缓冲区的理解
先来看这段代码
#include <stdio.h>
#include <unistd.h>
#include <string.h>int main()
{//C接口printf("hello printf\n");fprintf(stdout, "hello fprintf\n");fputs("hello fputs\n", stdout);//系统接口const char* msg = "hello write\n";write(1, msg, strlen(msg));fork();//子进程什么都不做,只是创建出来然后关闭return 0;
}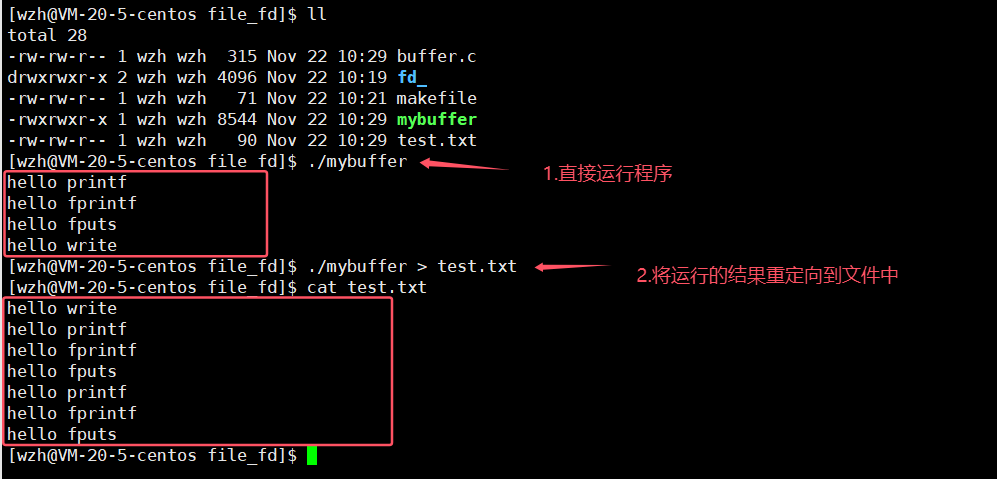
同一个程序,为什么直接运行,和将运行结果重定向到文件中然后再输出的结果为什么不一样呢?让我们再把fork()这行注释后再看看。
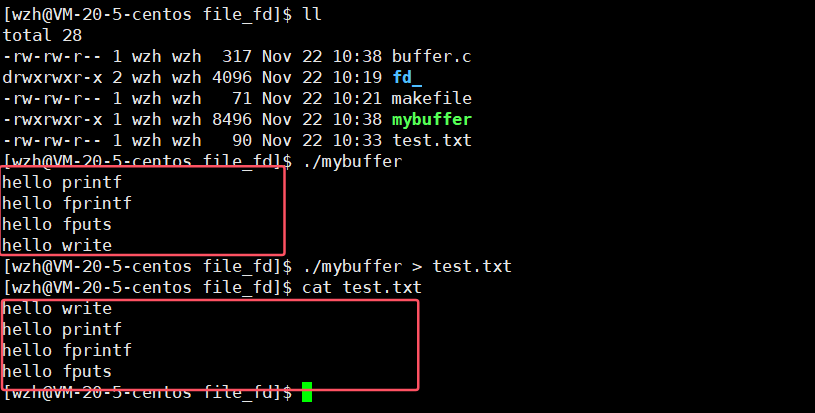
此时,运行结果又相同了。这又是为什么呢?
缓冲区
我们所谈论的都是用户级缓冲区。
-
什么是缓冲区
缓冲区本质就是一段内存,为了节省进程进行数据IO的时间。比如,CPU 和硬盘之间,硬盘的数据读取速度远远慢于 CPU 的处理速度。当从硬盘读取数据时,数据会先被读入缓冲区,然后 CPU 再从缓冲区获取数据进行处理,这样就可以避免 CPU 因为等待硬盘缓慢的数据读取而浪费时间。
-
缓冲区的刷新策略
如果有一块数据,那么它是一次写入到外设中效率高,还是少量多次的写入到外设效率高呢?答案肯定是第一种情况。虽然这种效率最高,但是缓冲区会结合具体的设备,定制自己的刷新策略:
- 立即刷新,也就是无缓冲。
- 行刷新,对应行缓存,通常也是显示器的刷新策略。
- 缓冲区满,对应全缓冲,通常也是磁盘文件的刷新刷新策略。
还有两种特殊的刷新策略:
- 用户强制刷新,比如使用
fflush()函数。 - 进程退出,一般都要进行缓冲区刷新。
现在我们再来解决上面的问题。我们发现只要是库函数都输出了两次,而系统调用只输出了一次,将fork()函数注释后就符合我们的预期了,那么这肯定和fork()有关。
- 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。如果没有进行重定向,stdout默认使用的是行刷新,进程在fork之前,三条C函数已经将数据进行打印输出到显示器上,此时缓冲区内部已经没有数据了。
- printf,fwrite等库函数会自带缓冲区,当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。此时数据不会立即刷新。
- 执行fork的时候,stdout属于父进程,创建子进程,由于子进程是以父进程为模板创建出来的。当子进程退出时,会修改缓冲区的数据发生写时拷贝。因此数据会有两份。
- write没有变化,说明write没有所谓的缓冲。
综上,printf,fwrite等库函数会自带缓冲区,而write系统调用没有带缓冲区。库函数在系统调用的”上层“,但是write没有缓冲区,而printf,fwrite等有,这足以说明这个缓冲区是由C标准库提供的。
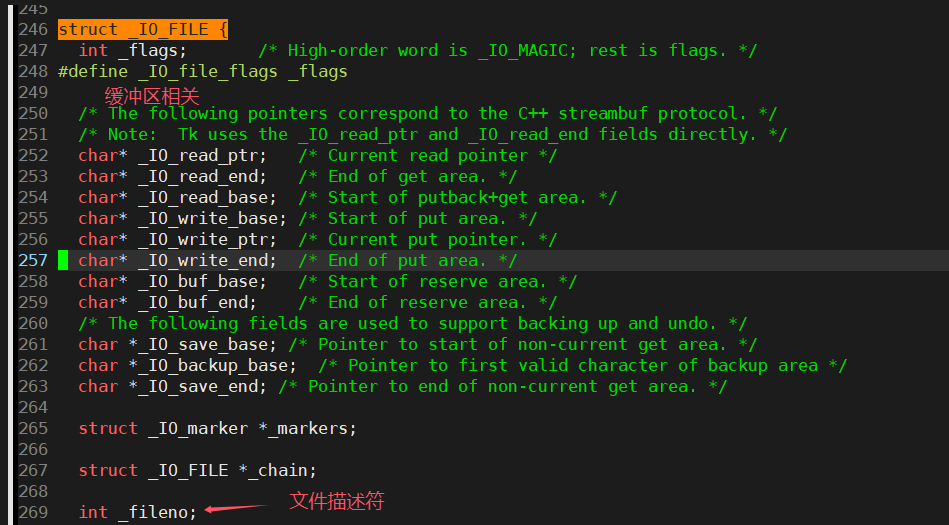
FILE
- 由于IO相关函数与系统调用接口对应,并且库函数是封装了系统调用,所以本质上,访问文件都是通过访问fd访问的。
- 所以C语言的FILE结构体中肯定封装了fd。
- 由于缓冲区是由C标准库提供,所以FILE结构体中肯定由缓冲区相关的内容。
FILE结构体