通过渐进式混合语境扩散完成Amodal
即使部分隐藏在视线之外,大脑也能毫不费力地识别物体。看到隐藏的可见物被称为amodal完成;然而,尽管进展迅速,但这项任务对生成式人工智能来说仍然是一个挑战。建议避开现有方法的许多困难,这些方法通常涉及预测amodal掩模然后生成像素的两步过程。方法涉及跳出思维定势,真的!走出对象边界框,使用其上下文来指导预训练的扩散修复模型,然后逐步生长被遮挡的对象并修剪额外的背景。克服了两个技术挑战:1)如何避免不必要的共现偏差,这往往会使类似的封堵器再生,2)如何判断amodal完成是否成功。在许多成功的完井案例中,与现有方法相比,amodal完井方法显示出更高的真实感完井结果。最好的部分呢?它不需要任何特殊的训练或对模型进行快速调整。
新方法可以恢复不同图像中对象的隐藏像素,如图3-12所示。

图3-12 新方法可以恢复不同图像中对象的隐藏像素
在图3-12中,遮挡物可能是同时发生的(冲浪板上的人)、意外发生的(微波炉前的猫)、图像边界(长颈鹿)或这些情况的组合。
渐进式闭塞感知完管道,如图3-13所示。
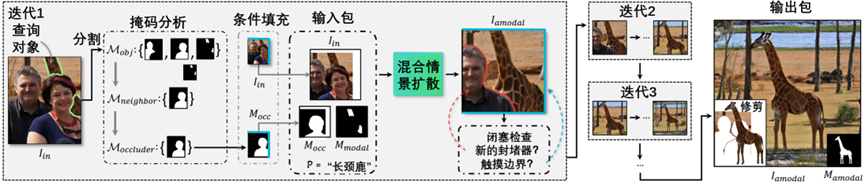
图3-13 渐进式闭塞感知完管道
在图3-13中,第一次迭代:执行实例分割并分析对象掩码以确定遮挡物。如果查询对象接触到图像边界,则填充图像和掩码,以使对象在这些方向上完成边界之外的操作。使用此输入包,运行混合上下文扩散采样以获得新的amodal完成图像。接下来,检查生成的对象是否有新的遮挡物或是否接触到图像边界。原始图像中的男子看起来像一个以前未被发现的新封堵器。附加迭代:如果查询对象仍然被遮挡,那么将运行管道的附加迭代。
输出:返回最终的amodal完成图像和amodal选框的外部,可以修剪额外的背景以覆盖在原始图像上。
混合上下文(MC)扩散采样,如图3-14所示。
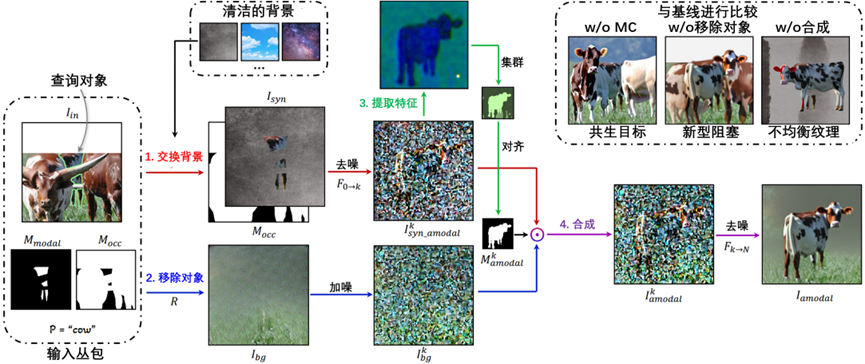
图3-4 混合上下文(MC)扩散采样
在图3-4中,1)交换背景(红色):使用
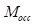
创建
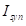
来替换
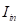
的背景,然后扩散修复到第k个时间步,得到
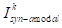
。2)创建对象移除背景图像(蓝色):使用移除修复器从
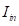
中移除查询对象和遮挡物,然后将噪声添加到第
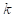
个时间步,产生
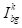
。3)在嘈杂图像中分割对象(绿色):从
中提取扩散特征,对其进行聚类,并通过与
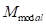
对齐,在第
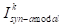
个时间步选择查询对象的amodal掩码
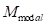
。4) 复合(紫色):使用
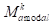
将
中的查询对象放置在去除对象的背景图像
上。最终图像
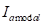
是通过完成剩余的
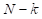
个扩散步骤获得的,其中
是总步骤数。右上角:如果删除此MC