我最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。今天是我们的第一站,必备的AI基础理论,它是后续应用实践的基础。
我最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。今天是我们的第一站,必备的AI基础理论,它是后续应用实践的基础。大家好,我是Edison。
由于公司的愿景逐渐调整为ONE Tech Company,公司的IT战略也逐渐地朝着Data & AI Driven发展,因此近半年来我一直在学习大模型相关的东西,从ChatGPT到Agent都有所涉及。
但是,未来的企业技术架构中会存在一个通用大模型和多个小模型以及多个IT系统协同配合的局面,单个的大模型是无法解决所有的问题的,而且也不经济实惠,这就对于我这个CRUD程序员提出了软件架构上的潜在挑战。
对于IT系统我是很熟悉的,对于大模型我也算入了个门了,但是对于小模型(通常是指针对某个业务场景的机器学习)我还不够入门,对于Python我也还没怎么用过。未来,我希望能够用.NET开发业务系统,用Python开发机器学习应用。
因此我最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第一站,必备的AI基础理论,它是后续应用实践的基础。
AI是什么?有何应用场景?
AI(人工智能)通常指通过计算机将人类完成的智力任务自动化。基于这个宏观概念,我们所了解的AlphaGo、机器狗、微软小冰 以及 ChatGPT 都是努力地完成人类的智力任务。
