【人人都能学得会的NLP - 文本分类篇 02】使用DL方法做文本分类任务
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
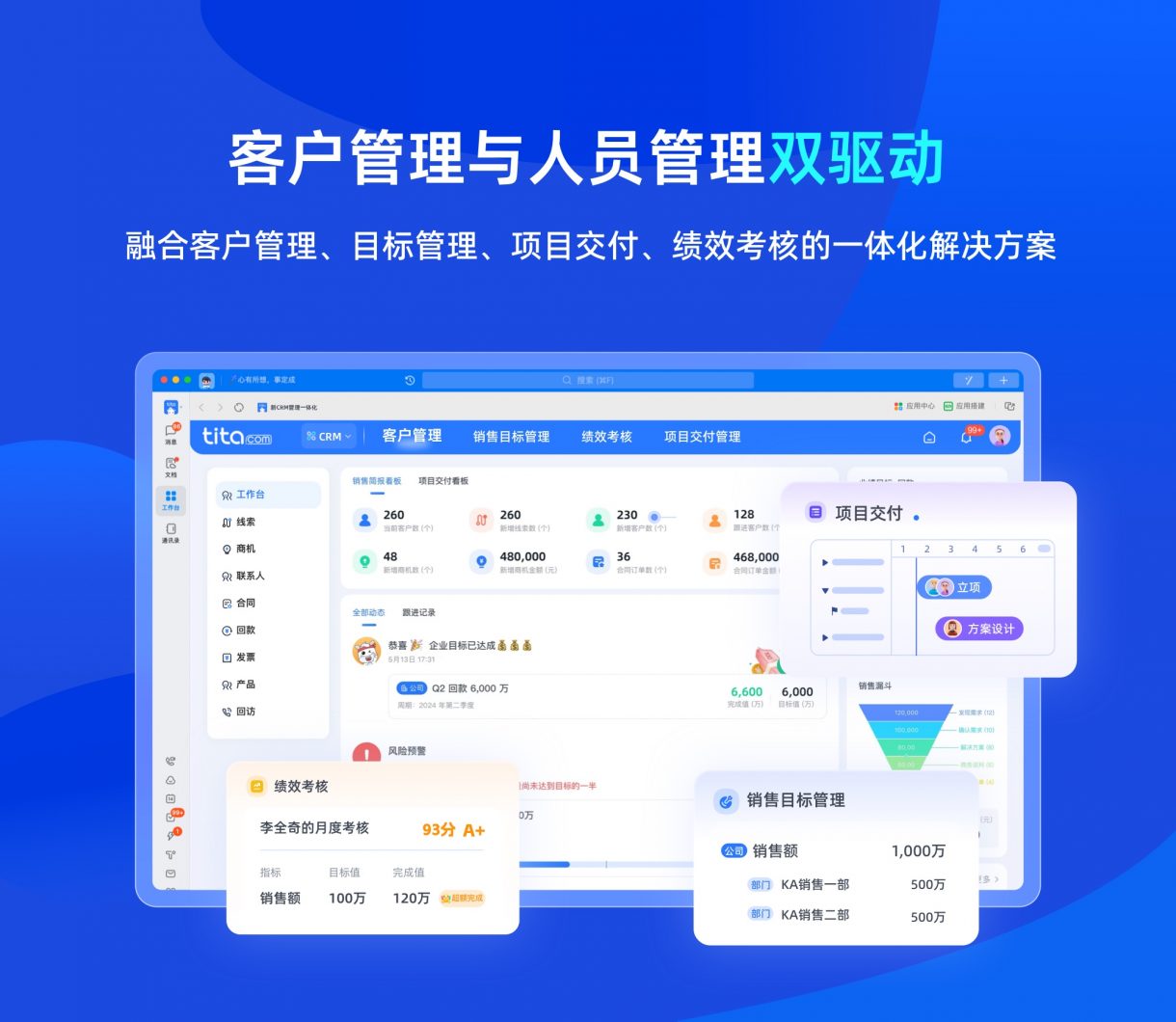
1、文本分类介绍
NLP中, 文本分类是一项基础且广泛应用的任务, 它将文本依据规则和标准划分到为特定的类别空间,并且它能够应用到多种应用场景:
- 垃圾邮件识别:判断一封邮件“是”“否”为垃圾邮件
- 情感分析: 判断一篇文章情感极性为“正面”“负面”“中性”
- 聊天意图:判断聊天文本中用户的意图为“发货时间”、“运费价格”等
……
以新闻文本分类为例,我们来了解文本分类任务的类型:
1、“今天大盘涨了3%,地产、传媒板块领涨”
2、“NBA湖人队赢下了与掘金队的比赛”
上述分别属于财经和体育类新闻。
3、“汪峰今天发布了新歌,娱乐圈又将有大事发生”
以3为例的新闻既可以归为音乐类新闻,又可以归为娱乐类新闻,与1和2有一定区别。
定义:
由上述例子,我们可以得到不同的分类任务类型:多分类任务和多标签分类任务。
- 多分类任务中一条数据只有一个标签,但是标签有多种类别,就比如1、2的新闻属于具体的单一新闻类别。
- 多标签分类任务指的是一条数据可能有一个或者多个标签,就比如3的新闻具有多个新闻类别。
任务实现过程:
完成的分类任务一般需要经历两个阶段,分别是训练阶段和预测阶段。
- 训练阶段的目标是基于训练集数据(带label)。训练文本分类模型
- 预测阶段的目标是使用上一阶段训练好的模型,对于新数据(无label),预测其类别。
技术演化:
分类模型随着技术的进步也经历从规则匹配—>机器学习—>传统深度学习—>前沿深度学习以下四个阶段的演化:
- 规则匹配:基于关键词匹配等方法
- 机器学习:基于LR、SVM、集成学习等方法
- 传统深度学习:基于FastText、TextCNN、BiLSTM等神经网络方法
- 前沿深度学习:基于Transformer、BERT的pretrain-finetune和prompt范式。
效果评估:
在模型完成后,需要根据预测结果对模型的效果进行整体评估
对于分类任务,直观指标可以由准确率(accuracy)进行表示:
- 准确率:分类正确的样本数占样本总数的比例,通过记录正确的数量占比即可。
但是上述指标评估存在一定局限,以情感分析任务为例,如果我们想评测模型(1)返回的正面情绪结果中的正确数量,或者在(2)所有真实的正面情绪文本中,模型识别出来的数量,只依靠准确率无法实现任务。(3)且在样本类别数量极度不平衡下,准确率的意义不大,例如,一批数据中,正样本只有几个,即使没能正确预测出来,准确率依旧很高。
