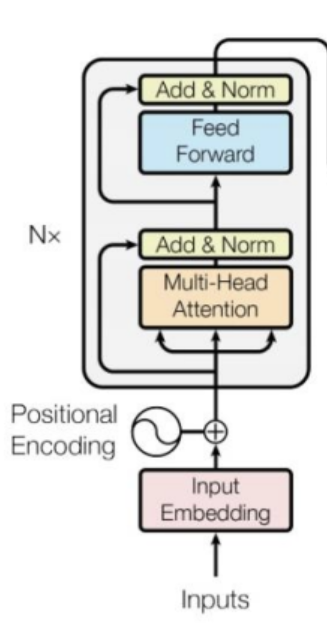
BERT(Bidirectional Encoder Representation from Transformers)
机器阅读理解领域
从名字很好理解,主要使用的方法是Transformer的方法。。进行机器翻译等操作

(1)词嵌入Embedding
词嵌入又有三个部分组成:

Token Embedding

Segment Embedding

Posiiton Embedding
文本出现的位置,进行编码
(2)Transformer Encoder
使用了我们熟知的多头注意力机制

(3)预训练
BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP
MLM
MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。
在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
80%的时候会直接替换为[Mask],将句子 "my dog is cute" 转换为句子 "my dog is [Mask]"。
10%的时候将其替换为其它任意单词,将单词 "cute" 替换成另一个随机词,例如 "apple"。将句子 "my dog is cute" 转换为句子 "my dog is apple"。
10%的时候会保留原始Token,例如保持句子为 "my dog is cute" 不变。
-----摘自知乎
NSP(Next Sentence Prediction)
判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 我 最 擅长 的 [Mask] 是 亚索 [SEP]类别 = IsNext输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 今天 天气 很 [Mask] [SEP]类别 = NotNext
(4)微调
模型微调
原文网址
这里按照自己的理解对该文做出总结