前一篇:《人工智能同样也会读死书----“过拟合”》
序言:你看,人工智能领域的专家都在做什么?他们其实只是在不断试错,因为并没有一种“万能药”——一种万能的算法可以一次性设计出任何人工智能大模型来实现客户的需求。所有的模型在设计和训练过程中都是——验证结构——修改架构——再验证新结构——再修改……最终达到设计的目的。
说难听一点,在当前的技术背景下,从事人工智能模型的设计就是动手实践的经验主义。这个行业需要的,就是您拥有足够的背景知识,能够快速理解并做出反应,以应对这个行业中各种概念的融合。这些概念大部分来自数学、统计学、人文学、社会学、语言学等多个宽泛的领域,也正是这个行业招募硕士、博士、博士后学历背景人才的原因,因为这个行业需要有足够的理论背景来支持。好了,让我们回到重点,本节知识实际上是人为地通过对训练数据集和验证数据集中词汇的相互关系以及维度的大小,迭代模型的架构,最终达到收敛,完成人工智能模型的设计。能理解今天的知识并独立付诸实践的朋友,您就是人工智能领域的专家。大家一起来测试测试吧。
探索词汇大小
Sarcasm 数据集处理的是单词,所以如果你去研究数据集中的单词,特别是它们的频率,你可能会找到一些可以帮助解决过拟合问题的线索。tokenizer 提供了一种方法,可以通过它的 word_counts 属性做到这一点。如果你打印出来,你会看到类似这样的结果,这是一个包含单词和词频元组的 OrderedDict:
wc = tokenizer.word_counts
print(wc)
OrderedDict([('former', 75), ('versace', 1), ('store', 35), ('clerk', 8),
('sues', 12), ('secret', 68), ('black', 203), ('code', 16),...])
这些单词的顺序是由它们在数据集中出现的顺序决定的。如果你查看训练集中的第一条标题,它是一条讽刺性的新闻,关于一位 Versace 前店员的故事。停用词(stopwords)已经被移除了,否则你会看到很多像 “a” 和 “the” 这样频率很高的词。
因为这是一个 OrderedDict,你可以按词频降序对它进行排序,代码如下:
from collections import OrderedDict
newlist = OrderedDict(sorted(wc.items(), key=lambda t: t[1], reverse=True))
print(newlist)
OrderedDict([('new', 1143), ('trump', 966), ('man', 940), ('not', 555),
('just', 430), ('will', 427), ('one', 406), ('year', 386),...])
如果你想把这些数据画成图表,你可以遍历列表中的每一项,把 x 轴的值设为单词在列表中的位置(第 1 项对应 x=1,第 2 项对应 x=2,以此类推),y 轴的值设为 newlist[item] 的词频。然后你可以用 Matplotlib 绘制图表,代码如下:
xs = []
ys = []
curr_x = 1
for item in newlist:
xs.append(curr_x)
curr_x += 1
ys.append(newlist[item])
