux123';
flush privileges;启动consumerkafka-console-consumer.sh --bootstrap-server linux121:9092,linux122:9092,linux123:9092 --topic mysql_incre
启动maxwell
cd /opt/lagou/servers/maxwell-1.29.0bin/maxwell --config driver.propertiesnohup bin/maxwell --daemon --config driver.properties 2>&1 >> maxwell.log &
重启会出现日志不一致,直接删除maxwell数据库即可
1.3.8 Maxwell实现增量同步
Windows下Scala环境配置
下载scala-2.12.20.msi
windows上安装即可idea配置scala






Flink程序,实现从kafak消费数据,写入Hbase
先看能不能从Kafka拿到数据
/** ** 1 使用flink消费kafka中mysql_incre主题的数据* 2 解析对应的操作,同步数据到hbase指定表中* kafka中消息格式如下:* {"database":"talents","table":"lg_account","type":"update","ts":1612503687,"xid":5254102,* "commit":true,"position":"mysql-bin.000001:125536870","server_id":1,"thread_id":1443,* "schema_id":221,"data":{"id":556,"sex":"男","age":23,"expectcity":"北京","expectpositionname":"广告协调","* expectpositionnametype1":"市场|商务类","expectpositionnametype2":"媒介|公关","expectsalarys":"20k-40k","* highesteducation":"本科","latest_schoolname":"北京工商大学","c10":"0","latest_companyname":"昌荣传媒股份有限公司","* is_famous_enterprise":"1","work_year":"10年","status":"离职找工作"},"old":{"age":33}}*/case class TableObject(database: String, tableName: String, typeInfo: String, dataInfo: String) extends Serializableobject SyncApp {def main(args: Array[String]): Unit = {// 获取flink运行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//创建kafka消费者val kafkaSource: FlinkKafkaConsumer[String] = new SourceKafka().getKafkaSource("mysql_incre")val Stream = env.addSource(kafkaSource)Stream.print()//启动env.execute("mysql_data_incre_sync")}
}再解析拿到的数据
//解析maxwell传递的数据val tableObjectStream: DataStream[TableObject] = Stream.map(msg => {val jsonObject = JSON.parseObject(msg)//获取数据库信息val databaseName = jsonObject.get("database")//获取表信息val tableName = jsonObject.get("table")//获取操作类型val typeInfo = jsonObject.get("type")//获取到最新数据val newData = jsonObject.get("data")TableObject(databaseName.toString, tableName.toString, typeInfo.toString, newData.toString);})tableObjectStream.print()
再写入数据到hbase
见lagou_deliver代码
验证select * from "dim_account" where "id" = '30';
1.4 安装Hive,安装CH,对用户行为数据进行实时OLAP分析

