ProCom: A Few-shot Targeted Community Detection Algorithm翻译
ProCom:一种少样本目标社区检测算法
Xixi Wu; Kaiyu Xiong KDD 2024 复旦大学 Yun Xiong 通信作者
社区检测方法标注数据较少,论文通过预训练提示学习的方法解决该问题。
3方法
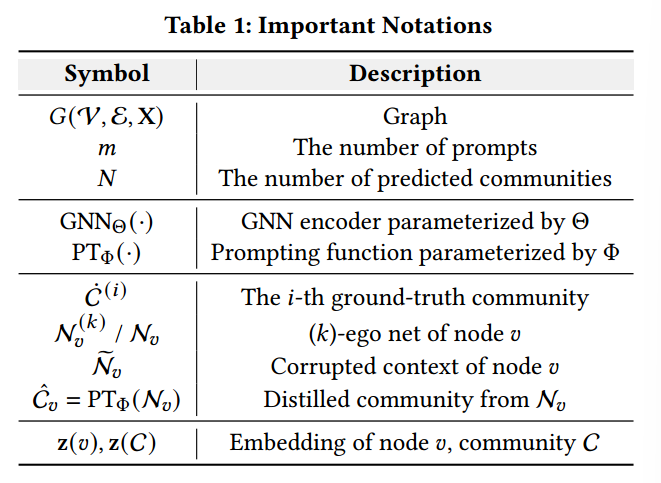
在本节中,将介绍提议的ProCom框架。从3.1节的预备开始,然后分别在3.2节和3.3节中介绍预训练和提示学习阶段。表1总结了符号。
3.1初步定义
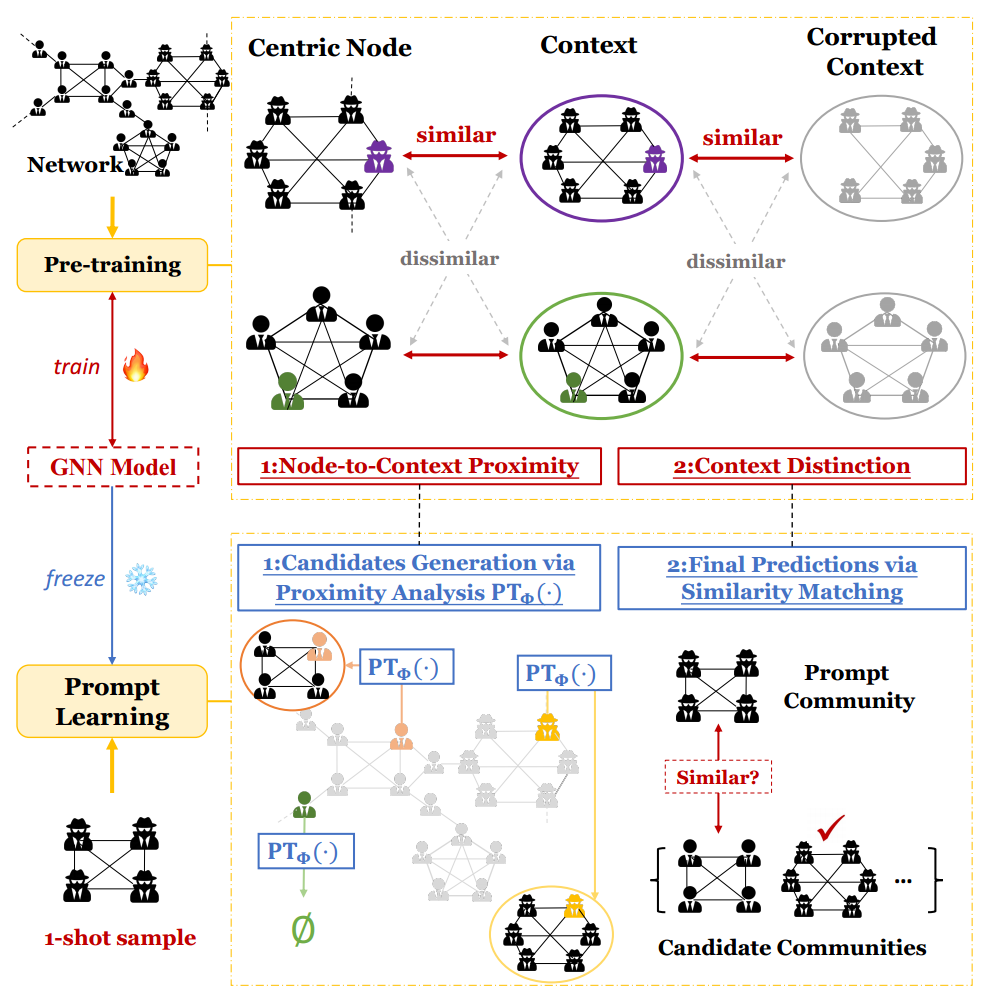
图2:PRoCom的概述。在预训练阶段,设计了一种双级预训练方法来指导模型理解网络中的潜在社区。在随后的提示学习阶段,借助少量样本,将目标社区检测任务重新定义为预文本,以参数高效的方式促进预测。
首先给出目标社区检测任务的定义,然后介绍PRoCoM流程以便于理解。
3.1.1 目标社区检测。给定一个图\(G=(\mathcal{V}, \mathcal{E}, \mathbf{X})\),其中\(\mathcal{V}\)是节点集,\(\mathcal{E}\)是边集,\(\mathbf{X}\)表示节点特征矩阵。在图\(G\)中,一个社区\(C \subset \mathcal{V}\)表示一组节点,这些节点在它们的边连接或特征上保持某些期望的特性。以\(m\)个标记社区集\(\{\dot C^{(i)}\}_{i=1}^m\)作为训练数据,目标社区检测任务定义为在图中识别其他潜在相似社区的集合\(\{\hat{C}\}\)。现有的半监督方法[41, 49]通过将\(m\)设置为500来依赖大量训练样本。为了减少对标记信息的依赖,遵循少样本设置,将\(m\)固定为一个更小的数字,例如10。
3.1.2 PRoCoM流程。遵循“预训练,提示”的两阶段范式[33]来实现PRoCoM框架。在预训练阶段,的目标是通过采用精心设计的预训练目标来理解图中的潜在社区。这使能够学习一个基于图神经网络(GNN)的编码器 GNN\(_\Theta(\cdot)\)。随后,获得每个节点的嵌入\(\mathbf{z}(v) \in \mathbb{R}^d, \forall v \in \mathcal{V}\),通过聚合成员的表示来计算社区\(C\)的嵌入,即\(\mathbf{z}(C) = \sum_{u \in C} \mathbf{z}(u)\)。在提示学习阶段,以\(m\)个标记社区作为提示,的目标是在保持\(\mathrm{GNN}_{\Theta}(\cdot)\)固定的情况下预测网络内潜在的相似社区。通过这种方式,利用保留的知识以最小的调整负担来识别目标社区。
3.2双重上下文感知预训练
利用预训练阶段使图神经网络编码器 GNN\(_\Theta(\cdot)\) 能够识别网络中存在的各种结构性上下文,获得对社区的丰富理解,以利于下游任务。具体来说,设计了双级预训练目标,即节点到上下文的接近度和上下文区分。这些目标捕捉了潜在社区的潜在结构,并区分它们的独特特征。
