1. 要点
1.1. 实现数据质量不能纸上谈兵,而获得“可靠数据”取决于数据分析和工程实践中的其他几个要素
1.2. 数据网格以及数据质量适用的地方
1.3. 数据质量在基于云的数据栈旅程中的作用
1.4. 知识图谱是更易于访问数据的关键
1.5. 分布式数据架构下的数据发现
1.6. 何时开始进行数据质量控制
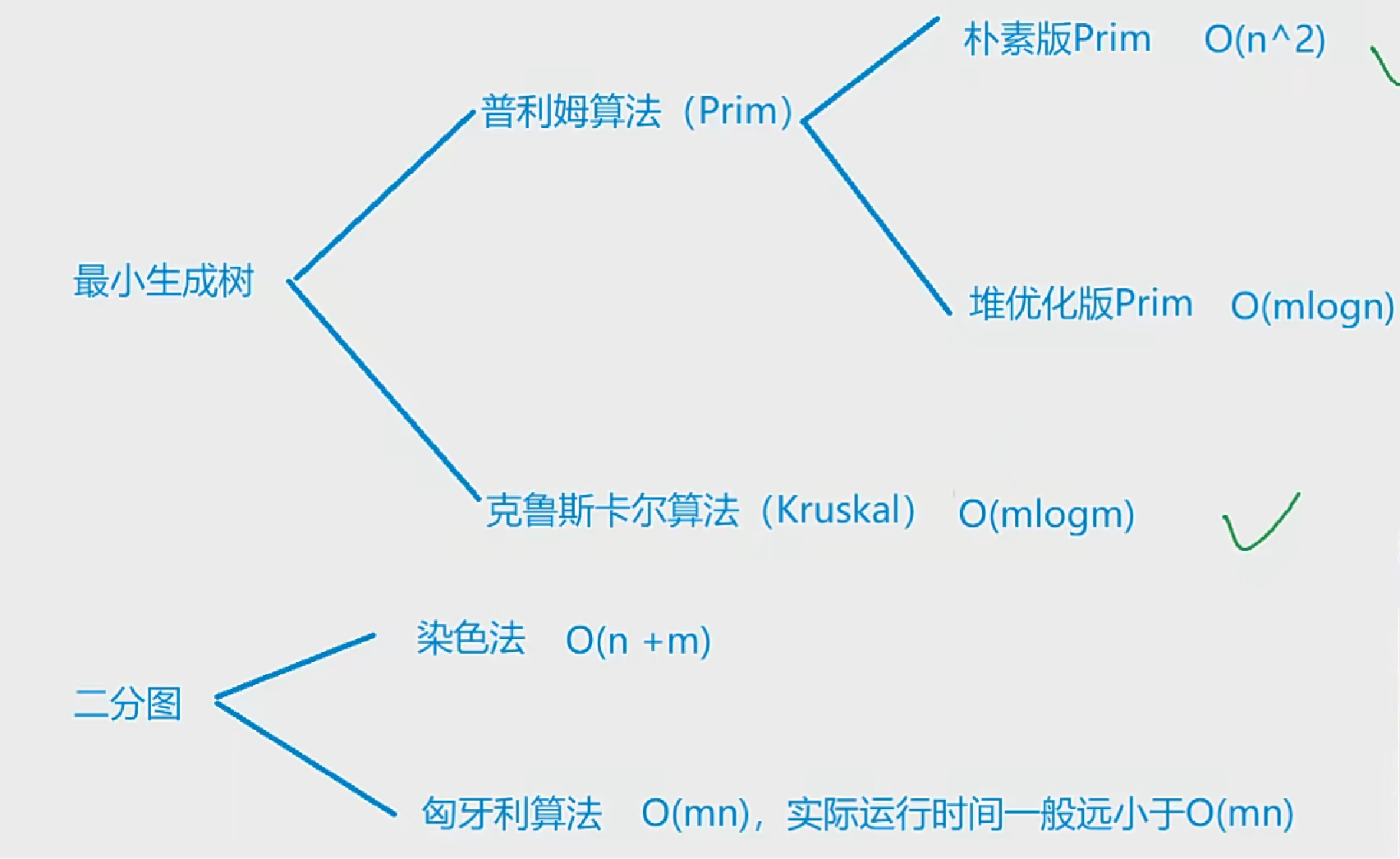
2. 为更高的数据质量构建数据网格
2.1. 数据团队希望找到一种更容易的方法来管理组织日益增长的需求,不论是处理永无止境的即席查询流,还是通过中央ETL管道处理不同的数据源
- 2.1.1. 解决孤立的基础设施局限性,许多数据团队正在向更为分布式的“联邦治理”模型转移,开始采用数据网格架构
2.2. 数据网格在很多方面都是微服务的数据平台版本
-
2.2.1. 数据网格是一种数据平台的架构类型,通过采用面向领域的自助式设计来利用企业中无处不在的数据
-
2.2.2. 数据网格架构的基础是通用互操作性层,反映了与领域无关的标准,以及可观测性和治理
-
2.2.3. 数据网格让团队能够跨业务领域来操作数据,但同时能够跨这些领域进行标准化治理,以保证数据质量
2.3. 数据网格概念利用了Eric Evans的领域驱动设计理论,这是一种灵活、可扩展的软件开发范例,可以将代码的结构和语言与其相应的业务领域进行匹配
-
2.3.1. 与在一个中央数据湖中处理数据的使用、存储、转换和输出的传统整体数据基础设施不同
-
2.3.2. 数据网格支持分布式、特定领域的数据用户并将“数据视为产品”,而每个领域都各自处理自己的数据管道
-
2.3.3. 连接这些领域及相关数据资产之间的纽带是应用相同语法和数据标准的通用互操作层
2.4. 三个独立的组件组成
-
2.4.1. 数据源
-
2.4.2. 数据基础设施
-
2.4.3. 由职能所有者管理的面向领域的数据管道
2.5. 面向领域的数据所有者和数据管道
-
2.5.1. 数据网格联合了负责将数据作为产品提供的领域数据所有者之间的数据所有权,同时也促进了跨不同位置的分布式数据之间的通信
-
2.5.2. 数据基础设施负责为每个领域提供用于处理数据的解决方案,但领域的任务是管理数据的摄取、清洗与聚合,以生成可供商业智能应用程序所使用的数据资产
-
2.5.2.1. 每个领域都负责拥有自己的ETL管道,但所有领域都应具有存储、编录和维护访问控制原始数据的能力
-
2.5.2.2. 一旦数据被提供给一个指定的领域并由其转换,领域所有者就可以利用这些数据来满足其分析或运营需求
-
2.6. 自助式服务功能
-
2.6.1. 提供自助式数据平台,允许用户将技术复杂性抽象化并专注于他们各自的数据用例
-
2.6.2. 在每个领域中维护数据管道和基础设施所需的工作和技能上的重复
-
2.6.3. 数据网格将与领域无关的数据基础设施功能收集并提取到一个中央平台中,由该平台来处理数据管道引擎、存储和数据流基础设施
-
2.6.4. 每个领域负责利用这些组件来运行自定义的ETL管道,给它们提供必要的支持来轻松地服务其数据并真正掌控流程所需的自主权
