graph_model
2024年10月14日更新
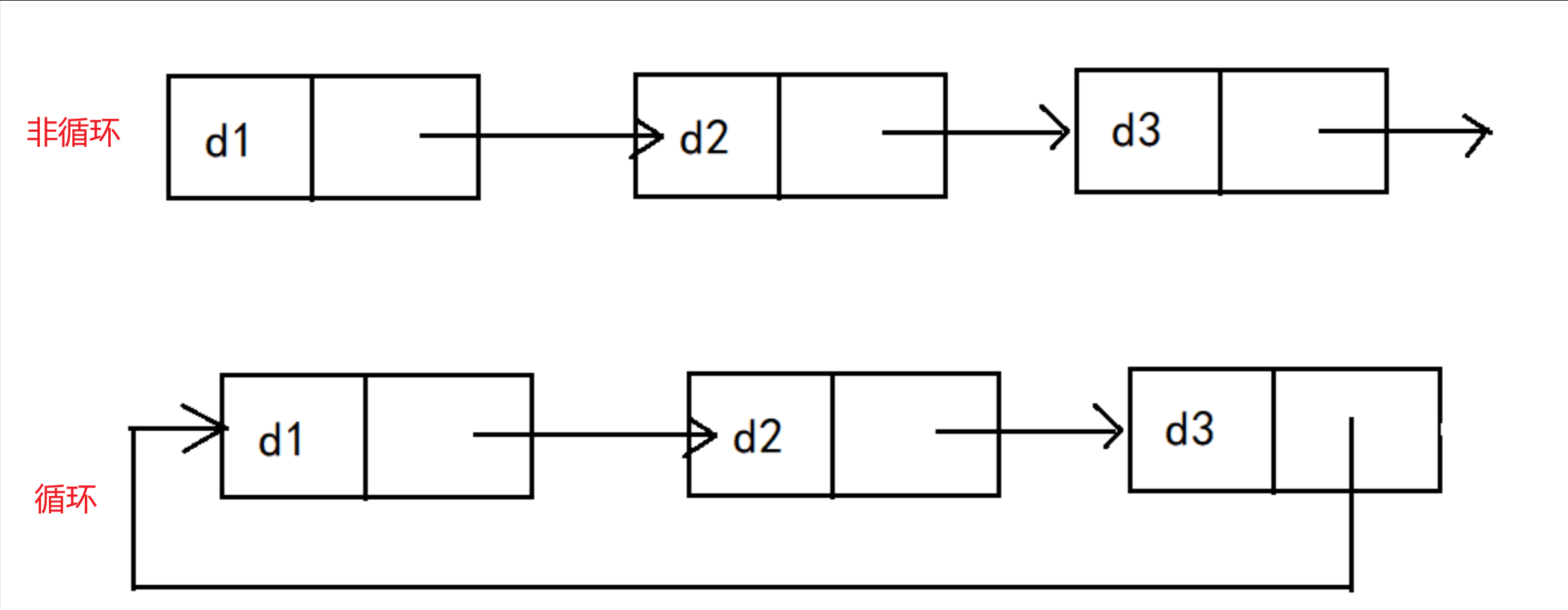
在此教程中,我们将对深度学习中的图模型及其原理进行一个简单的介绍,并实现一种图模型的训练和推理,至少支持三种数据集,目前支持数据集有:Cora、CiteSeer、PubMed等,并给用户提供一个详细的帮助文档。
目录
基本介绍
- 目前存在的问题
- 现有模型
- 应用场景
图模型实现
- 总体概述
- 项目地址
- 项目结构
- 训练及推理步骤
- 实例
成员推断攻击实现
- 总体介绍
- MIA项目结构
- 实现步骤及分析
- 结果分析
复杂场景下的成员推断攻击
- 介绍
- 代码结构
- 实现步骤
- 结果记录及分析
基本介绍
图模型(Graph Models)在深度学习中是一种能够处理非欧几里得结构化数据的强大工具,尤其适用于处理关系复杂、数据节点互相关联的场景。与传统的卷积神经网络(CNN)处理网格结构的数据(如图像、文本等)不同,图模型能够高效地处理图结构数据,如社交网络、知识图谱、分子结构等。
图模型的核心是图(Graph)这一结构,它由节点(Vertices,也称为点)和边(Edges)构成,用于表示实体(节点)及其关系(边)。具体而言,图G=(V,E)由节点集合V和边集合E组成。
图模型的学习主要是学习网络结构,即寻找最优的网络结构;以及网络参数估计,即已知网络结构,估计每个条件概率分布的参数。
目前存在的问题
图是被认为是包含丰富潜在价值的复杂结构,因此,对于复杂的图结构的数据(社交网络、电子商务网络、生物网络等),将传统深度学习架构应用到图中存在多项挑战:
-
图的不规则结构:图属于不规则领域,这使得一些基础数学运算无法泛化至图,传统的深度学习方法难以进行计算;
-
图的异质性和多样性:同质图指的是图中的节点类型关系类型都仅有一种,异质图指的是图中的节点类型或关系类型多于一种,多变的结构和任务需要不同的模型架构来解决特定的问题;
-
可扩展性和并行化:由于图中的节点和边是互连的,通常需要作为一个整体来建模,因此如何实施并行化计算是另一个关键问题;
-
融合跨学科知识:图表示通常与其他学科联系,集成领域知识会使模型设计复杂化。
上述内容参考论文《Deep Learning on Graphs: A Survey》
论文地址:https://arxiv.org/abs/1812.04202
现有模型
如下图所示,现有图深度学习方法可以分为三个大类:半监督方法、无监督方法和近期进展。具体来说,半监督方法包括图神经网络(GNN)和图卷积网络(GCN),无监督方法主要包括图自编码器(GAE),近期进展包括图循环神经网络和图强化学习。总体来说,GNN和GCN是半监督方法,因为它们利用节点属性和节点标签端到端地训练模型参数,而GAE主要使用无监督方法学习表征。近期的先进方法使用其它独特的算法(不归属前两个类别)。除了这些高层次的区别外,在模型架构上也存在很大不同。
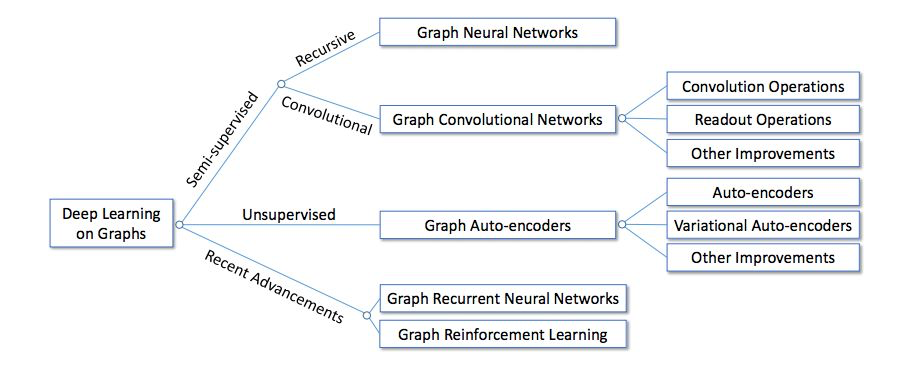
图递归神经网络(Graph RNN):图RNN通过在节点级别或图级别对状态进行建模来捕获图的递归和顺序模式,Graph RNN可以被分为:node-level RNN和graph-level RNN,且Graph RNN也可以和其它框架结合,如GCNs或GAEs。
图卷积网络(GCN):GCN是最常用的图神经网络之一,主要灵感来源于卷积神经网络(CNN),但用于非欧几里得结构的数据。GCN中每个节点的表示会基于它的邻居节点进行更新,这种信息传播方式可以有效捕捉常见的的局部特征和全局结构模式。它的核心是通过卷积运算将节点的特征向量与邻居节点的特征向量结合,逐层更新节点的表示。
图自动编码器(GAEs):GAE是一种无监督的图模型,用于图结构的嵌入学习和重构。GAE的核心是利用编码器将图的节点嵌入到低维空间,然后利用解码器来重构图的结构或预测边。它可以用来执行任务如链路预测、节点分类等。自编码器(AE)及其变体在无监督学习中得到广泛使用,它适合在没有监督信息的情况下学习图的节点表征。
图强化学习(Graph RL):Graph RL定义了基于图形的动作和奖励,以在遵循约束的同时获得图形任务的反馈。
