key word:
Google应用商店Motivation: 作者认为一个好的推荐模型需要包含
memorization和generalization。memorization主要负责记忆法频繁出现的特征项;generalization主要负责挖掘新的特征组合;截至2016年,作者认为目前的基于神经网络的推荐模型会过度泛化并推荐相关性较低的物品(generalization);因此,作者提出Wide & Deep,在原来的深度神经网络模型中加入线性部分(memorization)。利用特征之间的简单交互而生成的交互特征是可记忆的、有效的以及可解释的。
一、WIDE & DEEP
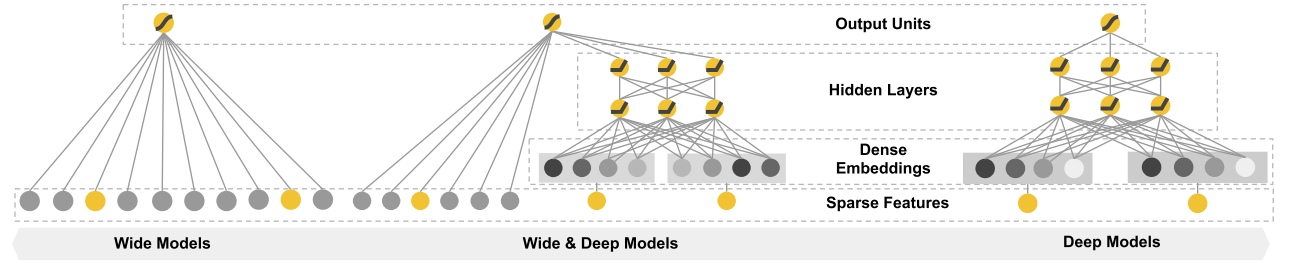
Wide
❓ Why use WIDE component
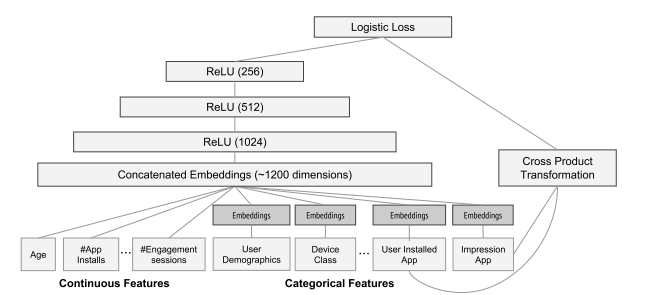
作者认为用户的查询条件与app之间的交互是稀疏、高维的。模型很难学习到有效的低纬Embedding,模型会过度泛化从而推荐相关性较低的app。因此作者提出
wide部分实现稀疏、高维特征的历史信息学习。本质上是一个逻辑回归模型。
实现 :采用一个简单的线性模型 \(y=w^Tx + b\),输入的特征为原始特征以及交叉组合特征,双重交互特征表示为:
其中,\(x_i\)表示表示第\(k\)个特征和第\(i\)个特征是否同时出现,例如AND(gender=female, language=en)这个交叉组合特征,只有gender=female和language=en均为1时才为1。
在具体实现中,作者将user installed apps和impression apps作为交叉组合特征输入到WIDE部分。笔者在学习这块内容时很难通过公式理解作者是怎么是实现特征交互的。因此展开对其的进一步学习。
import torch# 用户的 one-hot 编码,假设有三个特征:wechat, qq, tencent
user_one_hot = torch.tensor([1, 0, 1], dtype=torch.float32) # 表示 wechat=1, qq=0, tencent=1# 展示的 one-hot 编码,假设有两个特征:google, facebook
impression_one_hot = torch.tensor([1, 1], dtype=torch.float32) # 表示 google=1, facebook=1
- Cross features
本质其实就是两两的相互作用
from itertools import product# 生成交叉特征索引,笛卡尔积表示所有组合
cross_indices = list(product(range(len(user_one_hot)), range(len(impression_one_hot))))# 计算交叉特征
cross_features = []
for user_idx, impression_idx in cross_indices:cross_value = user_one_hot[user_idx] * impression_one_hot[impression_idx]cross_features.append(cross_value.item())# 转换为 PyTorch 张量
cross_features = torch.tensor(cross_features)
print("Cross Features:")
print(cross_features)
Deep
本质是一个前馈神经网络。具体实现中,embedding的维度为32维。
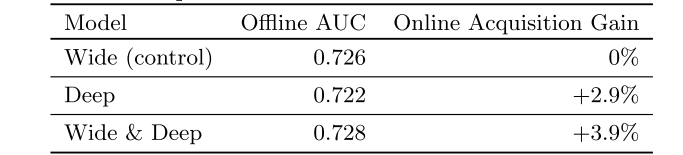
二、实验结果