基于上述情况,需要考虑新的评测指标,如果我们用的是个二分类的模型,那么把预测情况与实际情况的所有结果两两混合,结果就会出现以下4种情况,就组成了如下所示的混淆矩阵。

精准率(Precision)又叫查准率,它是针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下,它能够解决上述局限中(1)的情况:
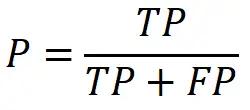
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下,它能够解决上述局限中(2)的情况:

一般来讲,准确率和召回率会互相矛盾,假设你想实现较高的召回率,那尽可能召回的样本越多越好,这样子的精准率就会下降。通常,如果想要找到精准率与召回率之间的一个平衡点,我们就需要一个新的指标:F1分数。F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡,其计算公式如下,一般任务用F1进行衡量较为科学。
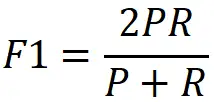
举例如下:
模型预测结果:0,1,0,0,1
实际样本结果:1,1,0,1,0
各项评测指标如下所示:
准确率(accuracy):2/5 = 0.4
精准率(precision):1/2 = 0.5
召回率(recall):1/3 = 0.333
F1:2*p*r/(p+r) = 0.4
当回顾文本分类的全流程后,我们接下来引入较为主流的模型进行文本分类任务的处理。
2、深度学习模型
机器学习模型依赖特征工程的构建,与此同时,深度学习模型开始显示出其突出优势:
- 首先,深度学习模型不依赖于传统的特征工程,它可以通过其网络结构的变化来拟合任意复杂的函数。
- 其次,深度学习模型能够实现传统离散型编码到稠密词向量表示的转换,用向量空间实现语义空间的映射,为自然语言天然的离散特性提供良好的解决方案。
基于深度学习模型的良好效果,也有越来越多的研究尝试使用这种方法。
传统深度学习模型一般指神经网络引进之后,预训练模型出现之前NLP领域的研究方法,这类方法不用手动设置特征和规则,节省了大量的人力资源,但仍然需要人工设计合适的神经网络架构来对数据集进行训练。常见的方法比如CNN(衍生模型有TextCNN等)、RNN(衍生模型有LSTM、BiLSTM等)。