1.4.1 Hive安装(Linux122)
下载mysql-connector-java-5.1.46.jar
https://downloads.mysql.com/archives/c-j/
下载解压apache-hive-2.3.7-bin.tar.gz
http://archive.apache.org/dist/hive/cd /opt/lagou/software
tar zxvf apache-hive-2.3.7-bin.tar.gz -C ../servers/
cd ../servers
mv apache-hive-2.3.7-bin hive-2.3.7vi /etc/profileexport HIVE_HOME=/opt/lagou/servers/hive-2.3.7
export PATH=$PATH:$HIVE_HOME/bin
# 执行并生效
source /etc/profile
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml
vi hive-site.xml新增和修改
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hive元数据的存储位置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://linux123:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC
metastore</description>
</property>
<!-- 指定驱动程序 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC
metastore</description>
</property>
<!-- 连接数据库的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore
database</description>
</property>
<!-- 连接数据库的口令 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12345678</value>
<description>password to use against metastore
database</description>
</property>
</configuration>修改记得去掉 配置文件中的system:,且不用在配置的value里面留空格
cd /opt/lagou/software
cp mysql-connector-java-5.1.46.jar $HIVE_HOME/lib/在mysql中执行-- 创建用户设置口令、授权、刷新
CREATE USER 'hive'@'%' IDENTIFIED BY '12345678';
GRANT ALL ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;schematool -dbType mysql -initSchema
hive
show functions;
1.4.2 业务数据导入hive
create database ods;
use ods;
CREATE EXTERNAL TABLE ods.`ods_company`(
`cid` STRING,
`companyname` string,
`is_famous_enterprise` string,
`financestage` string,
`city` string,
`companysize` string,
`industryfield` string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES
("hbase.columns.mapping"
=":key,cy:companyname,cy:is_famous_enterprise,cy:financestage,cy:city,cy:company
size,cy:industryfield")
TBLPROPERTIES("hbase.table.name" = "dim_company");CREATE EXTERNAL TABLE ods.`ods_account1`(
`id` String,
`sex` string,
`age` String,
`expectcity` string,
`expectpositionname` string,
`expectpositionnametype1` string,
`expectpositionnametype2` string,
`expectsalarys` string,
`highesteducation` string,
`latest_schoolname` string,
`_c10` string,
`latest_companyname` string,
`is_famous_enterprise` string,
`work_year` string,
`status` string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES
("hbase.columns.mapping"
=":key,user:sex,user:age,user:expectcity,user:expectpositionname,user:expectposi
tionnametype1,user:expectpositionnametype2,user:expectsalarys,user:highesteducat
ion,user:latest_schoolname,user:_c10,user:latest_companyname,user:is_famous_ente
rprise,user:work_year,user:status")
TBLPROPERTIES("hbase.table.name" = "dim_account");CREATE EXTERNAL TABLE ods.`ods_position`(
`id` string,
`positionname` string,
`positionfirstcategory` string,
`positionsecondcategory` string,
`positionthirdcategory` string,
`workyear` string,
`education` string,
`salarymin` STRING,
`salarymax` STRING,
`city` string,
`companyid` STRING,
`createtime` string,
`lastupdatetime` string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES
("hbase.columns.mapping"
=":key,position:positionname,position:positionfirstcategory,position:positionsec
ondcategory,position:positionthirdcategory,position:workyear,position:education,
position:salarymin,position:salarymax,position:city,position:companyid,position:
createtime,position:lastupdatetime")
TBLPROPERTIES("hbase.table.name" = "dim_position");1.4.2 CH安装(Linux122)
下载v23.12.1.1368-stable上传4个文件到/opt/lagou/software/clickhouse_rpm
安装
rpm -ivh ./*.rpm
vi /etc/clickhouse-server/config.xml
新增
<listent_host>0.0.0.0</listen_host>