AI主要有以下几大应用场景:
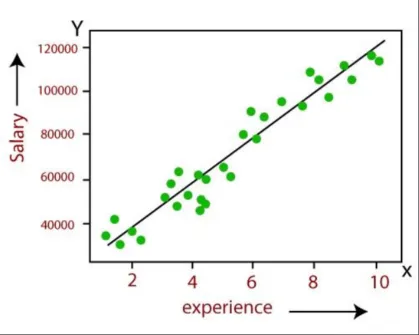
(1)预测
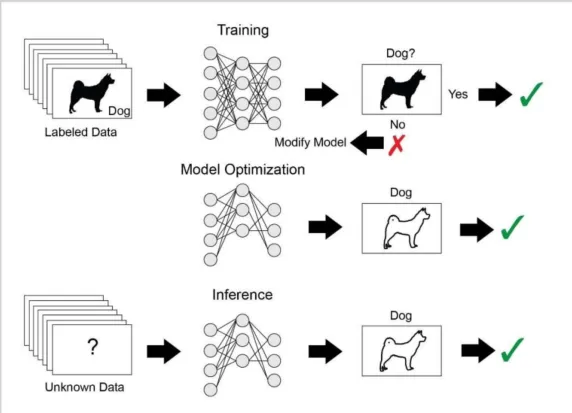
(2)分类
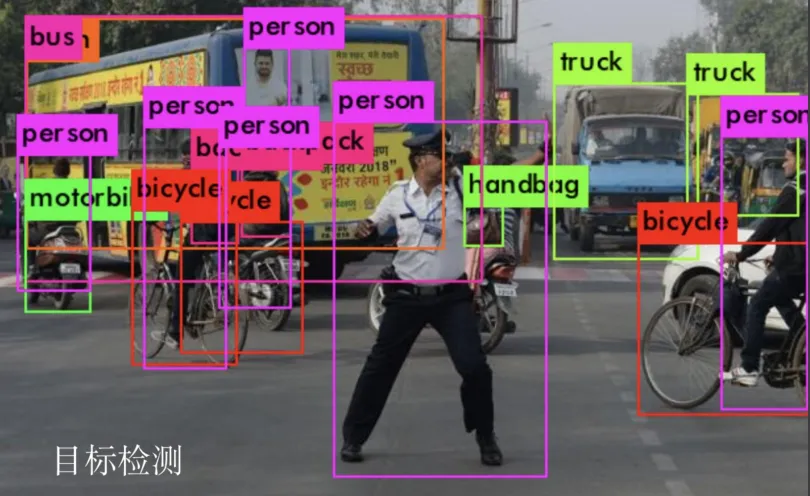
(3)目标检测
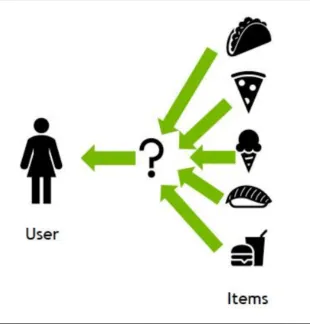
(4)推荐系统
(5)聊天机器人
我们所熟知的ChatGPT就是聊天机器人的典型场景。
人工智能,机器学习 和 深度学习
我们常常听到 人工智能、机器学习 还有 深度学习 这三个词,那么它们之间到底是个什么关系?其实,它们是一个俄罗斯套娃的子集关系:
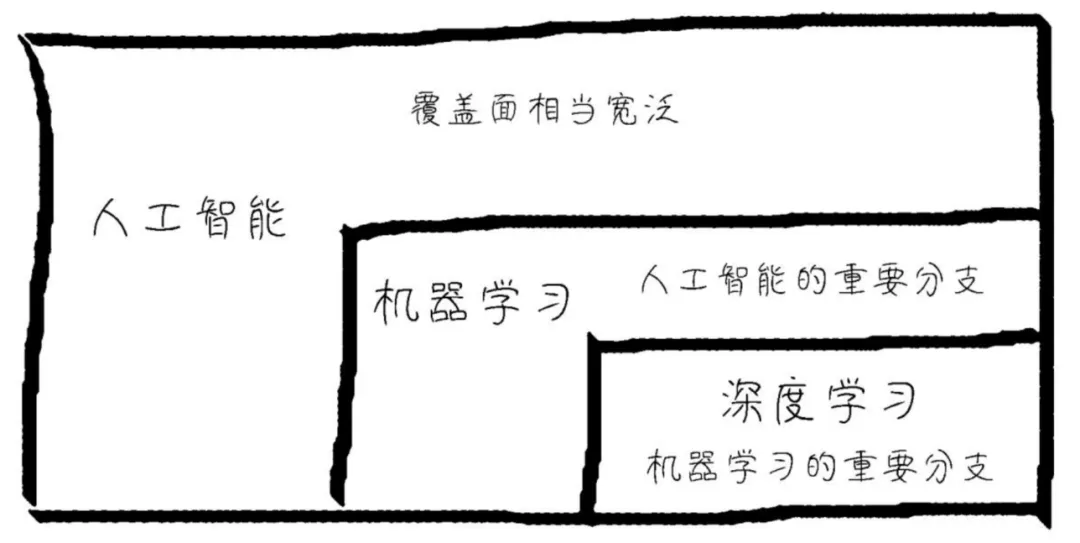
人工智能是一个覆盖面很广的名词,机器学习是人工智能的一个重要分支,而深度学习又是机器学习领域的重要分支。或许我们还会听到神经网络,它又是深度学习的理论基础。
人工智能 和 机器学习 的内涵
AI(人工智能) 的本质是:从数据中发现规律。
例如,我们会通过多个特征结合大量数据来预测某个商品如砖石的价格。
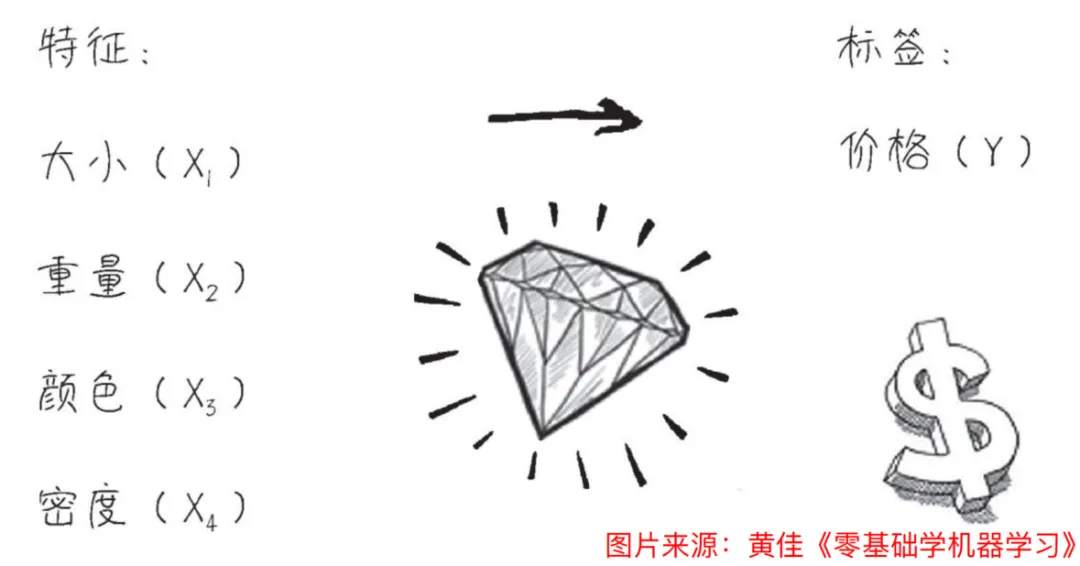
ML(机器学习)的本质是:用函数模拟事物关系。
ML 约等于 从数据中习得一个函数完成某个任务,如价格预测、图像识别等。