plt.plot(xs, ys)
plt.show()
绘制出的结果如图 6-6 所示。
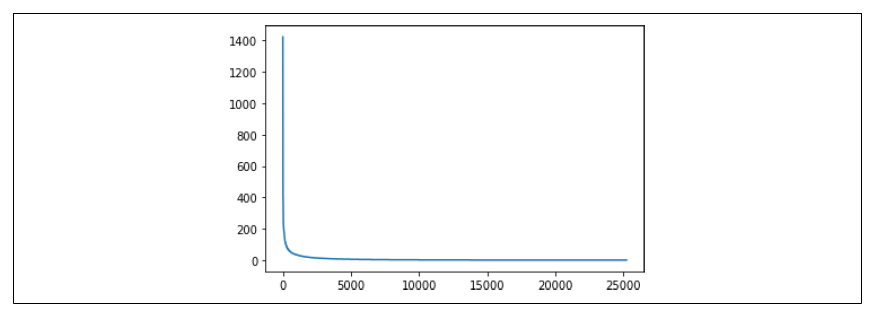
图 6-6:探索单词的频率
这条“冰球棒”曲线告诉我们,只有很少的单词被大量使用,而大多数单词只被使用了很少的次数。但实际上,每个单词在嵌入中都被赋予了相同的权重,因为每个单词在嵌入表中都有一个“条目”。由于训练集的规模相对验证集来说较大,我们会遇到一种情况:训练集中有许多单词,而这些单词并未出现在验证集中。
你可以通过修改图表的坐标轴来放大数据,在调用 plt.show 之前调整坐标轴。例如,如果你想查看 x 轴上单词 300 到 10,000 的范围,以及 y 轴上从 0 到 100 的频率范围,可以使用以下代码:
plt.plot(xs, ys)
plt.axis([300, 10000, 0, 100])
plt.show()
结果如图 6-7 所示。

图 6-7:单词 300–10,000 的频率
虽然语料库中包含了超过 20,000 个单词,但代码仅设置为训练 10,000 个单词。然而,如果我们查看位置 2,000 到 10,000 的单词(这部分占我们词汇表的 80% 以上),可以发现它们每个单词在整个语料库中出现的次数都少于 20 次。
这可能解释了过拟合的原因。现在想象一下,如果你将词汇表大小改为两千并重新训练,会发生什么?图 6-8 显示了准确率指标。此时训练集的准确率约为 82%,验证集的准确率约为 76%。两者之间的差距变小了,而且没有分离开,这表明我们已经解决了大部分的过拟合问题,这是一个好迹象。
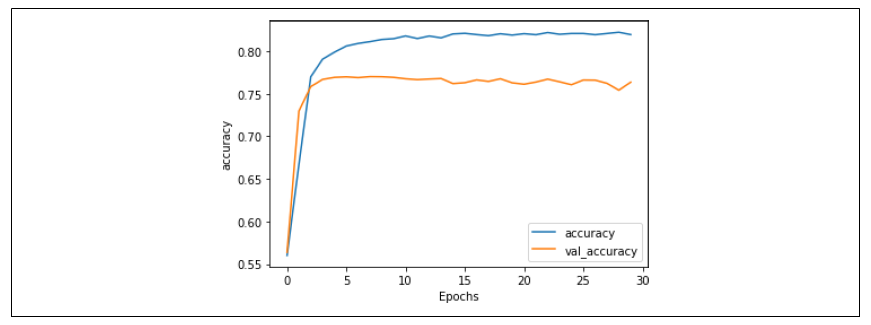
图 6-8:使用两千词汇表时的准确率
这一点在图 6-9 的损失曲线中得到了进一步的验证。验证集的损失确实在上升,但速度比之前慢得多。所以,将词汇表大小减少,防止训练集过拟合那些可能只在训练集中出现的低频词,似乎起到了作用。
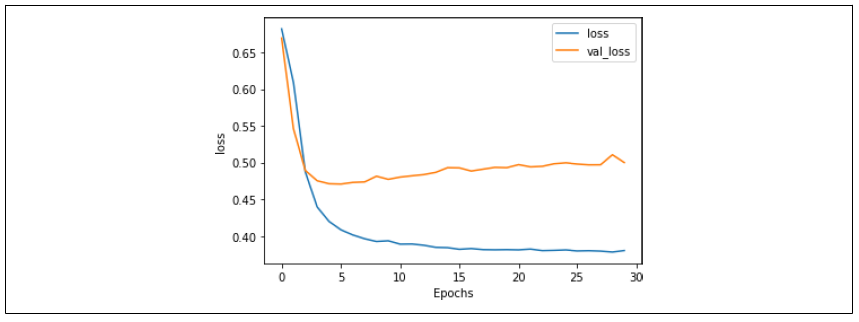
图 6-9:使用两千词汇表时的损失
值得尝试不同的词汇表大小,但要记住,词汇表也可能太小,导致模型过拟合到过少的词汇上。你需要找到一个平衡点。在这个案例中,我选择只保留出现 20 次或更多的单词,这只是一个完全随机的选择。
探索嵌入维度
在这个例子中,嵌入维度被随意地设置为 16。这意味着单词会被编码成 16 维空间中的向量,其方向表示它们的整体意义。但 16 是个合适的数字吗?在词汇表只有两千个单词的情况下,这个维度可能有点高了,导致方向上的高稀疏性。
嵌入大小的最佳实践是让它等于词汇表大小的四次方根。两千的四次方根是 6.687,因此我们可以尝试将嵌入维度改为 7,并重新训练模型 100 个训练周期。
你可以在图 6-9 中看到准确率的结果。训练集的准确率稳定在大约 83%,而验证集的准确率在大约 77%。尽管有些波动,但曲线总体上是平的,说明模型已经收敛了。虽然这和图 6-6 的结果没有太大区别,但减少嵌入维度让模型训练速度快了大约 30%
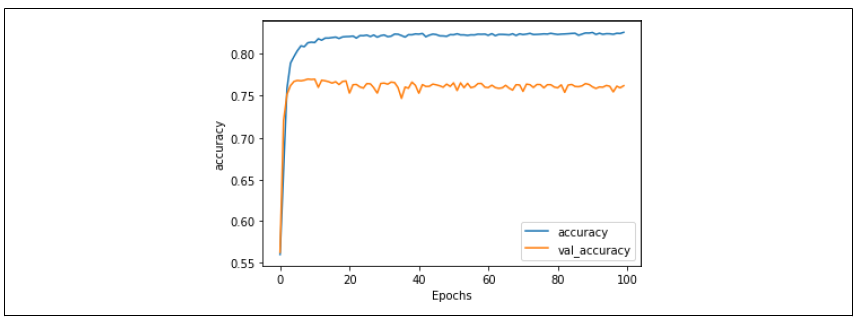
图 6-10:七维嵌入的训练与验证准确率对比
图 6-11 展示了训练和验证的损失曲线。虽然在大约第 20 个训练周期时损失看起来有所上升,但很快就趋于平稳了。这也是一个好信号!