图注意力网络(GAT):GAT引入了注意力机制,使得不同邻居节点对中心节点的影响权重不同。GAT通过自适应学习每个邻居节点的重要性权重,而不是像GCN那样简单地进行归一化。
其核心思想是计算每个邻居节点的注意力权重,然后使用这些权重加权求和邻居节点的特征。GAT 的优势在于它能够动态调整邻居节点的权重,灵活性更强。
图生成模型:这类模型用于生成新的图结构,如分子结构生成、图形网络的生成等。图生成模型通过学习一个给定图的数据分布,然后生成新的图。
常见的图生成模型有:
- 基于变分自编码器的图生成模型(Variational Graph Autoencoders, VGAE)
- 基于对抗生成网络的图生成模型(Graph GAN)
学习图形深层模型的任务可大致分为两类:
1.以节点为中心的任务:这些任务与图形中的单个节点相关联。示例包括节点分类、链路预测和节点推荐
2.以图形为中心的任务:这些任务与整个图形相关联。示例包括图分类、估计各种图属性和生成图。
应用场景
图模型的应用场景主要有以下几种:
1.社交网络分析:用户之间的关系、影响力分析、推荐系统等;
2.知识图谱:关系提取、问答系统、知识推理等;
3.生物信息学:蛋白质相互作用、分子结构分析、药物发现等;
4.交通网络:道路交通预测、公共交通调度等;
5.推荐系统:物品推荐、交互关系建模等。
图模型在深度学习中的应用极大拓展了对结构化数据的理解和处理能力。通过图卷积、注意力机制、生成模型等方法,图模型可以处理复杂的网络结构数据,广泛应用于各类实际问题。
图模型实现
总体概述
本项目旨在实现图模型中的GCN模型,并且支持多种数据集,目前该模型可以支持多种经典的图模型数据集,如Cora、CiteSeer、PubMed等。训练轮次设置为200轮,同以根据需要增加训练轮次,但是增加到一定程度就可能因为模型过拟合导致准确率无法再增加,甚至会降低。
项目地址
- 模型仓库:MindSpore/hepucuncao/Graph
项目结构
项目的目录分为两个部分:学习笔记README文档,以及GCN模型的模型训练和推理代码放在train文件夹下。
├── train # 相关代码目录│ ├── train.py # GCN模型训练代码│ └── test.py # GCN模型推理代码└── README.md
训练及推理步骤
- 1.首先运行net.py初始化模型网络的各参数
代码实现了一个简单的两层图卷积网络(GCN)模型,主要包括:两层图卷积操作,使用 ReLU 激活函数和 Dropout 技术来防止过拟合,最后输出每个节点的类别概率分布,适合用于图节点分类任务。此模型可以在图数据集上进行训练和评估,以进行节点分类任务,通过调整模型参数(如隐藏层维度、Dropout 率等),可以改善模型的性能。
- 2.同时train.py会接着进行模型训练,要加载的训练数据集和测试训练集可以自己选择,用Planetoid来读取数据集并应用特征归一化。相关代码如下:
#加载数据集
dataset_name = '数据集名称'
dataset = Planetoid(root=f'数据集存放路径', name='文件名称', transform=NormalizeFeatures())只需把数据集名称(datasets_name)更换成你要使用的数据集,并修改存放数据集的位置以及文件名称。同时,程序会将每一个训练轮次的训练过程中的损失值打印出来,损失值越接近0,则说明训练越成功。同时,每一轮训练结束后程序会打印出本轮训练在训练集上的准确率和测试集上的准确率。
- 3.由于train.py代码会将精确度最高的模型权重保存下来,以便推理的时候直接使用最好的模型,因此运行train.py之前,需要设置好保存的路径,相关代码如下:
torch.save(net.state_dict(), '保存路径')默认保存路径为根目录,可以根据需要自己修改路径,如果该文件路径不存在,程序会自动创建。- 4.保存完毕后,我们可以运行test.py代码,同样需要加载数据集(和训练过程的数据相同),步骤同2。同时,我们应将保存的最好模型权重文件加载进来,相关代码如下:
model.load_state_dict(torch.load("文件路径"))文件路径为最好权重模型的路径,注意这里要写绝对路径,并且windows系统要求路径中的斜杠应为反斜杠。调用model.eval()方法将模型切换到评估模式,这里通过在数据集中随机选择图片进行推理测试。
- 5.最后是推理步骤,程序会选取测试数据集的前n张图片进行推理,并打印出每张图片的预测类别和实际类别,若这两个数据相同则说明推理成功,通过打印Match是Ture或False来显示预测是否正确。同时,程序会将选取的图片显示在屏幕上,相关代码如下:
def test(num_samples=n):pred = inference()# 获取训练集实际标签和预测标签train_mask = data.train_maskactual_labels = data.y[train_mask] # 实际标签predicted_labels = pred[train_mask] # 预测标签# 随机选择 num_samples 个样本的索引sample_indices = random.sample(range(train_mask.sum().item()), num_samples)# 打印实际标签与预测标签for sample_index in sample_indices:idx = train_mask.nonzero(as_tuple=True)[0][sample_index] # 获取训练集中样本的实际索引actual = actual_labels[idx].item()predicted = predicted_labels[idx].item()print(f'Actual: {actual}, Predicted: {predicted}, Match: {actual == predicted}')推理图片的数量即n取多少可以自己修改,同时每张测试的图片都会可视化出来,使用灰度图像显示,需要手动关闭图片才会在屏幕中打印出结果。实例
这里我们以经典的图数据集Cora为例:
运行train.py之前,要加载好要训练的数据集,如下图所示:

以及训练好的最好模型权重best_model.pth的保存路径:
最好的模型权重保存在设置好的路径中:

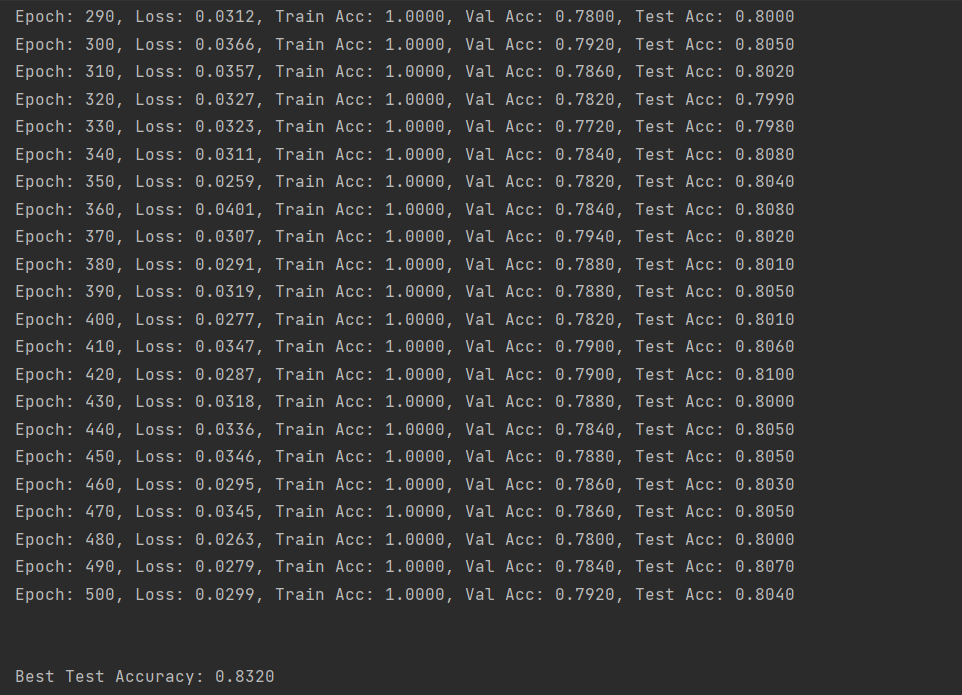
从下图最后一轮的损失值和精确度可以看出,训练的成果是较为准确的,基本都在80%以上,最后会打印出所有训练轮次中精确度最高是多少。
最后我们运行test.py程序,首先要把train.py运行后保存好的best_model.pth文件加载进来,设置的参数如下图所示:

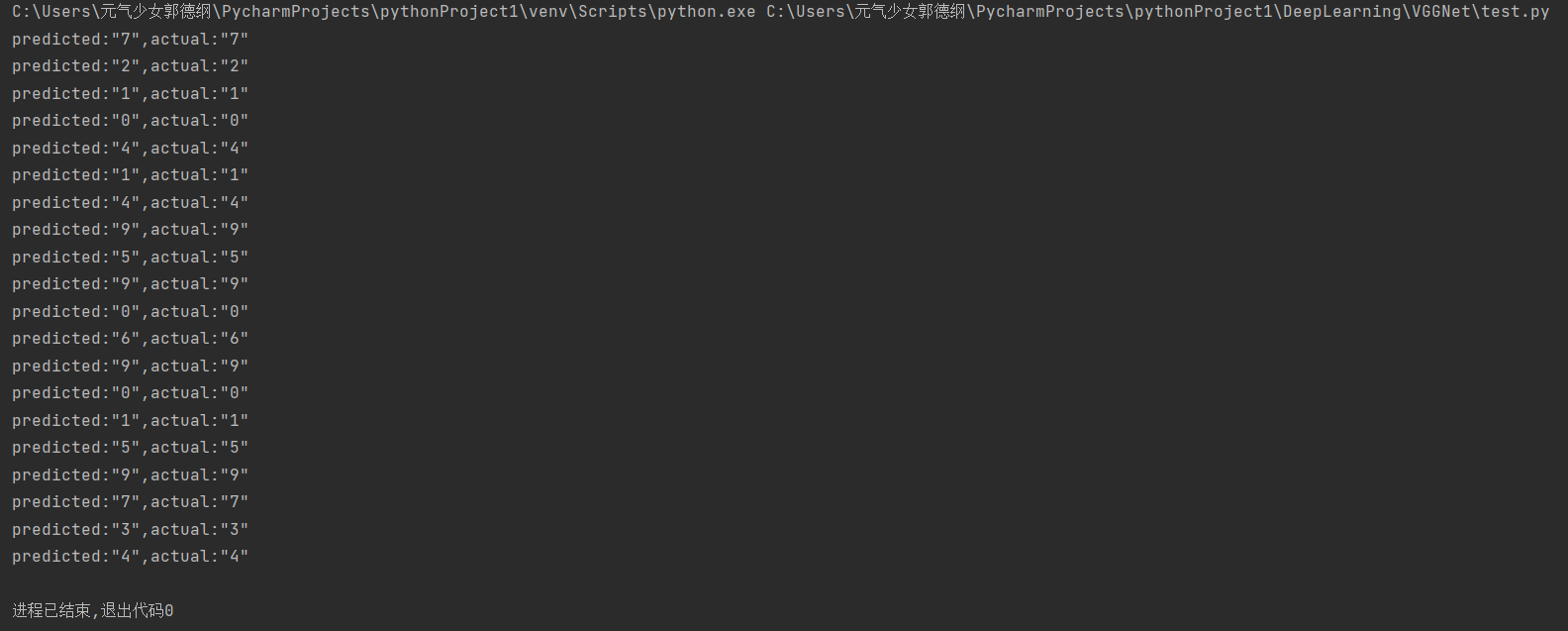
这里我们设置随机选择推理测试数据集中的20张图片,每推理一张图片,都会弹出来显示在屏幕上,要手动把图片关闭才能打印出预测值和实际值:

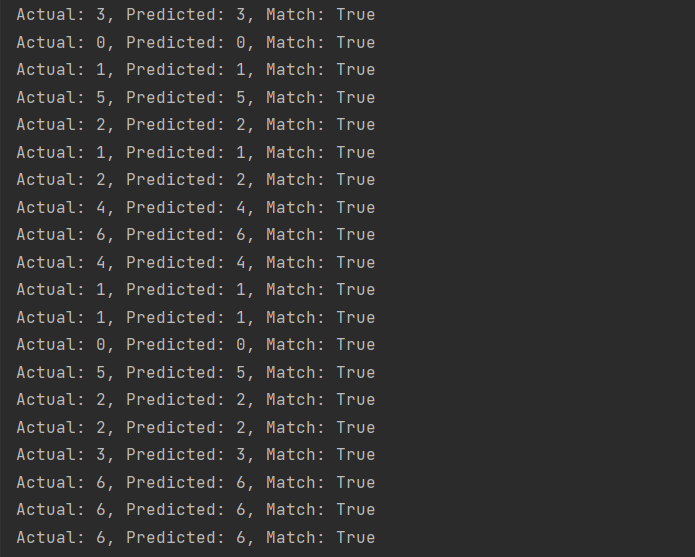
由下图最终的运行结果我们可以看出,推理的结果是较为准确的,预测值和真实值都是相匹配的,读者可以增加推理图片的数量以测试模型的准确性。
其他数据集的训练和推理步骤和Cora数据集大同小异,但是可能要根据不同数据集对模型进行微调以提高模型准确率。
成员推断攻击实现
总体介绍
本项目旨在实现GCN模型的成员推断攻击,并且支持多种数据集,目前该模型可以支持多种经典的图数据集,如:Cora、PubMed等数据集。
MIA项目结构
项目的目录分为两个部分:学习笔记README文档,以及RNN模型的模型训练和推理代码放在train文件夹下。
├── MIA # 相关代码目录│ └── graph_model.py # GCN网络模型代码│ └── run_attack1.py #修改前成员推断攻击代码│ └── run_attack2.py #修改后成员推断攻击代码└── README.md
实现步骤及分析
1.首先运行graph_model.py程序以初始化GCN网络模型的参数,该程序定义了一个基于图卷积网络的PyTorch模型类GCN,该模型有两层图卷积操作,并使用了经典的激活函数和正则化方法来构建图数据的特征学习。
初始化网络结构:
- num_features:输入特征的维度,即每个节点的特征数量。
- num_classes:输出类别数,即模型的分类目标数。
- self.conv1 = torch_geometric.nn.GCNConv(num_features, 16):使用 torch_geometric.nn.GCNConv来构建一个图卷积层,输入维度为 num_features(节点特征的维度),输出维度为16(图卷积生成的隐藏特征维度)。这层用于从图数据中提取特征,并输出每个节点的 16 维特征表示。
- self.conv2 = torch_geometric.nn.GCNConv(16, num_classes):定义了第二层图卷积层,将第一层生成的16维特征映射到num_classes维度的输出,即每个节点的分类输出。
forward方法定义了数据在模型中的前向传播过程:
- data.x:输入节点的特征矩阵,形状为[num_nodes, num_features],表示每个节点的特征。
- data.edge_index:边的索引矩阵,表示图结构的连接关系。
- x = self.conv1(x, edge_index):第一层图卷积操作,将节点特征x和图结构edge_index输入到第一层卷积层conv1,输出为更新后的节点特征。
- x = F.relu(x):对第一层卷积的输出特征x应用ReLU激活函数,将所有负值变为 0,保持非线性特征。
- x = F.dropout(x, training=self.training):对特征x应用Dropout操作,这是一种正则化技术,防止过拟合。training=self.training确保Dropout只在训练时生效。
- x = self.conv2(x, edge_index):第二层图卷积操作,将经过激活和Dropout后的特征x和图结构edge_index作为输入,输出每个节点的类别预测。
- return F.log_softmax(x, dim=1):对最终输出的类别进行log_softmax操作,生成每个节点在各类别上的对数概率分布。dim=1表示在每个节点的所有类别上进行softmax操作。
2.接着运行run.attack.py程序,代码主要实现了一个攻击模型的训练过程,包括目标模型、阴影模型和攻击模型的训练,可以根据给定的参数设置进行模型训练和评估。
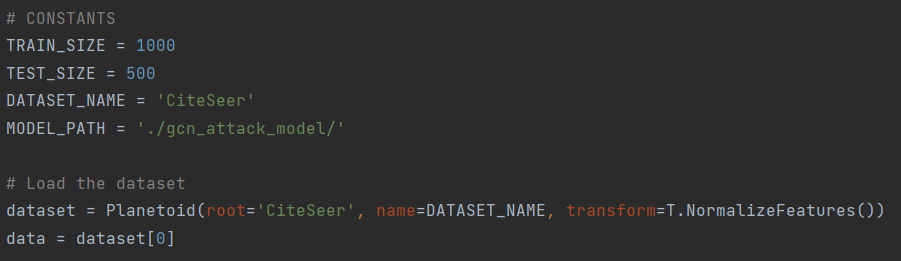
运行代码之前,要先定义一些常量和路径,包括训练集和测试集的大小、模型保存路径、数据集路径等,数据集若未提前下载程序会自动下载,相关代码如下:
TRAIN_SIZE = 1000
TEST_SIZE = 500DATASET_NAME = '数据集名称'
MODEL_PATH = '模型保存路径dataset = Planetoid(root='数据集保存路径', name=DATASET_NAME, transform=T.NormalizeFeatures())np.savez(MODEL_PATH + '影子模型参数文件名称', shadow_attack_x=shadow_attack_x, shadow_attack_y=shadow_attack_y,shadow_classes=shadow_classes)if attack_data is None:attack_data = np.load(MODEL_PATH + '攻击模型参数文件名称')其中,函数train_target_model用于训练目标模型,并为攻击模型准备数据。该函数使用generate_data_indices函数生成目标模型的训练集和影子集,调用train_gcn_model函数训练目标GCN模型,并计算准确率,同时使用prepare_attack_data函数生成用于攻击模型的数据集。
函数train_shadow_models用来训练多个影子模型,每个影子模型模仿目标模型的行为,以便为攻击模型准备数据。每次训练结束后,通过prepare_attack_data准备攻击数据,并将所有影子模型的攻击数据合并,最后将影子模型的数据保存到.npz 文件。