2.7. 互操作性与通信标准化
-
2.7.1. 每个领域的底层都是一组通用的数据标准,这些标准有助于在必要时促进领域之间的协作
-
2.7.2. 某些数据都将对多个领域有价值
-
2.7.3. 为了实现跨领域间的协作,数据网格必须在格式、治理、可发现性和元数据字段以及其他数据特性方面实现标准化
-
2.7.4. 每个数据领域都必须定义并同意它们将“保证”为消费者提供的SLA和质量措施
3. 为什么要实施数据网格
3.1. 具有实时数据可用性和流处理功能的数据湖,其目标是从集中式数据平台摄取、丰富、转换并提供数据
3.2. 不足
-
3.2.1. 中央ETL管道让团队减少了对不断增长的数据量的控制
-
3.2.2. 随着每个公司都成为数据公司,不同的数据用例需要不同类型的转换,这给中央平台带来了沉重的负担
3.3. 面向领域的数据架构(如数据网格)为团队提供了两全其美的方法
-
3.3.1. 集中式数据库(或分布式数据湖)
-
3.3.2. 其中的领域(或业务范围)负责处理自己的管道
3.4. 数据网格对于拥有300名以上员工的使用云平台的公司来说将变得越来越普遍
3.5. 数据架构可以通过分解成更小的、面向领域的组件来最容易地进行扩展
3.6. 数据网格为数据所有者提供了更大的自主权和灵活性,促进了更大的数据实验和创新,同时减轻了数据团队通过单一管道来满足每个数据消费者需求的负担,从而为数据湖的缺点提供了解决方案
3.7. 数据网格的自助服务基础设施作为一个平台,为数据团队提供了一种通用的、与领域无关的、通常是自动化的方法,来实现数据标准化、数据产品沿袭、数据产品监控、警报、日志记录和数据产品质量指标(也就是数据的收集和共享)
- 3.7.1. 传统数据架构通常因摄取者和消费者之间缺乏数据标准化而受到阻碍
3.8. 选不选网格
-
3.8.1. 新架构的采用也带来了对数据网格真正本质以及如何构建数据网格的误解
-
3.8.2. 处理大量数据源和需要进行数据实验(也就是快速转换数据)的团队最好考虑利用数据网格
3.9. 计算你的数据网格分数
-
3.9.1. 数据源的数量
-
3.9.2. 数据团队的规模
-
3.9.3. 数据领域的数量
-
3.9.4. 数据工程的瓶颈
-
3.9.5. 数据治理
-
3.9.6. 分数越高,则公司的数据基础设施要求就越复杂和苛刻,而公司就越有可能从数据网格中受益
4. 数据质量在数据网格中的作用
4.1. 可以从单一解决方案构建数据网格吗
-
4.1.1. 数据网格不是一个技术解决方案,甚至也不是技术的子集,而是我们如何管理和操作数据的组织范式,由多种不同的技术组成,无论是开源技术还是软件即服务
-
4.1.2. 你无法仅使用数据库来构建微服务架构,而且你也不会只使用数据仓库或商业智能工具来构建数据网格
-
4.1.3. 数据网格四项基本元素
-
4.1.3.1. 将数据的所有权从一个集中的团队下放给最适合控制它的人
-
4.1.3.2. 赋予这些团队长期的责任感,并让他们具备将数据视为产品的思维
-
4.1.3.3. 为团队提供自助式数据基础设施
-
4.1.3.4. 解决新的联合数据治理模型可能出现的新问题
