RNN原理
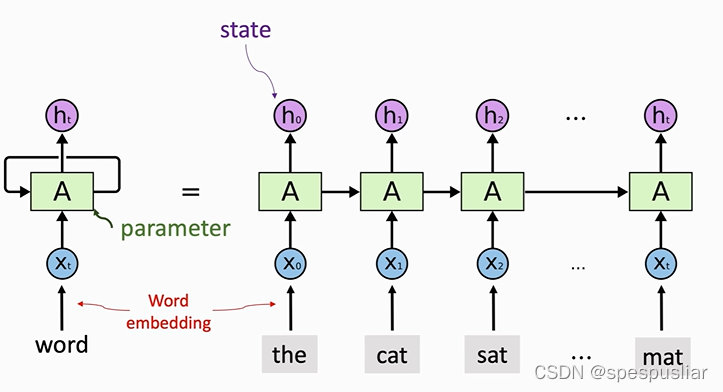
RNN的整体架构如图
RNN每次看到一个词,通过状态hi来积累看到的信息。
例如,h0包含x0的信息,h1包含x0和x1的信息,最后一个状态ht包含了整句话的信息,从而可以把它作为整个句子的特征,用来做其他任务。
注意,无论RNN的链条有多长,都只有一个参数矩阵A,A可以随机初始化,然后再通过训练来学习。
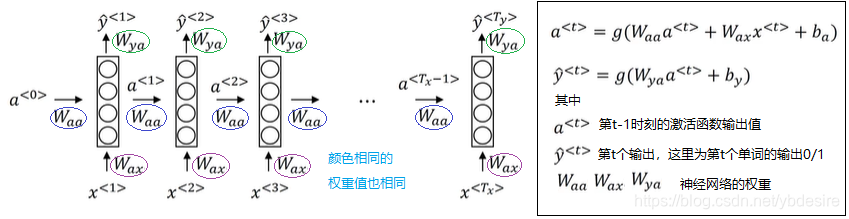
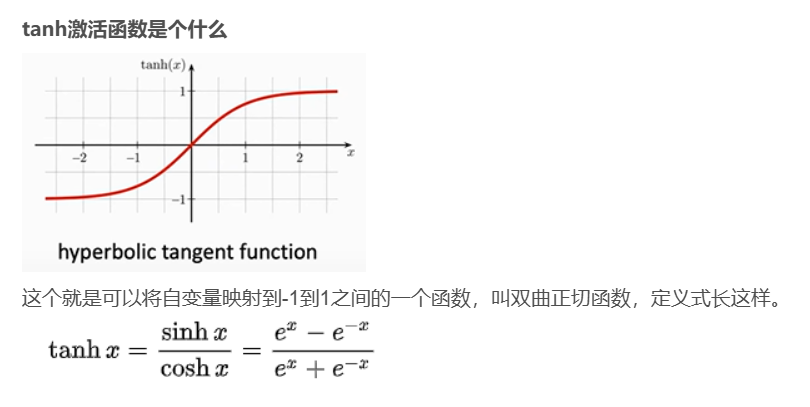
RNN的激活函数用的是tanh,非sigmoid和relu
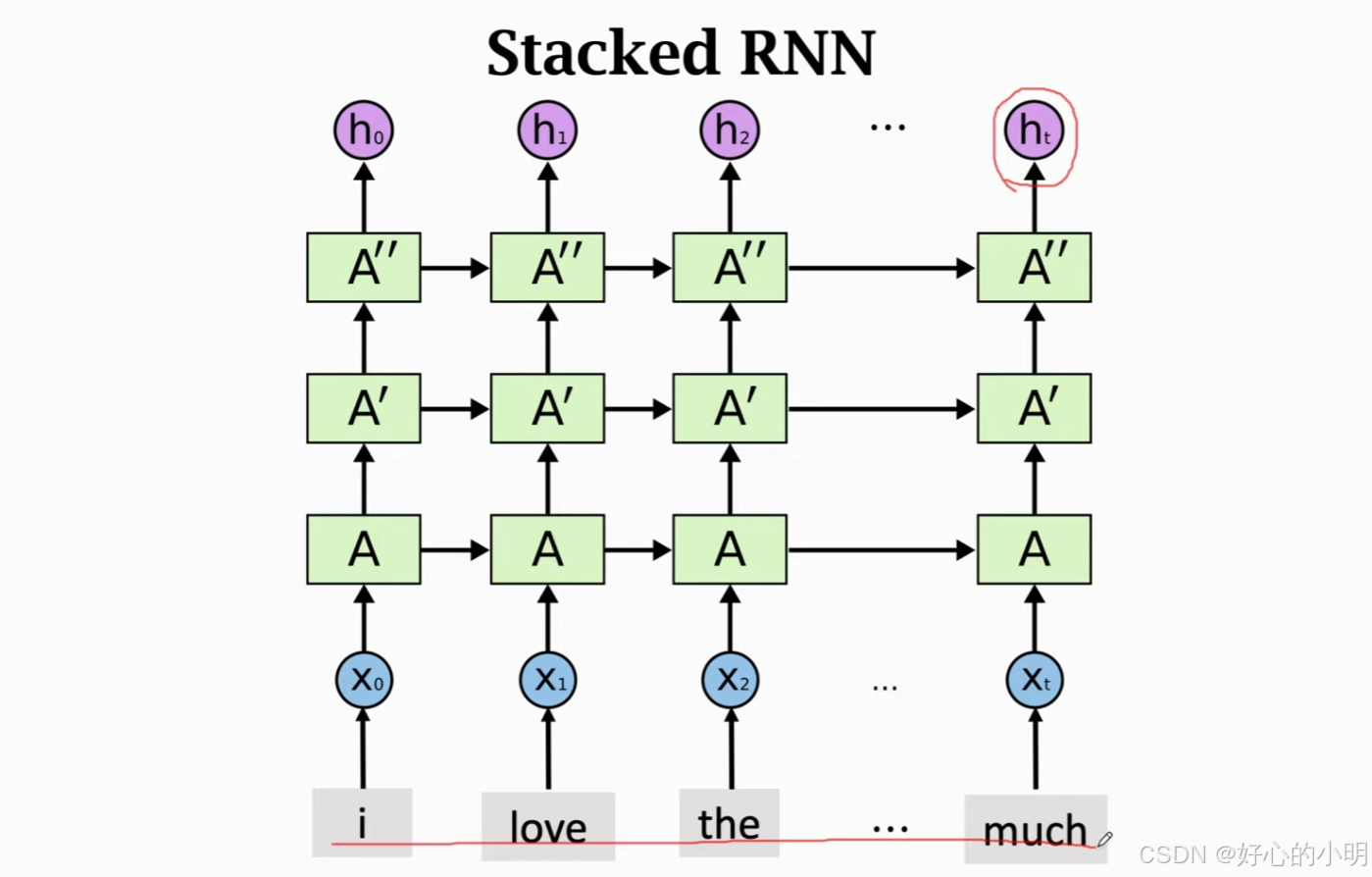
多层RNN (Stacked RNN)
多个全连接层可以堆叠,多个卷积层也可以堆叠。同理:RNN也可以堆叠形成多层RNN。
如下图所示:对于每一个时刻的输出 $ h_t$,它既会作为下一个时刻的输入,也会作为下一层RNN的输入。
nn.RNN
输入:
输入序列 x: (seq_len, batch_size, input_size)
初始化 h0: (num_layers, batch_size, hidden_size) 不提供默认全零
其中:
seq_len 是序列长度
batch_size 是批大小,
input_size 是输入的特征维度
num_layers 是RNN堆叠层数
hidden_size是隐藏状态的维度
输出
output: (batch_size, seq_len, hidden_size)
hidden: (num_layers, batch_size, hidden_size)
output 输出RNN在所有时间步上的隐藏状态输出。它包含了整个序列在每个时间步的隐藏状态。
hidden 代表隐藏层最后一个隐藏状态的输出。
hidden 只保留了最后一步的 hidden_state,但中间的 hidden_state 也有可能会参与计算,所以 pytorch 把中间每一步输出的 hidden_state 都放到 output 中(当然,只保留了 hidden_state 最后一层的输出)
如何使用 nn.RNN
data = torch.randn(batch_size, seq_len, input_size)
h0 = torch.zeros(num_layers, batch_size, hidden_size)rnn_layer = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
output, hidden = rnn_layer(data, h0)print("output.shape: [batch_size, seq_len, hidden_size] -- ", output.shape)
print("hidden.shape: [num_layers, batch_size, hidden_size] -- ", hidden.shape)
手动实现 RNN
点击查看代码
import torch
import torch.nn as nn
import randomclass myRNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, state_dict=None, batch_first=True):super(myRNN, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.batch_first = batch_firstif state_dict is not None:self.state_dict = state_dictdef forward(self, input_ori, state=None):if self.batch_first:batch_size, seq_len, input_size = input_ori.size()input_ori = input_ori.permute(1, 0, 2)else:seq_len, batch_size, input_size = input_ori.size()h0 = state if state is not None else torch.zeros(self.num_layers, batch_size, self.hidden_size)ht = h0output = torch.zeros(seq_len, batch_size, self.hidden_size)for t in range(seq_len):input_t = input_ori[t,:,:]for layer in range(self.num_layers):weight_hh = self.state_dict['weight_hh_l{}'.format(layer)] # [hidden_size, hidden_size]weight_ih = self.state_dict['weight_ih_l{}'.format(layer)] # [hidden_size, input_size]bias_hh = self.state_dict['bias_hh_l{}'.format(layer)] # [hidden_size]bias_ih = self.state_dict['bias_ih_l{}'.format(layer)] # [hidden_size]ht[layer] = torch.tanh(ht[layer]@weight_hh.T + input_t@weight_ih.T + bias_hh + bias_ih)input_t = ht[layer]output[t] = ht[-1]if self.batch_first:output = output.permute(1, 0, 2)return output, htif __name__ == '__main__':# 设置随机种子seed = 0random.seed(seed)torch.manual_seed(seed)# 定义常量num_layers = 1hidden_size = 6input_size = 5batch_size = 4seq_len = 3data = torch.randn(batch_size, seq_len, input_size)h0 = torch.zeros(num_layers, batch_size, hidden_size)# pytorch RNNrnn_layer = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)output, hidden = rnn_layer(data, h0)print("torch RNN:")print("output.shape: [batch_size, seq_len, hidden_size] -- ", output.shape)print("hidden.shape: [num_layers, batch_size, hidden_size] -- ", hidden.shape)# my RNNstate_dict = rnn_layer.state_dict()my_rnn_layer = myRNN(input_size, hidden_size, num_layers, state_dict=state_dict, batch_first=True)output2, hidden2 = my_rnn_layer(data, h0)print("my RNN:")print("output.shape: [batch_size, seq_len, hidden_size] -- ", output2.shape)print("hidden.shape: [num_layers, batch_size, hidden_size] -- ", hidden2.shape)if torch.sum(output - output2) < 1e-6 and torch.sum(hidden - hidden2) < 1e-6:print("The result is the same!")else:print("The result is different!")