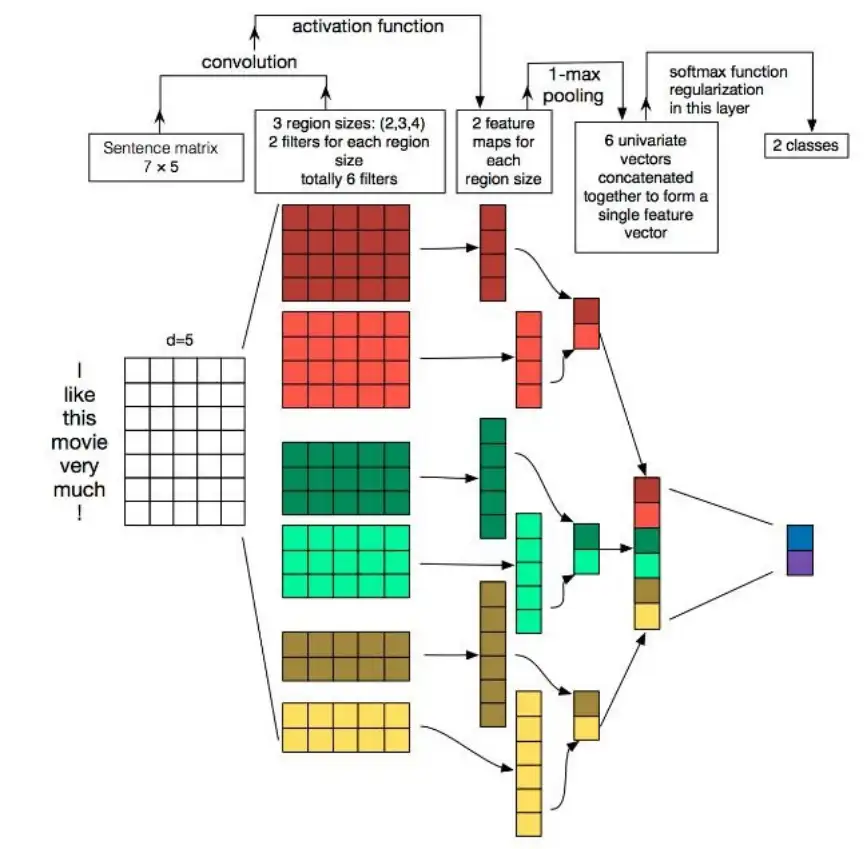
CNN模型以TextCNN为例分析:
- 首先在embedding层输入原始文本
- 卷积层拥有多种种类的卷积核,关注文本不同维度的特征
- 再通过池化层对于不同特征进行组合
- 最终通过全连接层实现多分类任务
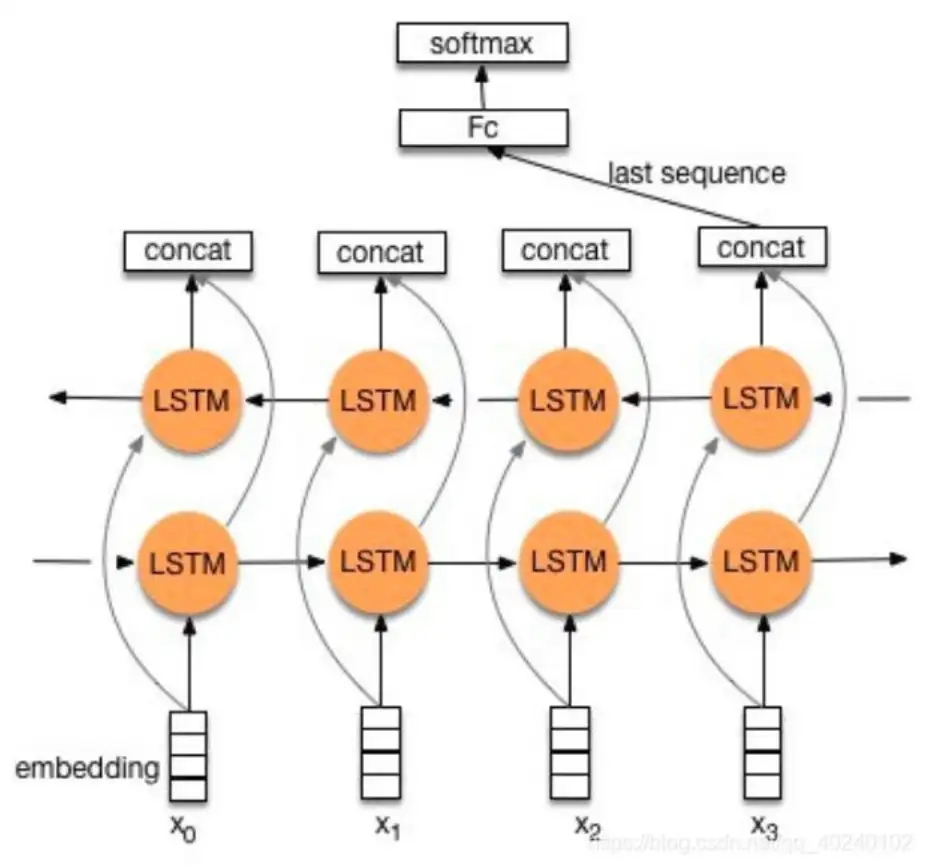
RNN模型以 BilSTM为例分析:
- 原始输入序列x,经过前后两个LSTM层后,语义表征被拼接(concat)作为时间步的语义表示。
- 接着取BilSTM最后一个时间步的输出,接入全连接层,做分类任务
- 通过对于全连接层的n个数值使用softmax函数,返回每个标签对应的概率,概率最大即为预测标签。
但传统深度学习模型在语义表示等方面仍存在局限,Transformer和BERT模型的诞生为NLP领域提供新的发力点。
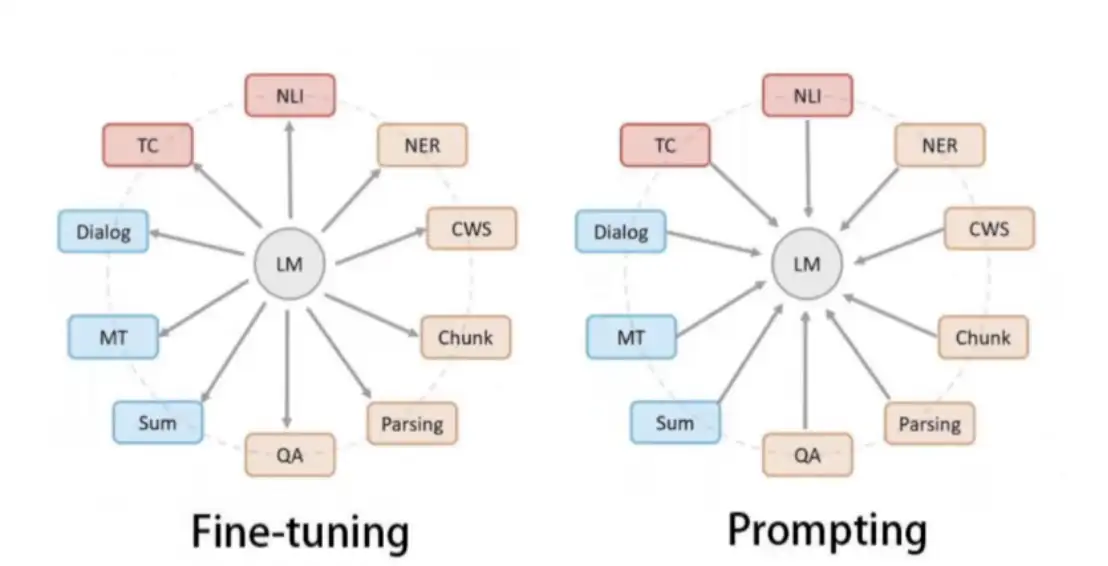
以BERT模型为核心,前沿深度学习模型围绕面向的服务对象产生了两大范式,
一类是以下游任务为核心,模型“迁就”下游任务的pretrain-finetuning范式,指的是先在大的无监督数据集上进行预训练,学习到一些通用的语法和语义特征,然后利用预训练好的模型在下游任务的特定数据集上进行fine-tuning,使模型更适应下游任务,针对于本任务则是分类任务,其特点是不需要大量的有监督下游任务数据,模型主要在大型无监督数据上训练,只需要少量下游任务数据来微调少量网络层即可。
另一类是以模型为核心,下游任务围绕模型改善的prompt范式,这种范式解决了传统pretrain-finetuning范式中pretrain和finetuning学习目标不匹配的局限,让下游任务根据模型pretrain的机制进行调整,从而激发预训练模型的潜能。
下图LM即是语言模型,该图也形象的体现了二者服务对象的显著区别。
接下来,通过一个简单的例子来对BERT模型实现文本分类任务进行介绍:
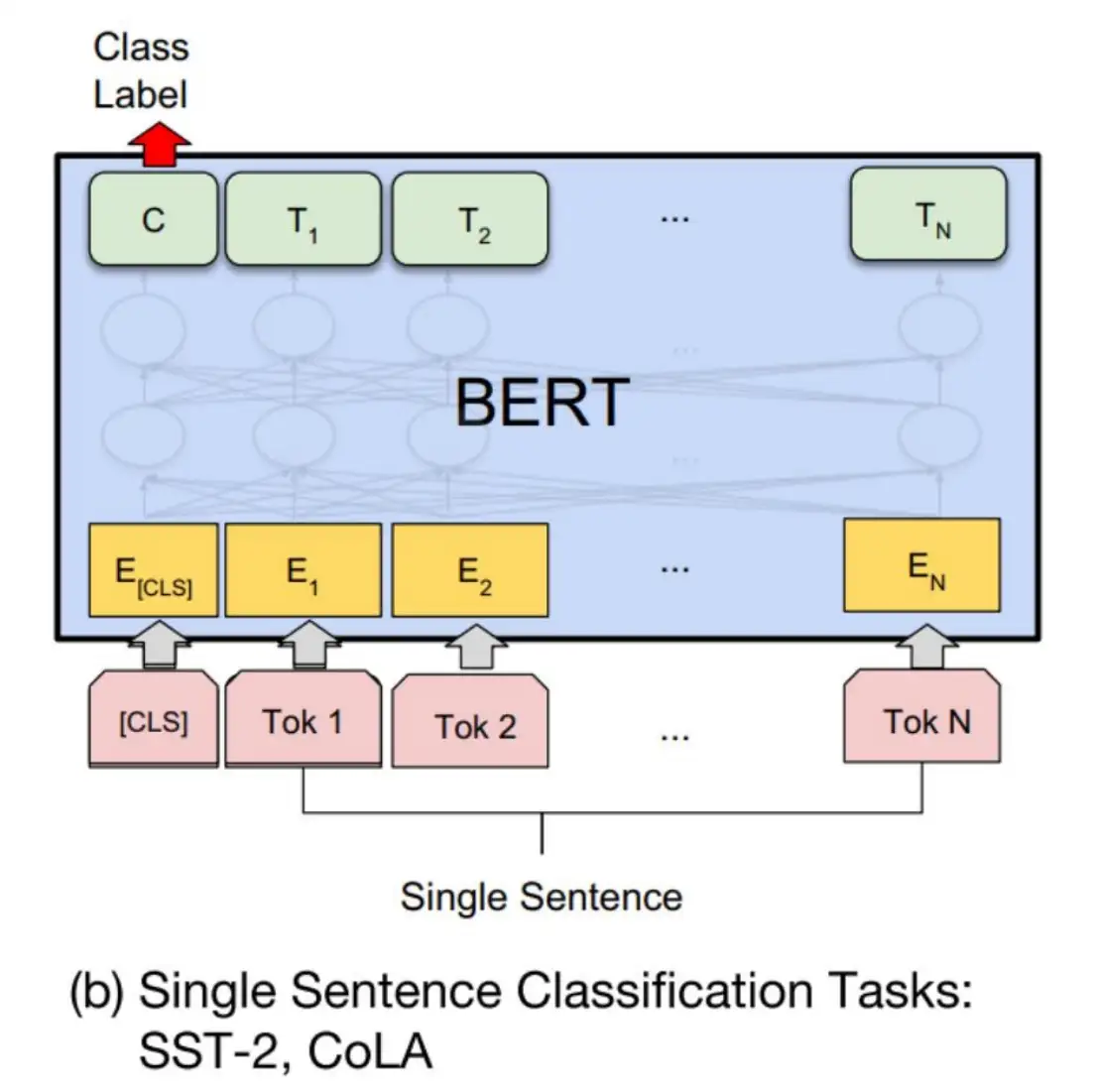
Bert模型实现文本分类任务,在一张图的体现如下所示:我们输入原始句子,然后将通过模型输出的【C】标识符当作是句子标识符,再接入全连接层进行分类任务。
如果分过程来看:模型首先经过以MLM(mask language model)机制为执行目标的pretrain阶段,这类似于我们常见的完形填空任务;之后,再在完成预训练模型的基础上执行句子标签预测,即fine-tuning阶段,过程如下所示:
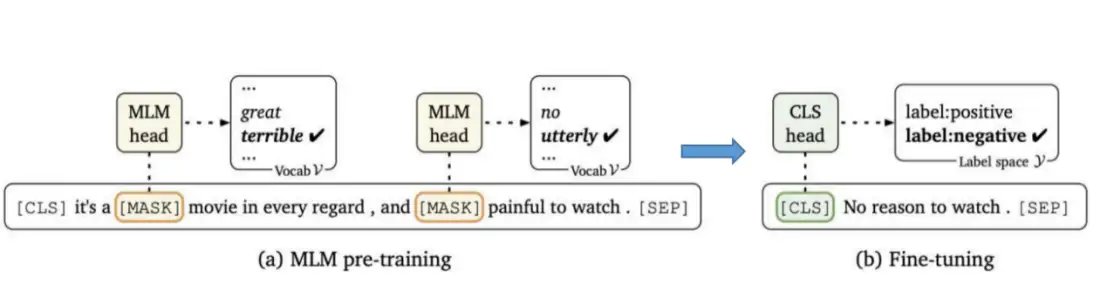
上述过程也体现了这一范式存在两阶段任务目标不一致的问题。
如果我们以电影评论的情感分类任务为例,我们来辨析pretrain-finetune范式和prompt范式的区别
首先原始句子输入是:“特效非常炫酷,我很喜欢”,其对应的情感标签为:positive。
我们能够发现,prompt范式能够通过提示模版更改自然语言另一种表达形式,从而使数据更适配模型,达到更佳的效果。

基于BiLSTM模型做文本分类
传统深度学习以BiLSTM模型中的Model类为例进行介绍:
class BiLSTMModel(nn.Module):def __init__(self, vocab_size, embed, hidden_dim, n_layers, dropout,label_size):super(BiLSTMModel, self).__init__()self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.n_layers = n_layers # LSTM的层数self.hidden_dim = hidden_dim # 隐状态的维度,即LSTM输出的隐状态的维度self.embedding_dim = embed # 将单词编码成多少维的向量self.dropout = dropout # dropout的比例self.label_size = label_size #最终输出的维度self.embedding = nn.Embedding(vocab_size, self.embedding_dim)self.lstm = nn.LSTM(input_size=self.embedding_dim,hidden_size=self.hidden_dim,num_layers=self.n_layers,bidirectional=True,dropout=self.dropout)# 初始时间步和最终时间步的隐藏状态作为全连接层输入self.fc = nn.Linear(self.hidden_dim * 2, self.label_size)def forward(self, inputs, labels=None):# 再提取词特征,输出形状为( batch,seq_len 词向量维度)#pytorch的lstm规定input维度是(seq_len,batch,embedding)首先变换input的维度inputs = inputs.transpose(0, 1)embeddings = self.embedding(inputs)# rnn.LSTM只传入输入embeddings,因此只返回最后一层的隐藏层在各时间步的隐藏状态。