启动
sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml
连接
clickhouse-client -m
1.4.3 实时ETL
根据用户id,职位id,公司id到hbase中查询对应的信息,
插入数据到clickhouse中见lagou_deliver代码
mvn install:install -file -DgroupId=com.clickhouse -DartifactId=clickhouse-jdbc -Dversion=0.6.3 -Dpackaging=jar -Dfile=E:\clickhouse-jdbc-0.6.3.jar
CREATE DATABASE IF NOT EXISTS lg_deliver_detail;drop table lg_deliver_detail.deliver_detail;
CREATE TABLE lg_deliver_detail.deliver_detail(user_id UInt64,work_year String,expectpositionname String,positionid UInt64,positionname String,positionfirstcategory String,positionsecondcategory String,companyid UInt64,companyname String,highesteducation String,company_city String,is_famous_enterprise Int8,companysize String,expectsalarys String,expectcity String,education String,gender String,city String,workyear String,status String,dt String
) ENGINE = MergeTree()
PARTITION BY dt
ORDER BY user_id
SETTINGS index_granularity = 8192;1.4.4 SuperSet安装
安装Python环境mkdir /opt/soft
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda3-latest-Linux-x86_64.sh回车之后,一直按空格,提示Please answer ‘yes’ or ‘no’:’ 输入yes。
指定安装路径/opt/soft/conda,回车默认>>>/opt/soft/conda
PREFIX=/opt/soft/conda初始化conda3,输入yesDo you wish the installer to initialize Miniconda3
[no] >>> yes3) 配置系统环境变量vim /etc/profile
export CONDA_HOME=/opt/soft/conda
export PATH=$PATH:$CONDA_HOME/binsource /etc/profile
source ~/.bashrc可以发现前面多了(base),python版本是3.11取消激活base环境conda config --set auto_activate_base false
bash查看conda版本复制成功
conda --version
conda 24.3.0配置conda国内镜像复制成功
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/conda config --set show_channel_urls yesconda config --show channels7)创建python3.9环境conda create --name superset python=3.9
y
8)激活superset环境conda activate superset
若要退出环境使用以下命令:conda deactivate
Superset部署
1)安装准备依赖复制成功
sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel2)安装setuptools和pippip install --upgrade setuptools pip3)安装supetestpip install apache-superset --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple4)初始化数据库superset db upgrade遇到密匙安全性弱的报错pip show apache-superset进入superset安装路径生成paste_your_generated_secret_key_heropenssl rand -base64 42vi superset_config.pySECRET_KEY = 'paste_your_generated_secret_key_here'SECRET_KEY = 'ocuiR5/s93tYYrIjuGhMFkWrM00tt7Kd3lt2tJ07rAnxgp+cg4jKFmHF'vi /etc/profile export SUPERSET_CONFIG_PATH=/opt/soft/conda/envs/superset/superset_config.pysource /etc/profile5)创建管理员用户export FLASK_APP=superset
superset fab create-adminUsername [admin]:
User first name [admin]:
User last name [user]:
Email [admin@fab.org]:
Password:
Repeat for confirmation:
Recognized Database Authentications.root 123456786)Superset初始化superset init7)安装gunicornpip install gunicorn -i https://pypi.douban.com/simple/8)启动superset
superset run -h linux122 -p 8080 --with-threads --reload --debuggergunicorn --workers 5 --timeout 120 --bind [ip]:[port] "superset.app:create_app()" --daemon
若要停止superset使用以下命令:ps -ef | awk '/superset/ && !/awk/{print $2}' | xargs kill -99)登录 Supersetlinux122:8080用户名:root
密码:12345678访问 ip:[port],并使用前面创建的管理员账号进行登录。
连接数据库:
先安装环境:
conda activate supersetyum install python-devel -y
pip install gevent
sudo yum install groupinstall 'development tools'
yum install mysql-devel -y
yum install gcc -y
pip install mysqlclient报错

pip install mysqlclient==1.4.4
测试

mysql://root:123@linux123/superset_demo?charset=utf8
点击 SQLLab > SQL Editor编写以下SQL语句
选择 数据库

select case when gender = 0 then '男' when gender = 1 then '女' else '保密' end as
gender, count(id) as total_count from t_user group by gender;
保存查询
点击 saved queries

运行查询,点击expolore浏览数据

配置图表类型为 Bar Chart 条形图

指定统计指标 sum(total_count)
指定序列为 gender(性别)
1.4.5 Superset展示ClickHouse数据
安装驱动
见官网文档:
Connecting to Databases | Superset
pip install clickhouse-connect
点击database,新增ch连接
clickhousedb://default:click@linux122:8123/default
clickhousedb://linux122:8123/default新增图表
期望城市分组投递次数select expectcity, count(1) total_cnt from lg_deliver_detail.deliver_detail group by
expectcity;
期望城市分组用户数select expectcity, count(distinct(user_id)) total_user_cnt from
deliver_detail group by user_id,expectcity;
职位所在地分组统计职位数select count(distinct(positionid)) total_jobs, city from deliver_detail
group by city
将之前设计好的图标整合到看板中
操作步骤:
1、点击 Dashboards > 添加看板
2、拖动之前开发好的 Charts 到看板中