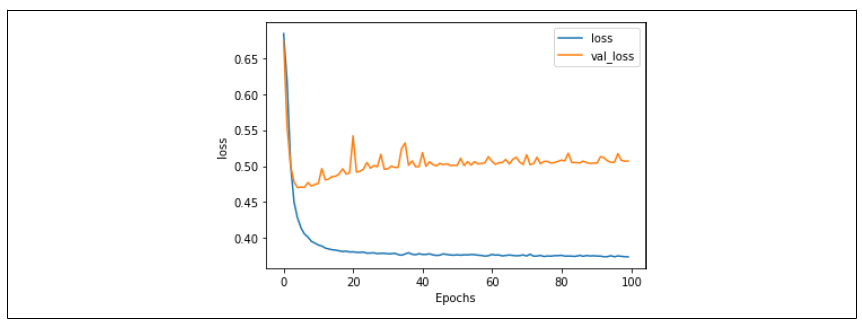
图 6-11:七维嵌入的训练与验证损失对比
现在我们已经降低了嵌入维度,可以对模型架构进行进一步的调整了。
探索模型架构
在经过前面部分对模型进行优化之后,模型架构现在是这样的:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(2000, 7),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
第一眼看过去,模型的维度设计让人感到有点问题——GlobalAveragePooling1D 层现在只输出 7 个维度的数据,但这些数据被直接传入一个有 24 个神经元的全连接层,这显得有点过头了。那么,如果把这个全连接层的神经元数量减少到 8 个,并训练 100 个周期,会发生什么呢?
你可以在图 6-12 中看到训练和验证的准确率对比。和使用 24 个神经元的图 6-7 比较,整体结果差不多,但波动明显减少了(线条看起来不那么“锯齿状”了)。而且,训练速度也有所提升。
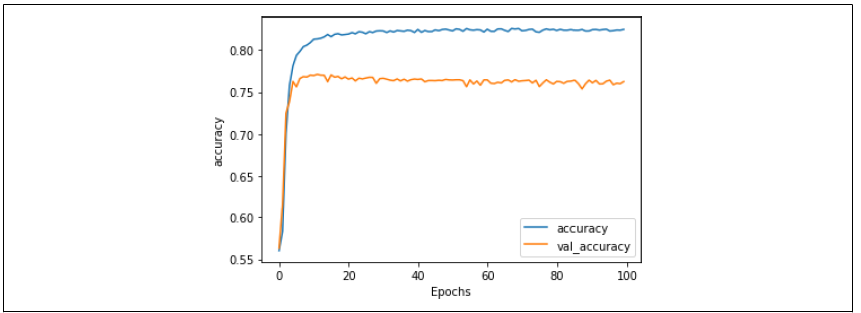
图 6-12:减少全连接层神经元后的准确率结果
同样,图 6-13 中的损失曲线显示了类似的结果,不过“锯齿感”也有所减弱。
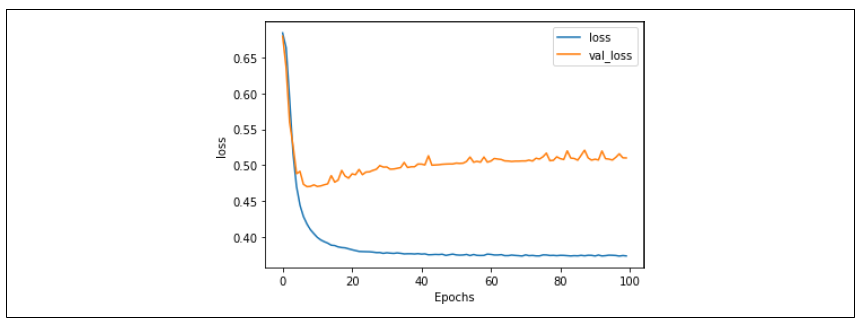
图 6-13:减少全连接层神经元后的损失结果
总结:本篇所讲述的知识,对于人工智能领域的工程师或专家来说,会显得很基础;但对于普通大众而言,如果能够理解并亲手实践,完成文中知识所描述的目标,那您已经具备了人工智能领域专家的能力。再次强调,人工智能并不神秘,它本质上是利用广泛的知识教会机器模拟人类的思维方式和行为模式,用机器来为人类造福,同时利用机器所具备的人类不具备的优势,提升人类的生产力与文明。接下来,我们将为大家介绍一种常用的解决模型“读死书”问题的方法——“随机失活”(Dropout)。