train_attack_model函数训练最终的攻击模型,使用影子模型和目标模型生成的数据来判断某个样本是否参与了目标模型的训练。它加载之前生成的攻击数据,并使用StandardScaler对数据进行标准化,并使用逻辑回归模型作为攻击模型,训练该模型以预测样本是否属于目标模型的训练集。
结果分析
本项目将以经典的几种图数据集为例,展示代码的执行过程并分析其输出结果。
首先要进行run_attack.py程序中一些参数和路径的定义,如下图所示:

运行后程序依次开始训练目标模型、shadow模型和攻击模型,并在屏幕上输出目标模型的损失和在训练集和测试集上的准确率、阴影模型在训练集和测试集上的准确率,以及攻击模型的最终准确率。
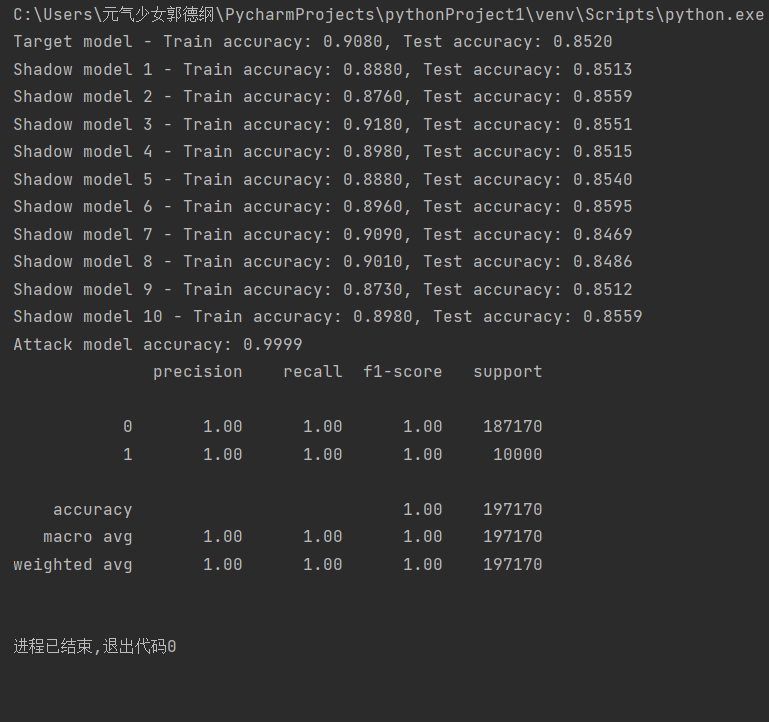
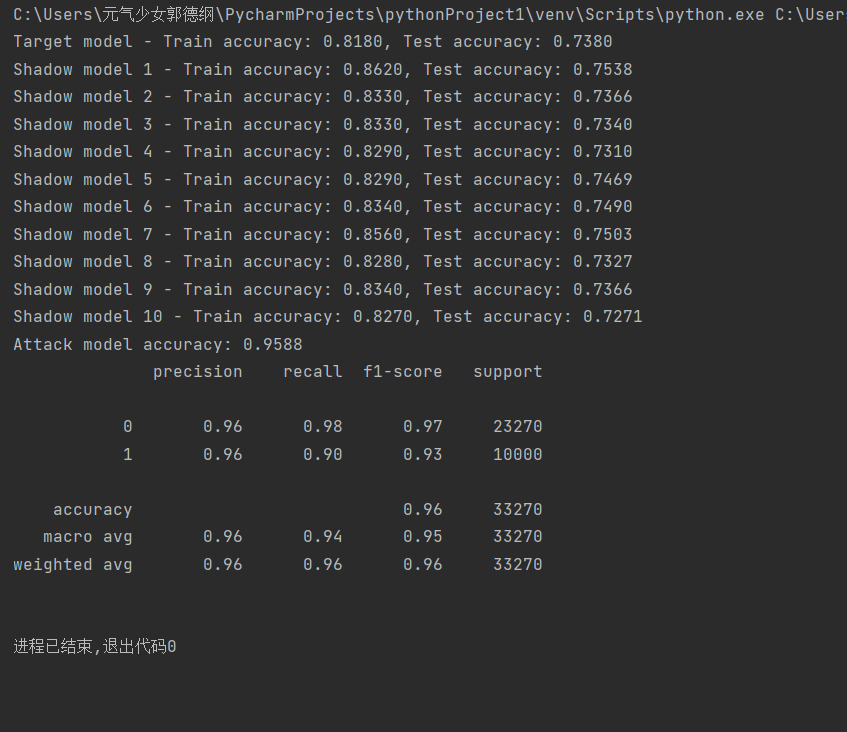
最后打印出分类报告:输出了精确度、召回率、F1分数、支持度等指标,下面给出了Cora、PubMed、CiteSeer三种数据集的攻击实例结果:
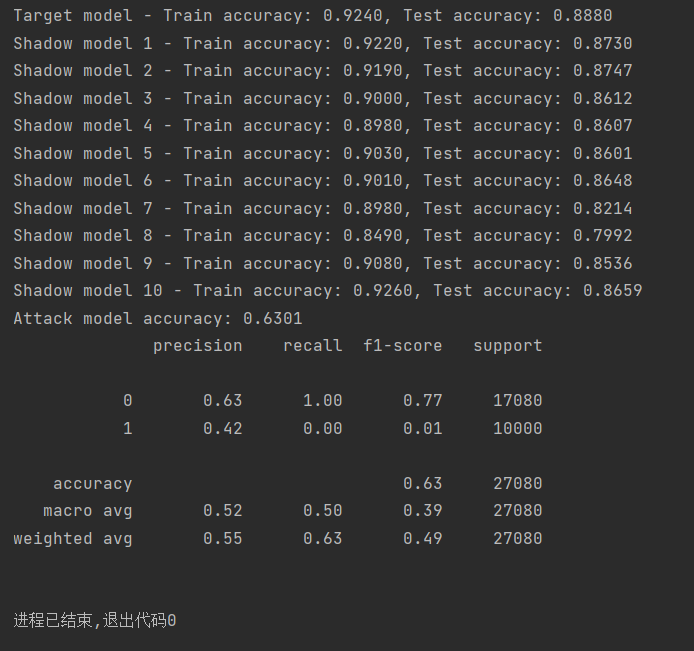
(Cora数据集成员推理攻击结果)
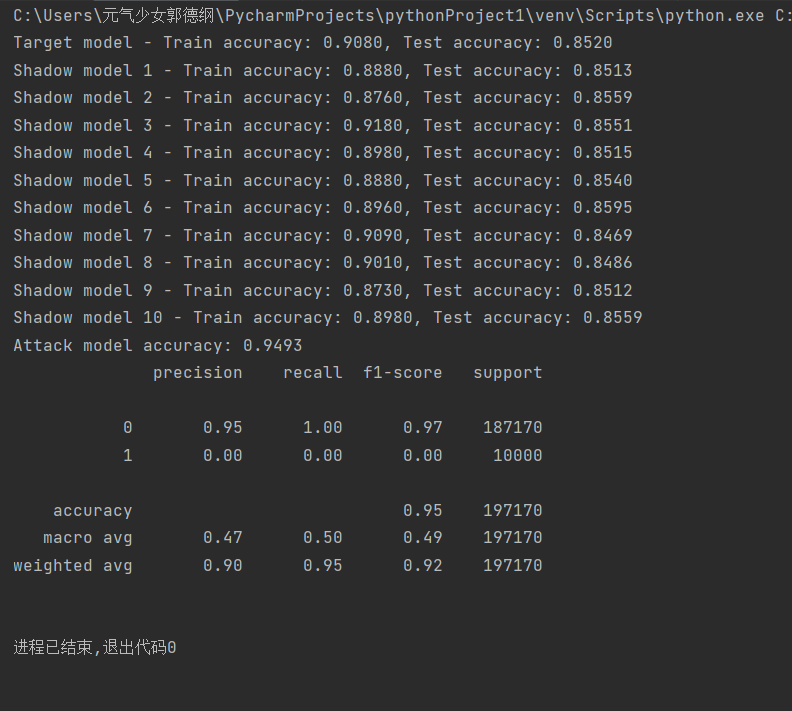
(PubMed数据集成员推理攻击结果)
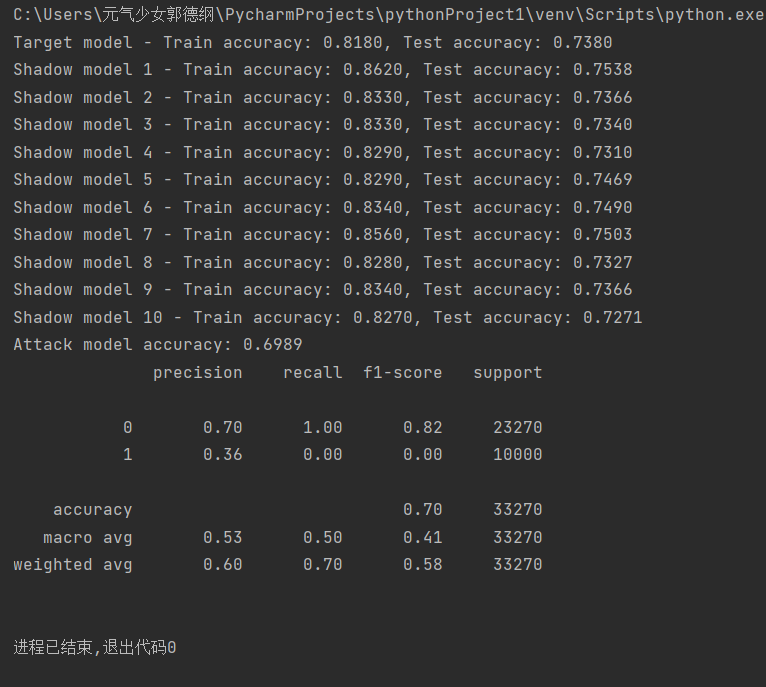
(CiteSeer数据集成员推理攻击结果)
注意:由上述结果可以看出此时(run_attack1.py)的攻击准确率大多在60-70%范围内,有待提高。因此我们尝试将攻击模型从Logistic Regression改为RandomForestClassifier,增加了特征标准化StandardScaler。从下面的结果可以看出,攻击的准确率有了大幅度的提高,且基本都能达到95%以上,甚至是100%的成功率。原因可以归纳为以下几点:
1.Logistic Regression是一种线性分类模型,它假设数据可以通过一个线性决策边界来划分。因此,它在处理线性可分的数据时表现良好,但对于具有复杂非线性结构的数据,它的表现可能会受到限制。
而RandomForestClassifier是一种集成学习方法,使用多个决策树并通过多数投票的方式做出分类决策。由于每棵树都是基于数据的随机子集和特征子集构建的,随机森林能够捕捉数据中的复杂非线性关系和特征之间的交互。因此,RandomForest在处理复杂、高维和非线性分布的数据时,通常比Logistic Regression更有优势。在成员推理攻击中,目标是利用模型输出的特征(如logits)来推断样本是否参与过训练集。GCN输出的logits并不一定具有线性分离的特性,可能包含复杂的模式。因此,RandomForestClassifier能更好地捕捉到这些复杂的非线性模式,进而提高攻击的成功率。2.Logistic Regression对输入特征的尺度比较敏感,因为它是基于线性模型进行优化的。如果输入特征的尺度相差很大,可能会导致某些特征在模型训练中比其他特征更重要,进而影响模型的性能。特征标准化可以将输入特征缩放到相同的范围,使得模型能够更公平地考虑所有特征。这对于像Logistic Regression这样的线性模型尤其重要。对于RandomForestClassifier,虽然它本身对特征的尺度不敏感,因为它主要通过特征的排序和划分数据进行决策,但在一些情况下,特征标准化仍然能够提高模型的稳定性和训练效率。比如,当特征尺度差异较大时,标准化可以使特征之间更加均衡,提高模型对不同特征的区分能力。3.模型与特征标准化的协同作用,Logistic Regression受益于标准化,因为它能够使模型在高维空间中更好地找到分离数据的线性边界。然而,由于其线性本质,它的分类能力仍然有限。RandomForestClassifier则在处理非线性数据时具有更高的表现力,而标准化进一步确保了模型能够充分利用所有特征。由于随机森林基于特征的划分来构建决策树,标准化可以使其在处理特征值范围差异较大的数据时更加高效。因此,将攻击模型从Logistic Regression替换为RandomForestClassifier,再结合特征标准化,可以有效地提高模型捕捉复杂特征模式的能力,进而提高成员推理攻击的成功率。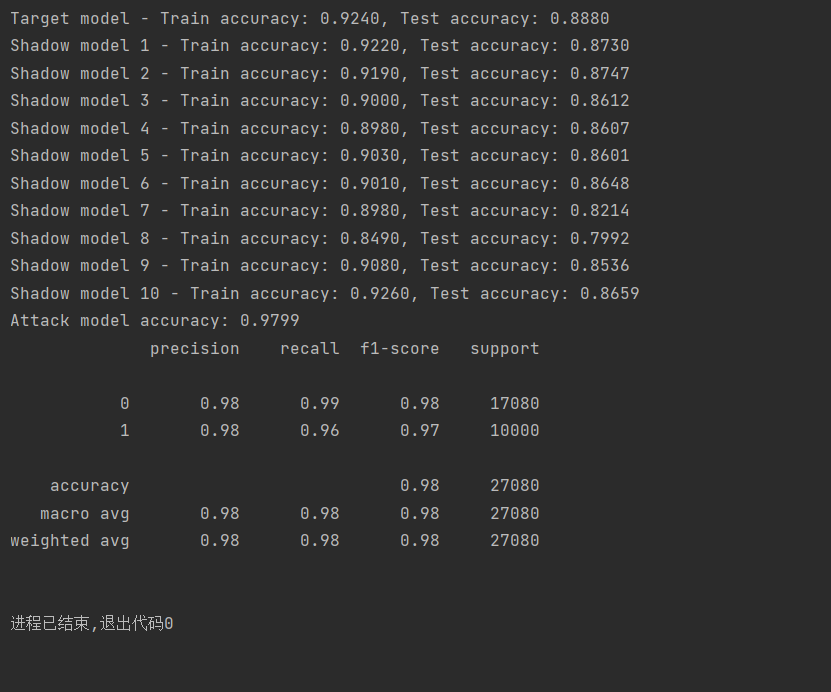