# outputs形状是(词数, 批量大小, 2 * 隐藏单元个数)lstm_output, (h_n,c_n) = self.lstm(embeddings) # output, (h_n,c_n) h_n为最后一个时间步,从它得到前、后向的最后一步output_fw = h_n[-2, :, :] # 正向最后一次的输出output_bw = h_n[-1, :, :] # 反向最后一次的输出lstm_output = torch.cat([output_fw, output_bw], dim=-1)logits = self.fc(lstm_output) #经过全连接层得到分类概率best_labels = torch.argmax(logits, dim=-1)# best_labels = best_labels.long()if labels is not None:loss_func = nn.CrossEntropyLoss() # 分类问题loss = loss_func(logits, labels)return best_labels, lossreturn best_labels
基于BERT模型做文本分类
前沿深度学习以BERT模型中的Model类为例进行介绍:
class BertFCModel(nn.Module):def __init__(self, bert_base_model_dir, label_size, drop_out_rate=0.5,loss_type='cross_entropy_loss', focal_loss_gamma=2, focal_loss_alpha=None):super(BertFCModel, self).__init__()self.label_size = label_sizeassert loss_type in ('cross_entropy_loss', 'focal_loss', 'label_smoothing_loss') # # 支持label_smoothing_lossif focal_loss_alpha: # 确保focal_loss_alpha合法,必须是一个label的概率分布assert