作为业务系统的开发者,我们平时关注的一般是确定性的逻辑,从input到output之间的逻辑是我们来编写的。而在机器学习中,通常是根据大量的output数据来倒推一个近似(无线趋近于100%但通常无法达到100%准确)的函数(我们也可以理解为是业务逻辑),为了训练和验证这个函数,我们也有大量的input数据来做测试。
机器学习的核心特点
对于机器学习,它有两个特点值得我们关注:
(1)从数据中学习
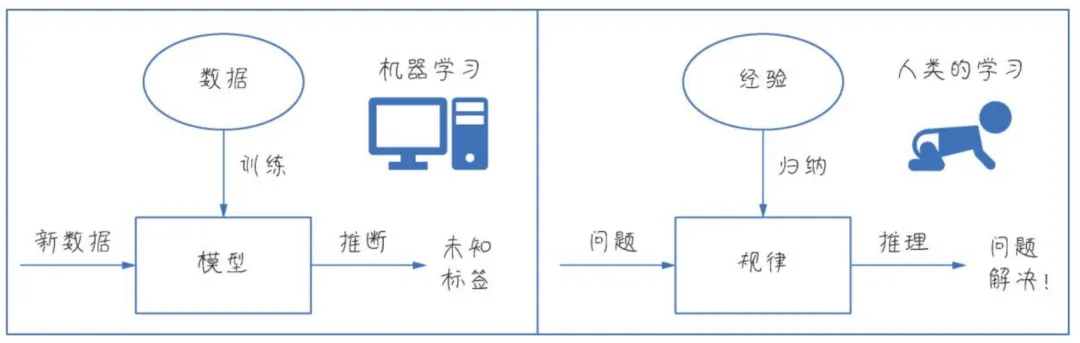
我们人类是从经验中归纳和推理,从而获得解决各种新问题的能力。而机器学习则是通过大量数据训练模型,从而推断出某种新标签解决某个场景问题。
(2)从错误中学习
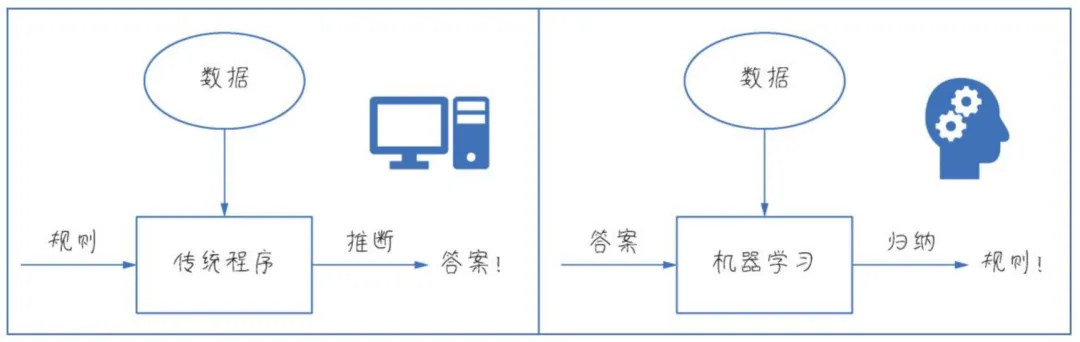
传统应用程序的开发是基于已有的规则从input到output,而机器学习是基于模型从output到归纳出一个近似的规则。这其中的训练过程会经历大量的失败(或者说错误),但我们要知道错误是常态,机器学习最擅长的就是知错就改,不断改进。而如何训练和验证模型是否有错误 又或者说是 模型的准确度呢?这就涉及到训练集、验证集 和 测试集这几个重要概念。

-
训练集:主要用于训练模型,在这个途中我们需要给模型喂训练集数据,让它学习知识。
-
验证集:类似于课后小测,在训练完之后用一部分验证集进行学习成果的验证。它最大的作用就是可以防止过拟合的现象。
-
测试集:类似于期末大考,在训练和验证完成后,用一部分真实场景数据来做测试。不过,很多小业务场景下,往往会只使用训练集 和 验证集。