(Cora数据集成员推理攻击结果)
(PubMed数据集成员推理攻击结果)
(CiteSeer数据集成员推理攻击结果)
复杂场景下的成员推断攻击
介绍
该过程主要是在GCN模型的基础之上开启复杂场景下的成员推断攻击,以经典的图数据集Cora为例。
首先,分别对模型的训练数据集Cora随机删除5%和10%的数据,记录删除了哪些数据,并分别用剩余数据重新训练GCN模型,形成的模型包括原GCN模型,删除5%数据后训练的GCN模型,删除10%数据后训练的GCN模型。然后,分别对上述形成的模型发起成员推断攻击,观察被删除的数据在删除之前和之后训练而成的模型的攻击成功率。最后,记录攻击对比情况。
上述是完全重训练的方式,即自动化地实现删除,并用剩余数据集训练一个新模型,并保存新模型和原来的模型。本文还采用了其他更快的方法,即分组重训练,具体思路为将数据分组后,假定设置被删除数据落在某一个特定组,重新训练时只需针对该组进行重训练,而不用完全重训练。同样地,保存原来模型和分组重训练后的模型。
代码结构
├── Complex # 相关代码目录│ ├── GCN # GCN模型训练代码│ └── net.py # GCN网络模型代码│ └── graph_train.py # GCN模型完全重训练代码│ └── graph_part_train.py #GCN模型分组重训练代码├ ├── MIA_attack # 攻击代码│ └── graph_model.py #GCN网络模型代码│ └── run_attack.py # 成员推断攻击代码└── README.md
实现步骤
- 首先进行删除数据的操作,定义一个函数delete_random_nodes,该函数用于从给定的PyTorch数据集中随机删除一定百分比的数据,并返回剩余的数据集和被删除的数据的索引。相关代码如下:
def delete_random_nodes(data, percentage):num_nodes = data.num_nodesnum_to_delete = int(num_nodes * percentage)all_indices = np.arange(num_nodes)np.random.shuffle(all_indices)indices_to_delete = all_indices[:num_to_delete]new_train_mask = data.train_mask.clone()new_train_mask[indices_to_delete] = False #删除指定节点return new_train_mask, indices_to_delete其中,percentage:要从数据集中删除的数据的百分比,indices_to_delete:包含所有未被删除的数据的索引,new_train_mask:一个布尔型的张量(Tensor),用于标识哪些节点被用于训练。特别地,如果要使用分组重训练的方式来训练模型,删除数据的方式和上述不同。我们需要首先对训练数据集train_dataset进行分组,然后在删除数据时随机删除特定组的数据,因此再进行模型训练时我们只需要针对该组数据进行重训练,从而加快模型训练速度。相关代码如下:
group_size = len(train_dataset) // n
removed_group = random.randint(0, n-1)
remaining_indices = [i for idx, i in enumerate(range(len(train_dataset))) if idx // group_size != removed_group]
remaining_train_dataset = torch.utils.data.Subset(train_dataset, remaining_indices)