isinstance(focal_loss_alpha, list) and len(focal_loss_alpha) == label_sizeself.loss_type = loss_type # 添加loss_typeself.focal_loss_gamma = focal_loss_gammaself.focal_loss_alpha = focal_loss_alphaself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 根据预训练文件名,自动检测bert的各种变体,并加载if 'albert' in bert_base_model_dir.lower():self.bert_tokenizer = BertTokenizer.from_pretrained(bert_base_model_dir)self.bert_model = AlbertModel.from_pretrained(bert_base_model_dir)elif 'electra' in bert_base_model_dir.lower():self.bert_tokenizer = ElectraTokenizer.from_pretrained(bert_base_model_dir)self.bert_model = ElectraModel.from_pretrained(bert_base_model_dir)else:self.bert_tokenizer = BertTokenizer.from_pretrained(bert_base_model_dir)self.bert_model = BertModel.from_pretrained(bert_base_model_dir)self.dropout = nn.Dropout(drop_out_rate)# 定义linear层,进行 hidden_size->hidden_size 的映射,可以使用其作为bert pooler# 原始bert pooler是一个使用tanh激活的全连接层self.linear = nn.Linear(self.bert_model.config.hidden_size, self.bert_model.config.hidden_size)# 全连接分类层self.cls_layer = nn.Linear(self.bert_model.config.hidden_size, label_size)def