机器学习的主要类型
对于机器学习,有三种主要的类型:监督学习、无监督学习 和 半监督学习。
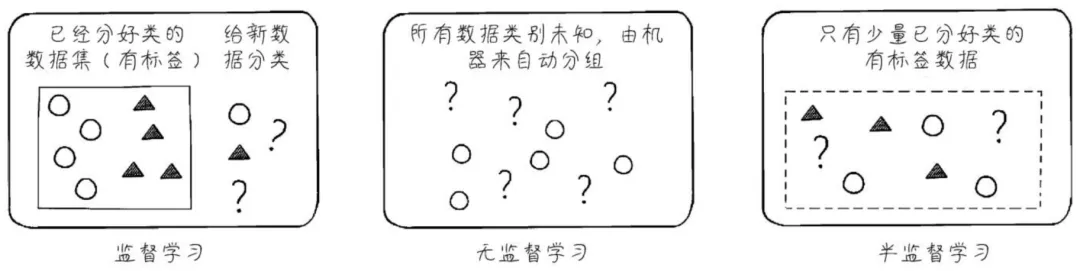
监督学习是最常见也最典型的机器学习方法,在监督学习中有一组数据 还有 对应的输出数据的标签,我们会告诉模型一堆分好类(或者说打了标签)的数据让其作为样本学习。例如,我们要让模型通过图片做猫狗的识别,就需要先给它一堆已经打了标签的猫狗图片,让其知道哪些样本识别出来是猫,哪些样本识别出来是狗,然后让其给新的图片进行猫狗识别。因此,监督学习是既有输入的数据 也有 大量输出的标签(比如猫、狗)。
无监督学习则没有任何打了标签的数据,还是以猫狗识别为例,完全让模型自己从图片样本中作分类,模型可能会将猫的图片分成一堆,狗的图片分成一堆,模型并不知道哪一堆是猫,哪一堆是狗,它只知道他们两堆的特征值不一样,而你(人类)是知道的。因此,无监督学习是只有输入的数据,没有输出的标签。
半监督学习介于监督学习和无监督学习之间,在半监督学习中有少量数据是带有标签的,另外的数据则没有带标签,然后让模型根据这少部分有标签的数据一边学习一边测试,这就是半监督学习。比如,垃圾邮件的分类,你收集一些邮件喂给模型说这些是垃圾邮件那些是正常邮件,因为你不可能把你所有的邮件数据都喂给它,这个工作量还是蛮大的,然后就让模型自己去学习并做测试。因此,半监督学习是既有输入的数据,还有少量输出的标签。
深度学习时代