3.2.1 节点到上下文的接近度。在第一个目标中,使模型能够学习单个节点与它们存在的更广泛上下文之间的关系。上下文通常表现出密集的连接并共享相似的特征[8, 10, 16],使它们成为社区的有前途的候选。通过引导模型理解这些关系,它获得了对网络中存在的社区结构的宝贵见解。
对于实现,首先随机抽取一批节点\(\mathcal B\subset \mathcal V\)。然后,对于每个节点\(\upsilon\in\mathcal{B}\),提取其上下文作为其\(k\)-ego网络\(\mathcal N_{v}^{(k)}\)。这个子图包括中心节点\(v\)及其在\(k\)跳内的邻居,有效地捕捉了节点的周围环境[21, 33]。为简便起见,省略上标\(k\)并用\(N_{v}\)表示。在GNN上执行前向传播后,获得节点和上下文的表示分别为\(z(v)\)和\(\mathbf{z}(\mathcal{N}_{v}) = \sum_{r\in\mathcal{N}_{v}} \mathbf{z}(r)\)。为了鼓励每个节点与其周围上下文之间的一致性,使用以下InfoNCE损失[36]:
其中 n2c 表示“节点到上下文”,\(\tau\)是一个温度超参数,损失由 GNN 的权重\(\Theta\)参数化。强调对于损失,计算\(z(\mathcal N_{\upsilon})\)时均值池化和求和池化产生相同的结果,分析见附录 B。通过最大化每个节点与其周围上下文之间的相似性,模型学会了捕捉节点与其潜在关联社区之间的内在关系,促进了对网络中社区结构的理解。
注解:
ego Network: 又称自我中心网络,网络节点由唯一的一个中心节点(ego),以及这个节点的邻居(alters)组成。
温度超参数:在机器学习中,特别是在使用基于概率的模型或损失函数时,"温度"(temperature)超参数是一个重要的概念,尤其在信息论和能量基模型(如InfoNCE损失函数)中常见。温度超参数用于控制模型输出的平滑度或决策的自信程度。温度参数通常用于调整模型输出的"softmax"函数中的梯度或概率分布的熵。具体来说,它影响模型如何将其输出解释为概率:
- 较低的温度值:使得概率分布更加尖锐,即模型对其预测更有信心。
- 较高的温度值:使得概率分布更加平坦,即模型对其预测不那么确定。
3.2.2 上下文区分。在第二个目标中,的目标是通过鼓励模型根据它们的独特特征区分不同上下文,来增强模型对潜在社区特征的理解。
对于实现,由于已经获得了节点\(v\)的上下文\(\mathcal N_{v}\),通过随机丢弃节点或边[46]进行结构扰动,创建一个损坏的上下文\(\tilde{\mathcal N}_{v}\)。然后,优化目标被设计为引导原始上下文\(z(\mathcal N_{\upsilon})\)和损坏上下文\(z(\tilde{\mathcal N}_{v})\)之间的一致性:
其中下标表示“上下文到上下文”。通过最大化单个上下文内的相似性,使模型能够洞察图中存在的潜在社区的独特特征。
