视觉语言模型(Vision Language Model,VLM)正在改变计算机对视觉和文本信息的理解与交互方式。本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。
总体架构
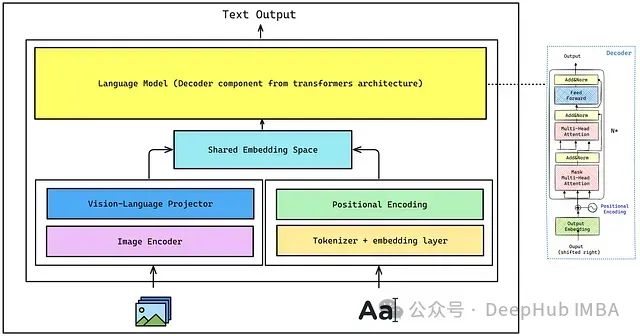
VLM 的总体架构包括:
- 图像编码器(Image Encoder):用于从图像中提取视觉特征。本文将从 CLIP 中使用的原始视觉 Transformer。
- 视觉-语言投影器(Vision-Language Projector):由于图像嵌入的形状与解码器使用的文本嵌入不同,所以需要对图像编码器提取的图像特征进行投影,匹配文本嵌入空间,使图像特征成为解码器的视觉标记(visual tokens)。这可以通过单层或多层感知机(MLP)实现,本文将使用 MLP。
- 分词器和嵌入层(Tokenizer + Embedding Layer):分词器将输入文本转换为一系列标记 ID,这些标记经过嵌入层,每个标记 ID 被映射为一个密集向量。
- 位置编码(Positional Encoding):帮助模型理解标记之间的序列关系,对于理解上下文至关重要。
- 共享嵌入空间(Shared Embedding Space):将文本嵌入与来自位置编码的嵌入进行拼接(concatenate),然后传递给解码器。
- 解码器(Decoder-only Language Model):负责最终的文本生成。
https://avoid.overfit.cn/post/fa8eb707ce954dffa25ce801da251a51