可以毫不夸张的说,现在的AI正处于深度学习的时代。深度学习是机器学习实践方法中的一种,它是基于神经网络的机器学习方法。
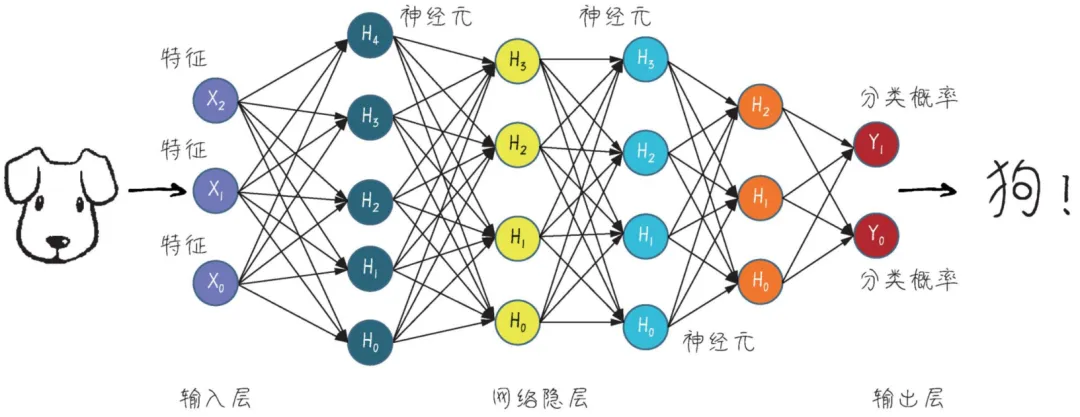
所谓神经网络,说的其实是它在模拟人类大脑神经系统,通过多个层次的大量参数来模拟一层一层的神经元的效果,这些多层次的参数节点最终形成一个巨大的参数网络,然后通过不断的参数调参,进而完成如预测、分类、NLP等任务。
神经网络最厉害的地方在于:特征的自动抽取能力。也就是说,我们不需要告诉算法该如何去抽取要解决问题的特征(在机器学习中通常这块工作量很大),它自己就可以学习和抽取特征。例如,下面这个用CNN进行手写数字的识别,要告诉算法特征值工作量很大,但是用神经网络它自己就可以一层一层地抽取到特征。
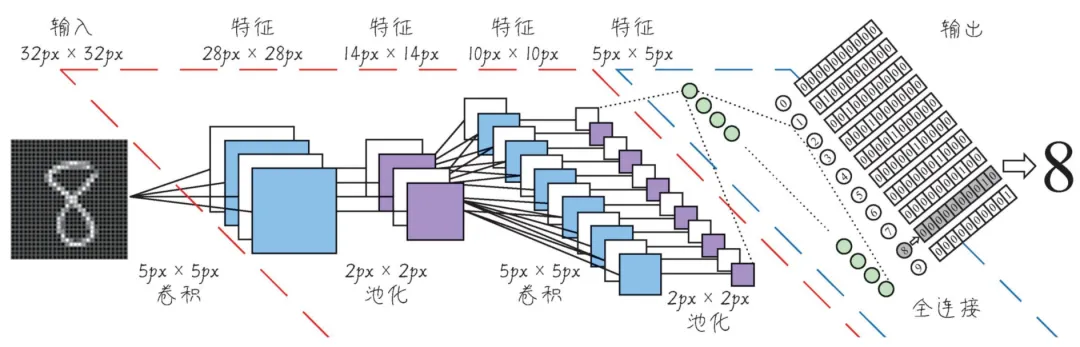
而深度神经网络,通常是指层数很多(网络隐藏层)的神经网络,例如上图中的网络隐层。现在的网络隐藏层可以是几万层或者无限层,层数越多,下一层就可能学习到新的特征,也就能够处理越复杂的问题,处理问题的效果也就越好,当然,需要的计算资源也越高,成本当然也就越高。
近年来,深度学习常常用在复杂问题的处理上,如图像识别、目标检测、NLP、机器翻译等领域,它需要大量的数据和大量计算资源,特别典型的基于深度学习的模型就是Transformer。
Transformer
Transformer是大语言模型的基础架构,是深度学习时代跨时代的产物,它于2018年由Google研究员提出。