train_dataloader_partial = torch.utils.data.DataLoader(remaining_train_dataset, batch_size=16, shuffle=True)其中,n的值决定我们删除数据的比例大小,我们可以根据需要自定义地将数据分成n个组,并通过随机函数随机删除其中一个组的数据。2.然后通过改变percentage的值,生成对未删除数据的数据集、随机删除5%数据后的数据集和随机删除10%数据后的数据集,然后重新训练GCN模型,形成的模型包括原GCN模型,删除5%数据后训练的GCN模型,删除10%数据后训练的GCN模型。
具体训练步骤与原来无异,区别在于要调用delete_random_nodes函数生成删除数据后的数据集,举例如下:
new_train_mask, deleted_indices = delete_random_nodes(data, deletion_percentage),其中deletion_percentage是要删除的数据比例
data.train_mask = new_train_mask注意:如果是在同一个程序中生成用不同数据集训练的模型,要记得在前一个模型训练完之后重新初始化模型,如mmodel = create_model(),且删除5%和10%数据都是在原数据集的基础上,而不是叠加删除。3.利用前面讲到的模型成员攻击算法,分别对上述形成的模型发起成员推断攻击,观察被删除的数据在删除之前和删除之后训练而成的模型的攻击成功率,并记录攻击的对比情况。
具体攻击的方法和步骤和前面讲的差不多,不同点在于,由于这里我们用的训练模型是GCN模型,所以我们在graph_model.py中要构造这种模型的网络模型。
结果记录及分析
1.首先比较删除数据前后GCN模型的训练准确率,如下图所示:
(1)完全重训练
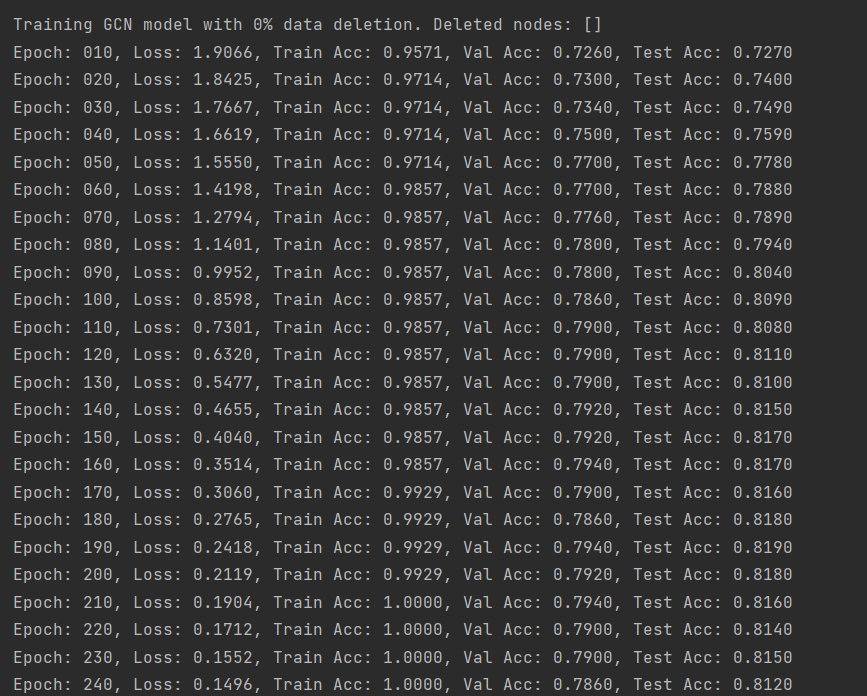
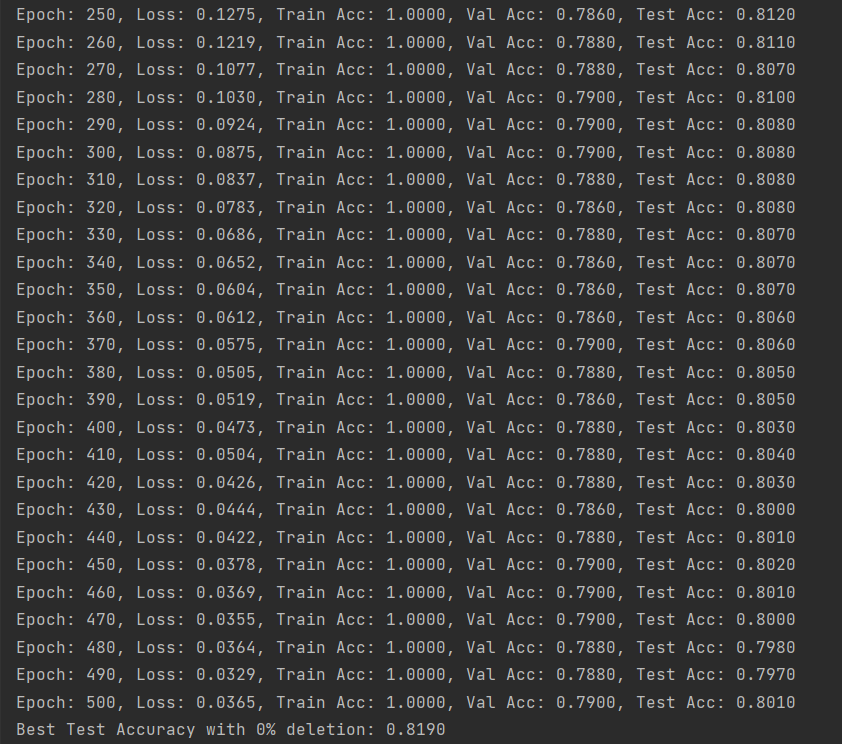
(图1:未删除数据的GCN模型训练准确率-Cora数据集)
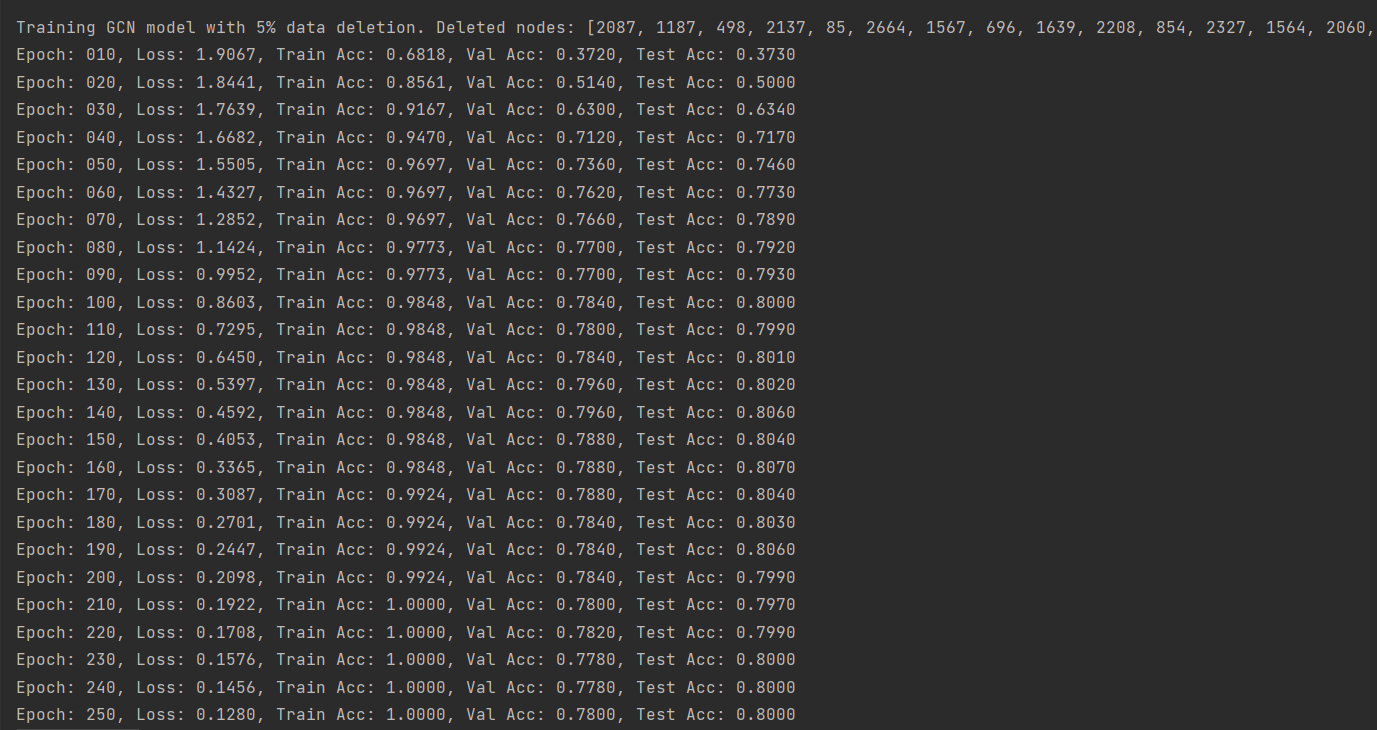
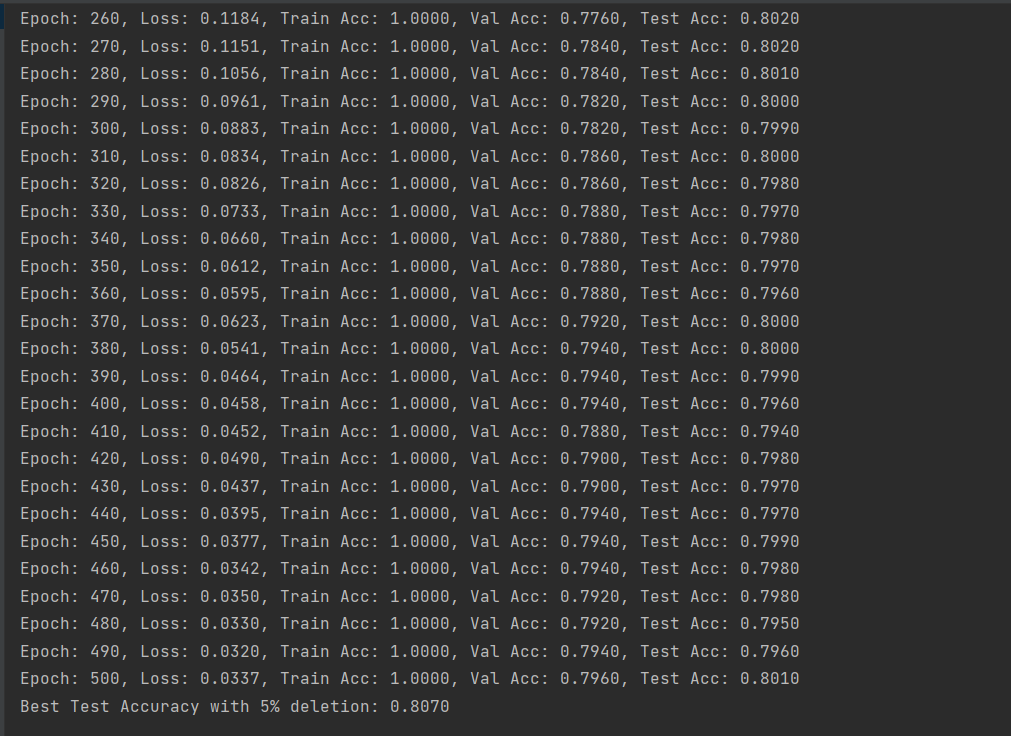
(图2:删除5%数据后的GCN训练准确率-Cora数据集)
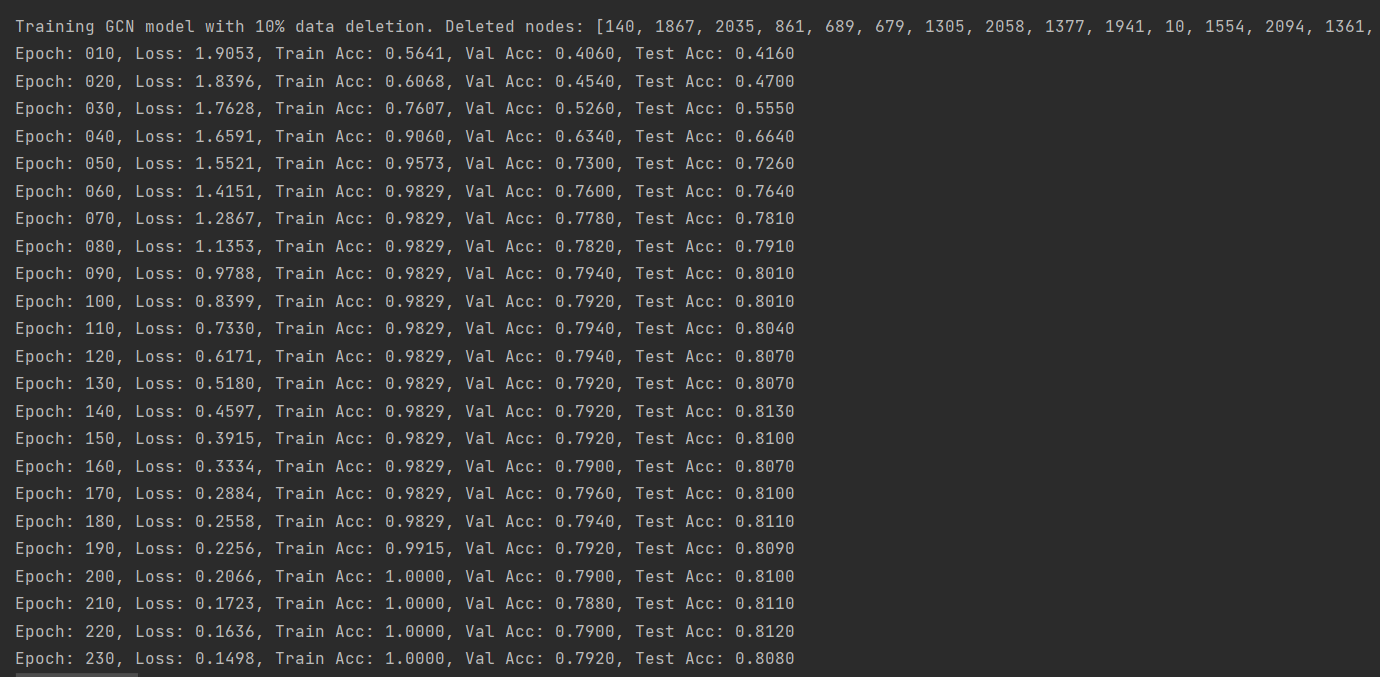
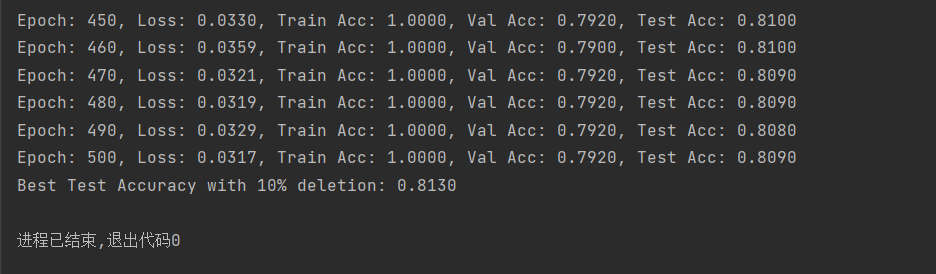
(图3:删除10%数据后的GCN训练准确率-Cora数据集)
由上述结果可以看出,删除数据后模型训练的精确度先是有小幅度的降低,然后又有小幅度的升高,但是都没有原来高。这也说明了数据的数量和模型训练精度的关系不是线性的,它们之间存在复杂的关系,需要更多的尝试来探寻它们之间的联系,而不能一概而论!
为了得到更有说服力的结果,这里我又使用了CiteSeer数据集,结果如下:
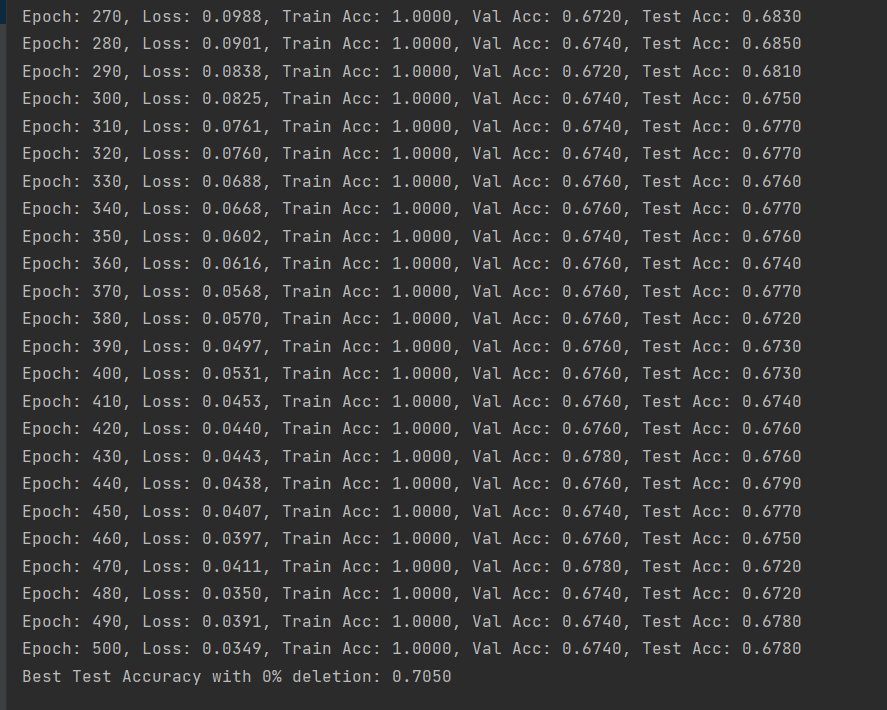
(图4:未删除数据的GCN模型训练准确率-CiteSeer数据集)
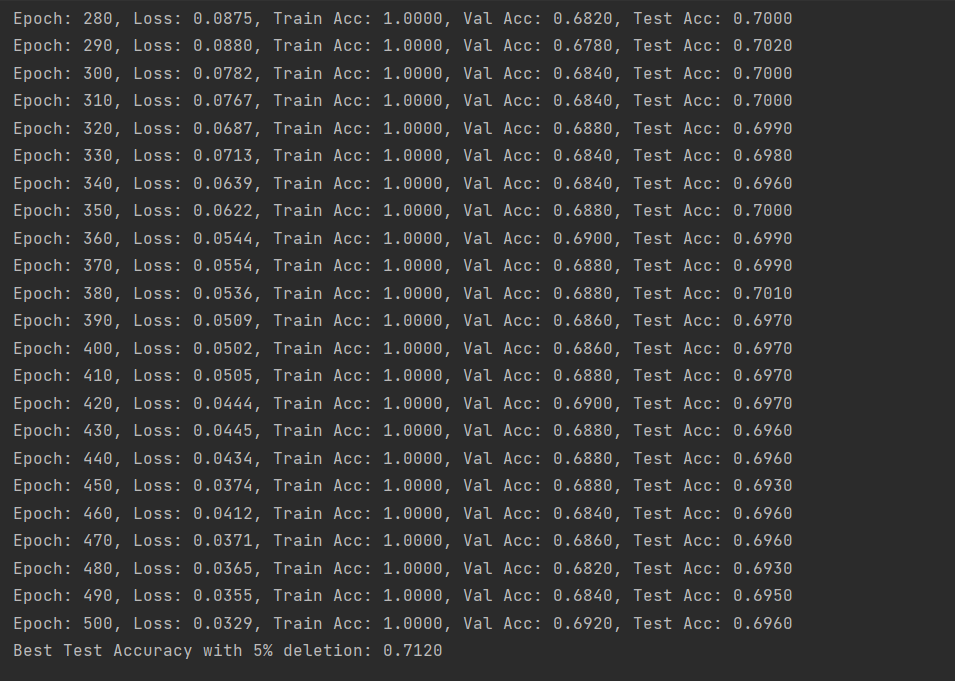
(图5:删除5%数据后的GCN训练准确率-CiteSeer数据集)
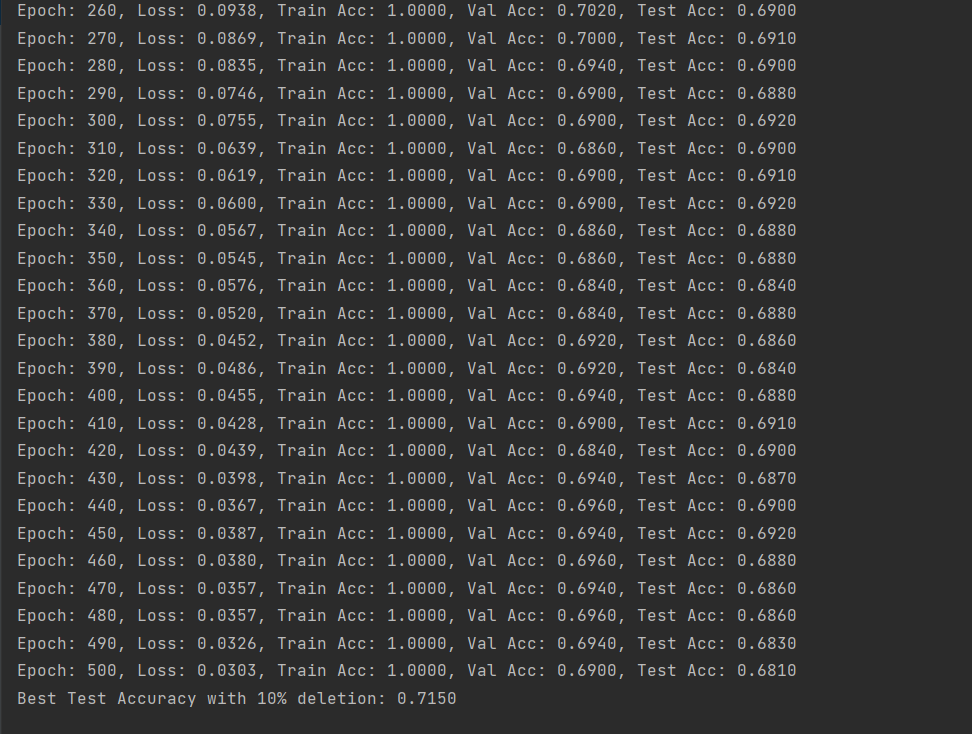
(图6:删除10%数据后的GCN训练准确率-CiteSeer数据集)
由结果可以看出,CiteSeer数据集的结果和Cora数据集的结果是有差别的,随着删除数据比例的增加,模型训练的精确度是随之上升的,因此我们无法根据单一数据集得出结论。
(2)分组重训练(以Cora数据集为例)
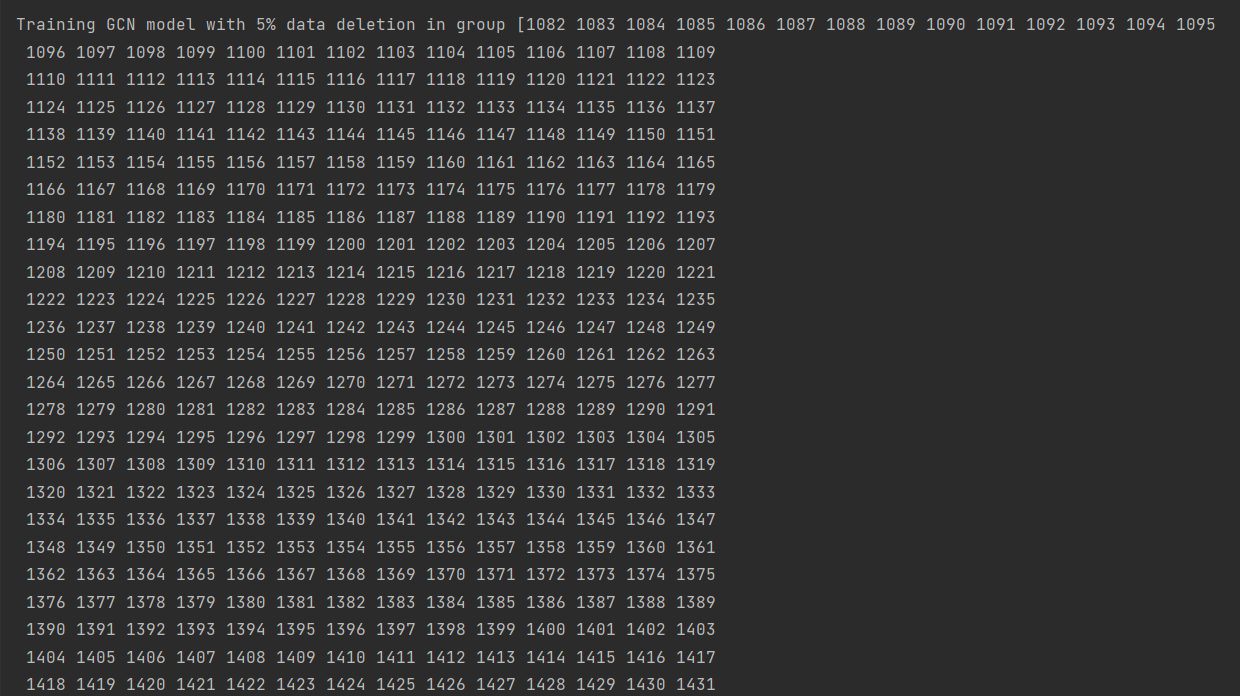
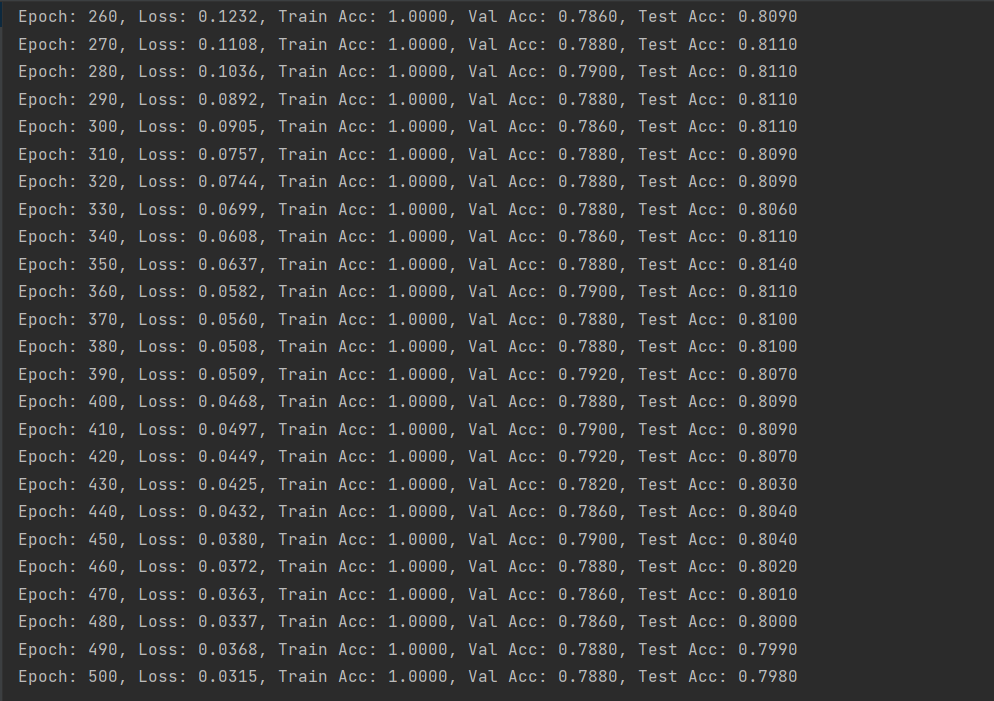
(图7:删除5%数据后的GCN训练准确率,这里随机删除了第5组的数据)
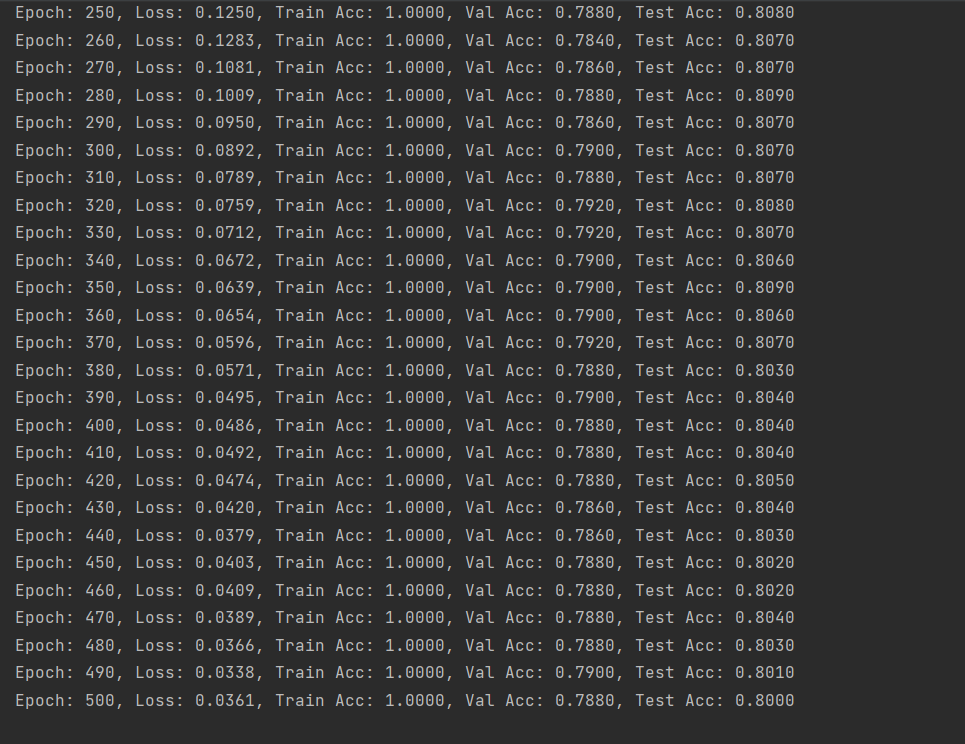
(图8:删除10%数据后的GCN训练准确率,这里随机删除了1组的数据)
训练过程中我们可以明显感觉到,采用分组重训练的方式,模型训练的速度比完全重训练快得多!
