前一篇:《人工智能模型训练技术:随机失活,丢弃法,Dropout》
序言:让人工智能模型变得更“聪明”的方法之一,就是减少“过拟合”(读死书)的问题,从而提升模型的“泛化能力”,也就是它面对新问题时的适应能力。在前面,我们讲解了最常用的“随机丢弃”法,本节将带大家了解另一种重要的方法——“正则化”。
那么,正则化主要做什么呢?用现实生活中的案例来比喻,正则化的作用就像学校里的老师,目的是引导学生往正确的方向走,而不是死记硬背课本,或者因为某些考试题目熟悉而侥幸得高分。老师会通过约束学生的行为,比如规范学习方法、减少偏科等,让学生学到的是通用的规律和解决问题的能力,而不是偏离正常轨道或者学到无用的信息。同样,正则化在人工智能中通过约束模型的权重等机制,帮助模型避免过拟合,提升它面对新数据的表现能力。
使用正则化
正则化是一种通过减少权重的极端化(polarization)来防止过拟合的技术。如果某些神经元的权重过大,正则化会对它们进行“惩罚”。总体来说,正则化有两种主要类型:L1 和 L2。
• L1 正则化 通常被称为套索正则化(lasso,最小绝对收缩和选择算子)。它的作用是帮助我们忽略权重为零或接近零的值,当计算层的结果时,这些权重会被有效地“抛弃”。
• L2 正则化 通常被称为岭回归(ridge regression),因为它通过计算权重的平方,将非零值和零值(或接近零的值)之间的差异放大,从而产生一种“山脊效应”。
这两种方法还可以结合起来,形成一种叫做弹性正则化(elastic regularization)的技术。
对于像我们当前这种自然语言处理问题,L2 正则化 是最常用的。你可以通过 kernel_regularizer 属性将它添加到 Dense 层中,这个属性接受一个浮点值作为正则化因子。这是另一个可以用来优化模型的超参数,值得尝试!
以下是一个示例代码:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(8, activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
在像这样的简单模型中,添加正则化的影响并不会特别大,但它确实让训练损失和验证损失的曲线变得更加平滑了一些。在这种场景下可能有点“用力过猛”,但和 Dropout 一样,了解如何使用正则化来防止模型过度专注(overspecialized)是一个非常重要的技能。
其他优化的考虑
虽然我们已经通过之前的修改得到了一个过拟合更少、性能更好的模型,但还有其他超参数可以进行实验。例如,我们之前将最大句子长度设置为 100,但这个值纯粹是随意选的,可能并不是最佳值。一个好主意是探索语料库,看看有没有更合适的句子长度。
以下是一个代码片段,用来检查句子的长度并将它们从短到长排序后绘制成图表:
xs = []
ys = []
current_item = 1
for item in sentences:
xs.append(current_item)
current_item += 1
ys.append(len(item))
newys = sorted(ys)
import matplotlib.pyplot as plt
plt.plot(xs, newys)
plt.show()
图 6-16 展示了这个代码的结果。
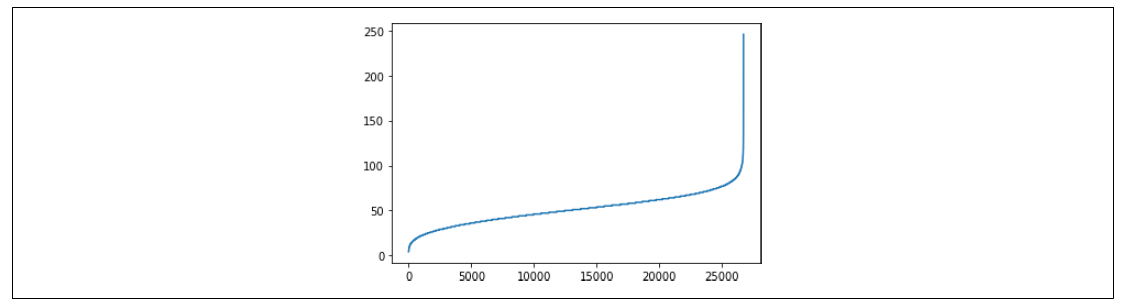
图 6-16:探索句子长度
在整个 26,000 多条语料中,长度达到 100 个单词或以上的句子不到 200 条。所以,把句子长度的最大值设为 100,就会引入很多不必要的填充(padding),这会影响模型的性能。如果把最大长度减少到 85,仍然可以覆盖 26,000 条语料中的 99% 以上,几乎不需要任何填充。
总结:正则化也是为了让模型变聪明的一种方法,即增强模型的泛化能力。它的角色就像我们从小到大的老师,负责引导和规范我们的学习框架和方向。下一节我们将把通过各种方法优化后训练好的模型,用于实际应用——分类新闻中的句子并进行预测。