3.2.3 总结与讨论。整体优化目标结合了两个预训练目标,即\(\mathcal{L}_{\mathrm{pre-train}} = \mathcal{L}_{\mathrm{n2c}} + \lambda \cdot \mathcal{L}_{\mathrm{c2c}}\),其中\(\lambda \geq 0\)是一个超参数,决定了\(\mathcal{L}_{\mathrm{c2c}}\)的重要性权重。通过应用\(L_{\mathrm{pre-train}}\)来学习 GNN 编码器,可以获得图中固有的潜在社区知识。预训练过程的详细总结可以在附录中的算法 2 中找到。
此外,列出了几种广泛使用的图预训练策略,包括节点属性掩蔽[11]、链接预测[15, 23]、节点到节点一致性[51]、节点到图互信息最大化[37]和图到图一致性[46]。然而,这些方法没有考虑到网络中社区的存在,导致预训练过程和下游社区检测任务之间存在语义差距。
3.3提示学习

在预训练阶段之后,学习到的 GNN\(_\Theta(\cdot)\)已经获得了对网络中潜在社区及其独特特征的洞察。然后,可以通过将图输入到这个训练有素的编码器中来获得节点级表示,从而为所有节点生成表示\({Z}={GNN}_{\Theta}({X},\mathcal{E})\),其中\(z(v)\)表示节点\(v\)的嵌入。
在提示学习阶段,的目标是预测\(N\)个与给定的\(m\)个少量样本目标社区相似的新社区,记作\(\{\dot{C}^{(i)}\}_{i=1}^{m}\)。由于预训练模型包含了关于目标社区的丰富知识,的目标是将目标社区检测任务重新定义为预文本以检索这些知识。首先,通过执行节点与其周围上下文之间的邻近性分析来生成候选社区,这与第一个预文本一致。这种分析有助于根据模型学习到的节点与其所属上下文之间的关系识别潜在社区。接下来,在候选社区和提供的提示社区之间进行相似性匹配以进行最终预测,这与第二个预文本一致。通过这种方式,可以有效地利用保留的知识来增强下游任务。
3.3.1 候选社区生成。在候选生成阶段,的目标是生成一组候选社区。社区通常在某个邻域内表现出更强的连接[2, 8, 13]。因此,的目标是在给定节点的上下文中提取最有希望的社区。具体来说,引入一个参数化为\(\Phi\)的提示函数\(PT_{\Phi}(\cdot)\)如下:
其中\(\tilde{C}_{v}\)表示以节点\(v\)为中心的提取社区,\(\mathcal N_{v}\)表示上下文。注意,提示函数的输出可能是一个空集,表明对于该特定节点不存在有希望的社区。在这种情况下,忽略结果。
直观地说,对于上下文\(\mathcal N_{v}\)中的每个邻近节点\(u\),只将其分配给提取的有希望的社区\(\hat{C}_{v}\),如果它与中心节点\(v\)的接近度超过某个阈值\(\alpha\)。由于节点的表示\({z}(u)\)和\(z(v)\)已经包含了由第一个预文本(节点到上下文的接近度)引导的这种接近度信息,可以利用它们表示中编码的保留知识。然而,不是直接利用预训练的节点嵌入,而是引入了一个额外的多层感知器 [29] 以可学习的方式测量接近度。这使能够提取与目标社区相关的特定知识,学习它们独特结构模式的启发式规则。公式如下:
这里,使用一个多层感知器实现\(PT_{\Phi}(\cdot)\),\(\mathbf{z}(u),\mathbf{z}(v)\)分别表示节点\(u, v\)的表示,\(\sigma(\cdot)\)表示 Sigmoid 函数,\(\alpha \in [0,1]\)表示一个阈值参数。通过使用提供的提示社区调整 MLP,可以有效地利用保留的知识以参数高效的方式理解与目标社区相关的特定社区结构。
对于提示函数\(PT_{\Phi}(\cdot)\)的优化,利用给定提示社区提供的监督信号,这些信号提供了有关目标社区结构模式的洞察。技术上,从真实社区\(\dot C^{(i)}\)\((i = 1, 2, ..., m)\)中随机选择一个节点\(v\)并提取其上下文\(\mathcal N_{v}\)。由于每个节点\(u\in\mathcal{N}_{v}\)可以被归类为属于真实社区\(\dot{C}^{(i)}\)或不属于,其状态可以作为监督,以区分一个节点是否应该被包含在社区中。因此,使用交叉熵损失来优化\(\Phi\)如下:
其中\(\mathbb I(u,C)\)是一个指示函数,仅当节点\(u\in C\)时返回 1。注意,在提示调整阶段,只优化提示函数\(PT_{\Phi}(\cdot)\),同时保持 GNN\(_\Theta(\cdot)\)固定。此外,由于选择节点\(v\)和相应上下文有多个选择,即使给定的\(m\)数量极少,也可以为学习\(PT_{\Phi}(\cdot)\)生成大量监督信号。提示调整过程的详细总结在附录中的算法 3 中。
3.3.2 最终预测。在第二个预文本中,重点是上下文区分,引导模型学习不同上下文的独特属性。为了与这个预文本一致并检索保留的知识,将目标社区的最终预测重新定义为候选社区和提示社区之间的相似性度量。
在提示调整过程之后,进入推理阶段,利用训练有素的提示函数\(PT_{\Phi}(\cdot)\)生成候选。具体来说,将每个节点的 ego-net\(\mathcal N_{v}(v\in\mathcal{V})\)输入到提示函数\(PT_{\Phi}(\cdot)\)中,获得一组候选社区\(\{\hat{C}_{v}\}\)。有了提供的提示社区\(\{\dot{C}^{(i)}\}_{i=1}^m\)和候选社区\(\{\hat{C}_{v}\}_{v\in\mathcal{V}}\),利用预训练的编码器获得它们的相应表示\(\{\mathbf{z}(\dot C^{(i)})\}_{i=1}^{m}\)用于提示社区和\(\left\{\mathbf{z}(\hat{C}_{v})\right\}_{v\in\mathcal{V}}\)用于候选社区。这些表示在潜在空间中的\(L_{2}\)距离作为相似性的度量。为了进行最终预测,为每个提示社区选择最相似的候选社区。例如,如果的目标是预测\(N\)个新社区,返回每个提示社区\(\dot C^{(i)}\)的前\(n=\frac{N}{m}\)个最相似的候选社区[41]。