如果删除的数据是噪音数据或outliers,即不具代表性的数据,那么删除这些数据可能会提高模型的精确度。因为这些数据可能会干扰模型的训练,使模型学习到不正确的规律。删除这些数据后,模型可以更好地学习到数据的模式,从而提高精确度。但是,如果删除的数据是重要的或具代表性的数据,那么删除这些数据可能会降低模型的精确度。因为这些数据可能包含重要的信息,如果删除这些数据,模型可能无法学习到这些信息,从而降低精确度。此外,删除数据还可能会导致模型的过拟合,即模型过于拟合训练数据,无法泛化到新的数据上。这是因为删除数据后,模型可能会过于依赖剩余的数据,导致模型的泛化能力下降。
2.然后开始对形成的模型进行成员推理攻击,首先比较删除数据前后训练而成的GCN模型的攻击成功率,如下图所示:
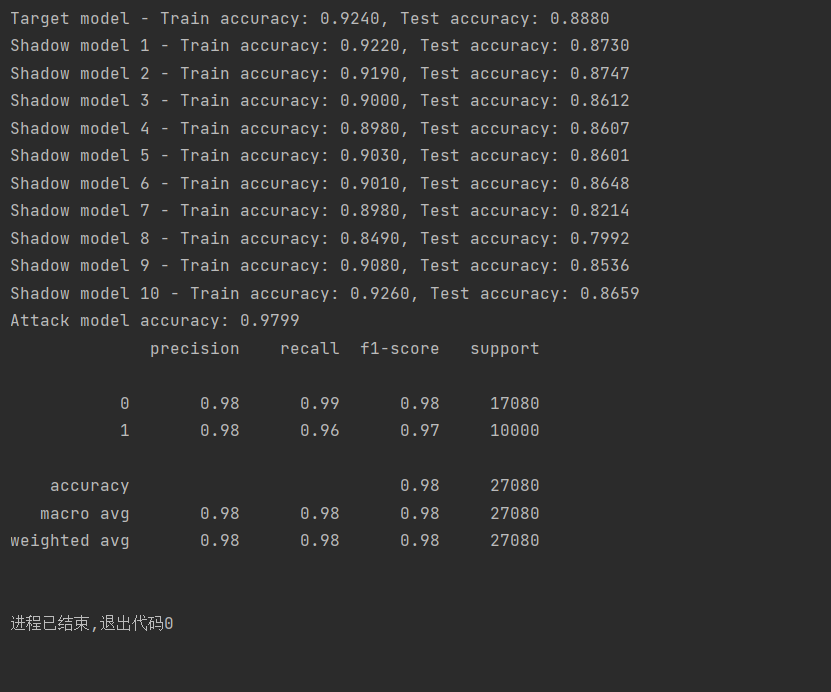
(图9:未删除数据的GCN模型攻击成功率)
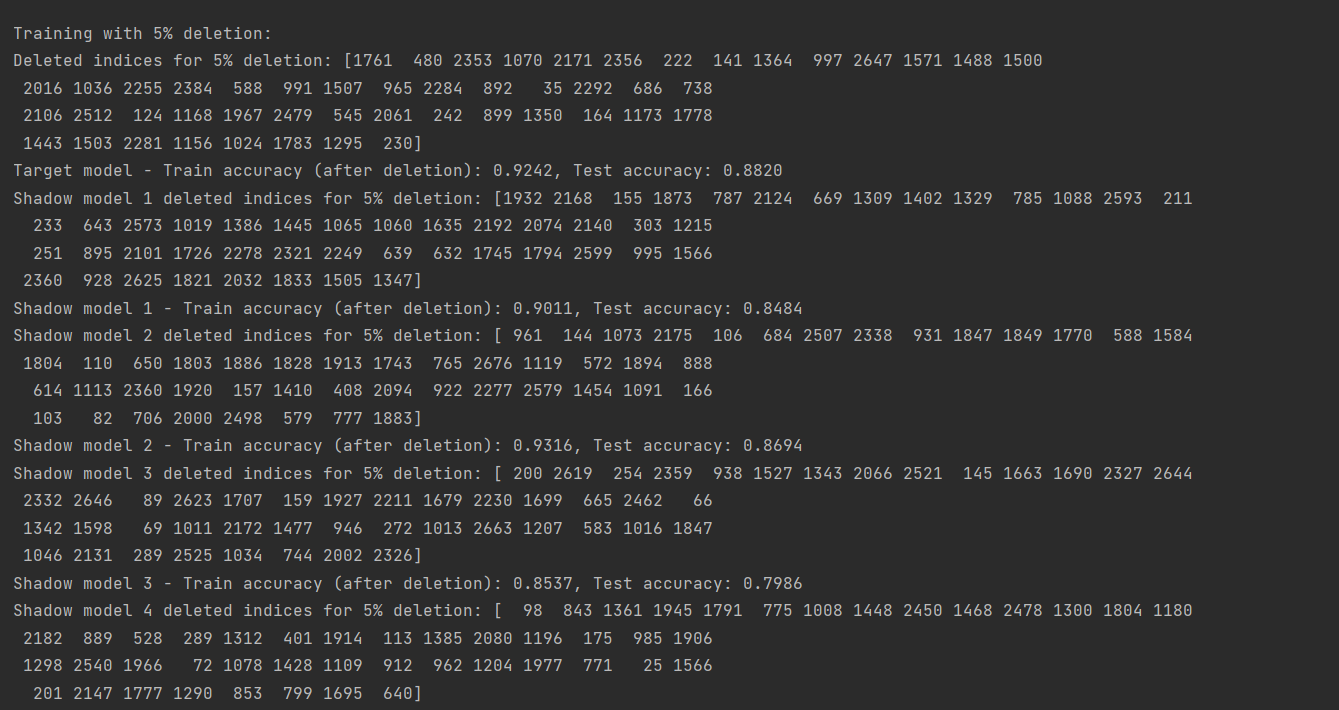
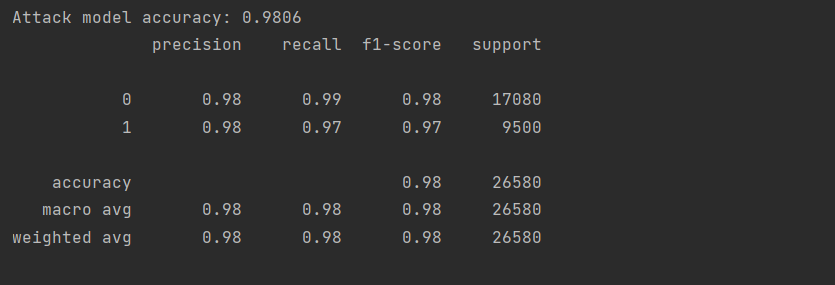
(图10:删除5%数据后的GCN模型攻击成功率)
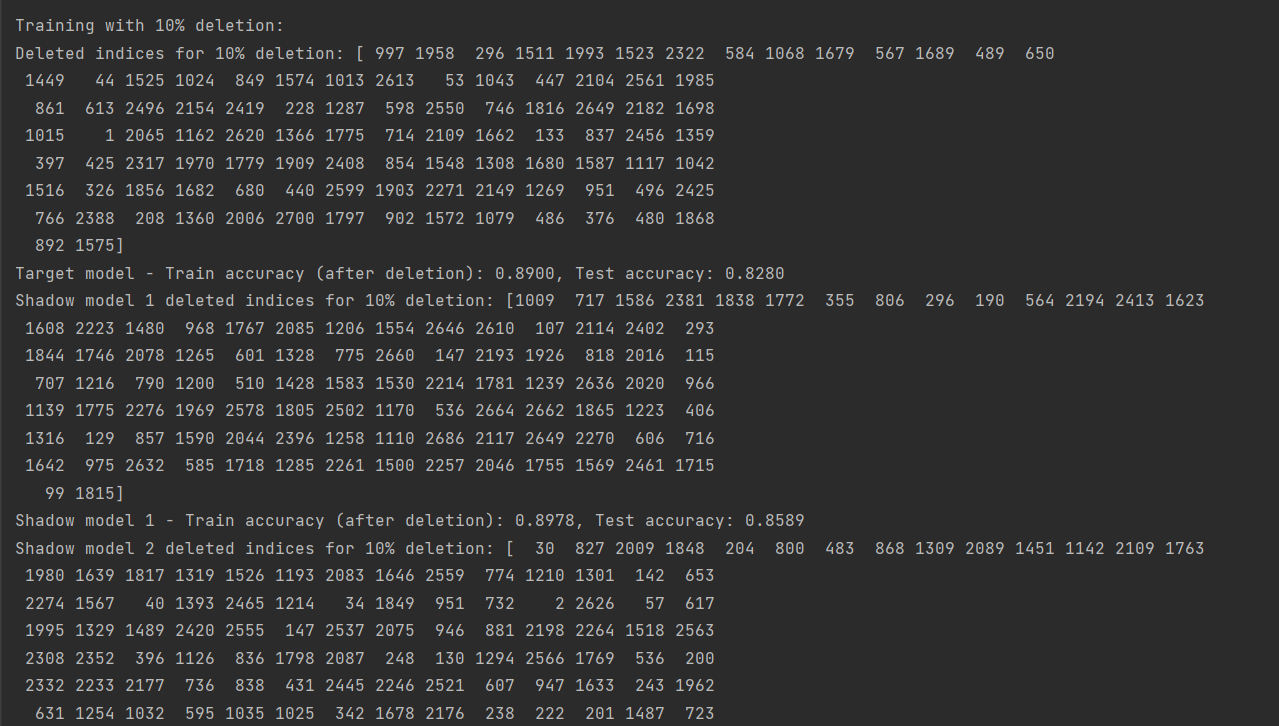
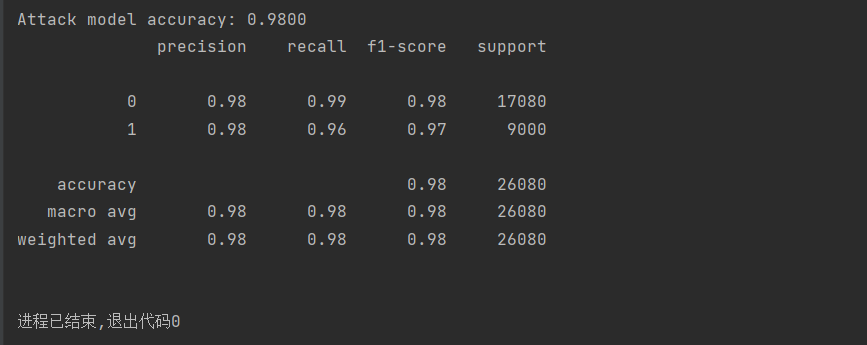
(图11:删除10%数据后的GCN模型攻击成功率)
由上述结果可知,随着删除数据的比例增加,模型成员推断攻击的成功率先是有细微地升高,然后又有细微地降低,但删除10%数据后的GCN模型攻击成功率跟不删除数据时的攻击成功率是差不多的。
删除一部分数据再进行模型成员推断攻击,攻击的成功率可能会降低。这是因为模型成员推断攻击的原理是利用模型对训练数据的记忆,通过观察模型对输入数据的行为来判断该数据是否在模型的训练集中。如果删除了一部分数据,模型的训练集就会减少,模型对剩余数据的记忆就会减弱。这样,攻击者就更难以通过观察模型的行为来判断某个数据是否在模型的训练集中,从而降低攻击的成功率。此外,删除数据还可能会使模型变得更robust,对抗攻击的能力更强。因为模型在训练时需要适应新的数据分布,模型的泛化能力就会提高,从而使攻击者更难以成功地进行成员推断攻击。但是,需要注意的是,如果删除的数据是攻击者已经知晓的数据,那么攻击的成功率可能不会降低。因为攻击者已经知道这些数据的信息,仍然可以使用这些信息来进行攻击。本项目所采用的模型都是神经网络类的,如果采用非神经网络类的模型,例如,决策树、K-means等,可能会有不一样的攻击效果,读者可以尝试一下更多类型的模型观察一下。
由结果可知,此时对于GCN模型的成员推理攻击准确率都在95%以上,可见这种攻击方式准确率还是比较高的。



![[QT] MAC使用Qt Creator运行程序如何仅运行一个进程?](https://images.cnblogs.com/cnblogs_com/RioTian/2326543/o_241212043953_image-20241212123730665.png)