-
4.1.3.5. 确保你的数据网格从一开始就走上正确的道路
-
4.2. 数据网格是数据虚拟化的另一种表达吗
-
4.2.1. 允许应用程序跨多个数据孤岛来检索和操作数据
-
4.2.2. 预测分析和对历史趋势进行建模需要的都是截然不同的数据视图
-
4.2.3. 虚拟化位于OLTP系统和微服务或运营型数据库之上,并按原样公开该数据,或只是进行一些小的转换
4.3. 每个数据产品团队是否管理自己独立的数据存储
-
4.3.1. 数据存储通常由一个中央数据工程或数据基础设施团队来维护,该团队负责确保数据网格在每个领域中都能正常运行
-
4.3.2. 不是管理数据基础设施的人,而这些基础设施才能让数据分析、数据科学和机器学习成为可能
4.4. 自助式数据平台与分散式数据网格是一回事吗
-
4.4.1. 数据平台经常被优化用于与数据网格无关的目的
-
4.4.2. 支持数据网格所构建的数据平台若要被优化,应当赋予业务领域团队自主权,并赋予通才技术人员创建数据产品的能力
-
4.4.3. 数据平台应该让团队能够拥有端到端地管理数据的能力,并直接服务于数据消费者,即数据分析师、数据科学家和其他终端用户
4.5. 数据网格适用于所有的数据团队吗
-
4.5.1. 数据网格的早期采用者往往以工程为重点,并且愿意投资“构建和购买技术,因为并不是所有元素都可以买到的”
-
4.5.2. 如果你的利益相关方在寻找和使用正确的数据方面遇到问题,并且创新周期正在放缓,那么你可能是考虑采用数据网格的恰当人选
4.6. 团队中的某个人会“拥有”数据网格吗
-
4.6.1. 整个组织的文化支持
-
4.6.2. 当组织的首席数据官或首席数据分析官直接向CEO汇报时,该组织在大规模采用数据网格时通常会更有效
-
4.6.3. 当你尝试在组织中采用数据网格时,你的团队需要获得1~3个与该愿景相一致的业务领域的支持,作为推动设计和实施数据网格向前发展的倡导者
4.7. 数据网格是否会引起数据工程师和数据分析师之间的摩擦
-
4.7.1. 由于数据网格要求下放数据所有权,因此采用这种分布式的、面向领域的模型通常会在此前曾存在摩擦的领域带来良好的协调
-
4.7.2. 数据网格的数据治理通用标准可以确保各方在围绕数据质量、数据发现、数据产品模式以及数据健康和理解的其他关键要素方面能够达成一致
-
4.7.3. 自助式服务功能
-
4.7.3.1. 静态和动态数据加密
-
4.7.3.2. 数据产品的版本控制
-
4.7.3.3. 数据产品模式
-
4.7.3.4. 数据产品发现、目录注册和发布
-
4.7.3.5. 数据治理和标准化
-
4.7.3.6. 数据生产沿袭
-
4.7.3.7. 数据产品的监控、警报和日志记录
-
4.7.3.8. 数据产品的质量指标
-
4.8. 很多公司应用数据网格概念的时间都比他们意识到的要长
- 4.8.1. 他们只是没有找到合适的词来形容它
4.9. 建立一家数据驱动型公司是一场马拉松,而不是一场短跑
- 4.9.1. 随着越来越多的组织采用数据网格和分布式架构,在创新、效率和可扩展性方面带来的机会从未如此巨大