forward(self, input_ids, attention_mask, token_type_ids=None, position_ids=None,head_mask=None, inputs_embeds=None, labels=None):bert_out = self.bert_model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids,position_ids=position_ids, head_mask=head_mask, inputs_embeds=None, return_dict=False)if isinstance(self.bert_model, ElectraModel):# Electra使用gelu激活,自己实现gelu的bert poolerlast_hidden_state, = bert_outx = last_hidden_state[:, 0, :] # take <s> token (equiv. to [CLS])x = self.dropout(x)x = self.linear(x)x = get_activation("gelu")(x) # although BERT uses tanh here, it seems Electra authors used gelu herex = self.dropout(x)pooled_output = xelse:last_hidden_state, pooled_output = bert_outcls_outs = self.dropout(pooled_output)logits = self.cls_layer(cls_outs)best_labels = torch.argmax(logits, dim=-1)best_labels = best_labels.to(self.device)if labels is not None:# 根据不同的loss_type,选择不同的loss计算if self.loss_type == 'cross_entropy_loss':loss = CrossEntropyLoss(ignore_index=-1)(logits, labels) # label=-1被忽略elif self.loss_type == 'focal_loss':loss = FocalLoss(gamma=self.focal_loss_gamma, alpha=self.focal_loss_alpha)(logits, labels)else:loss = LabelSmoothingCrossEntropy(alpha=0.1)(logits, labels) # # 支持label_smoothing_lossreturn best_labels, lossreturn best_labels # 直接返回预测的labelsdef get_bert_tokenizer(self):return self.bert_tokenizer
PS:上面是部分核心代码
【动手学 RAG】系列文章:
- 【RAG 项目实战 01】在 LangChain 中集成 Chainlit
- 【RAG 项目实战 02】Chainlit 持久化对话历史
- 【RAG 项目实战 03】优雅的管理环境变量
- 【RAG 项目实战 04】添加多轮对话能力
- 【RAG 项目实战 05】重构:封装代码
- 【RAG 项目实战 06】使用 LangChain 结合 Chainlit 实现文档问答
- 【RAG 项目实战 07】替换 ConversationalRetrievalChain(单轮问答)
- 【RAG 项目实战 08】为 RAG 添加历史对话能力
- More...
【动手部署大模型】系列文章:
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 01 - 环境安装
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 02 - 推理加速
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 03 - 多图支持和输入格式问题
- More...
【人人都能学得会的NLP】系列文章:
- 【人人都能学得会的NLP - 文本分类篇 01】使用ML方法做文本分类任务
- 【人人都能学得会的NLP - 文本分类篇 02】使用DL方法做文本分类任务
- 【人人都能学得会的NLP - 文本分类篇 03】长文本多标签分类分类如何做?
- 【人人都能学得会的NLP - 文本分类篇 04】层次化多标签文本分类如何做?
- 【人人都能学得会的NLP - 文本分类篇 05】使用LSTM完成情感分析任务
- 【人人都能学得会的NLP - 文本分类篇 06】基于 Prompt 的小样本文本分类实践
- More...
本文由mdnice多平台发布