Transformer是一个具有Encoder(编码器)和 Decoder(解码器)的架构,有的模型只用了Encoder(如BERT),有的模型只用了Decoder(如GPT),还有的模型Encoder和Decoder都有使用到(如T5)。
它最初是为了解决从序列到序列(Seq2Seq)的任务,比如说机器翻译,它先给语言做一个编码,然后再解码,就能够实现完成这个机器的翻译。
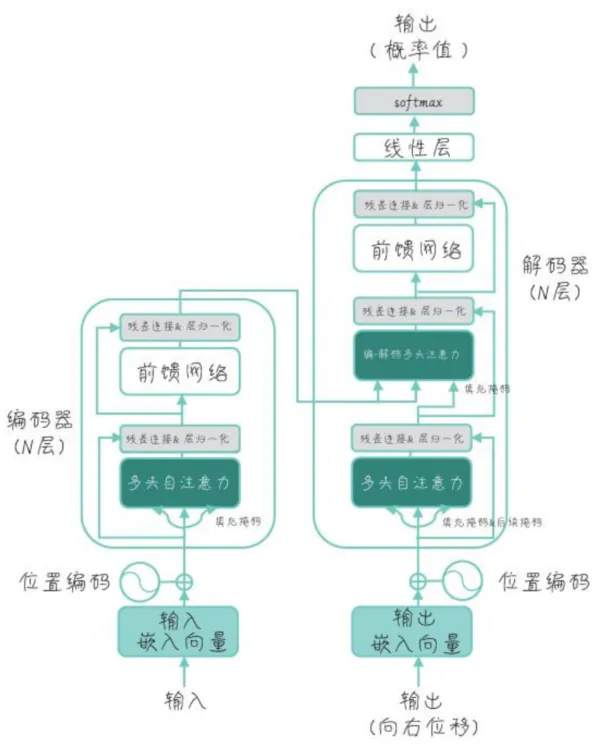
Transformer架构中最核心的内容就是引入了自注意力机制,通过自注意力和多头自注意力机制实现了并行,通过层的堆叠来实现模式的学习,不需要任何的RNN在里面。
从Transformer演化出了GPT,或者说GPT是基于Transformer的一个自回归的模型,它只用到了Transformer的Decoder(解码器)。所谓自回归任务,就是专注于预测序列中的下一个字(严谨点说是Token),如下图所示:
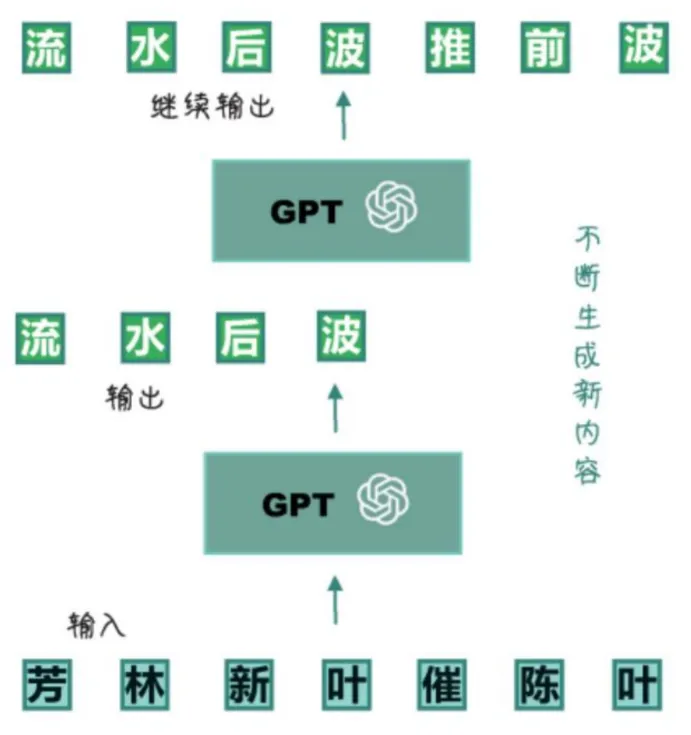
GPT通过自回归模型进行预训练,在进行预训练的时候,模型会被输入大量的文本数据,然后开始预测每一个词的下一个词,如此往复,直到整个句子说的差不多了,不断生成新内容。通过这种方式,GPT学习到了语言规律、语法、词法、词汇搭配等等,然后生成的都是自然流畅的文本。


机器学习的应用场景
对于机器学习,有两种主要的应用场景:回归问题 和 分类问题。
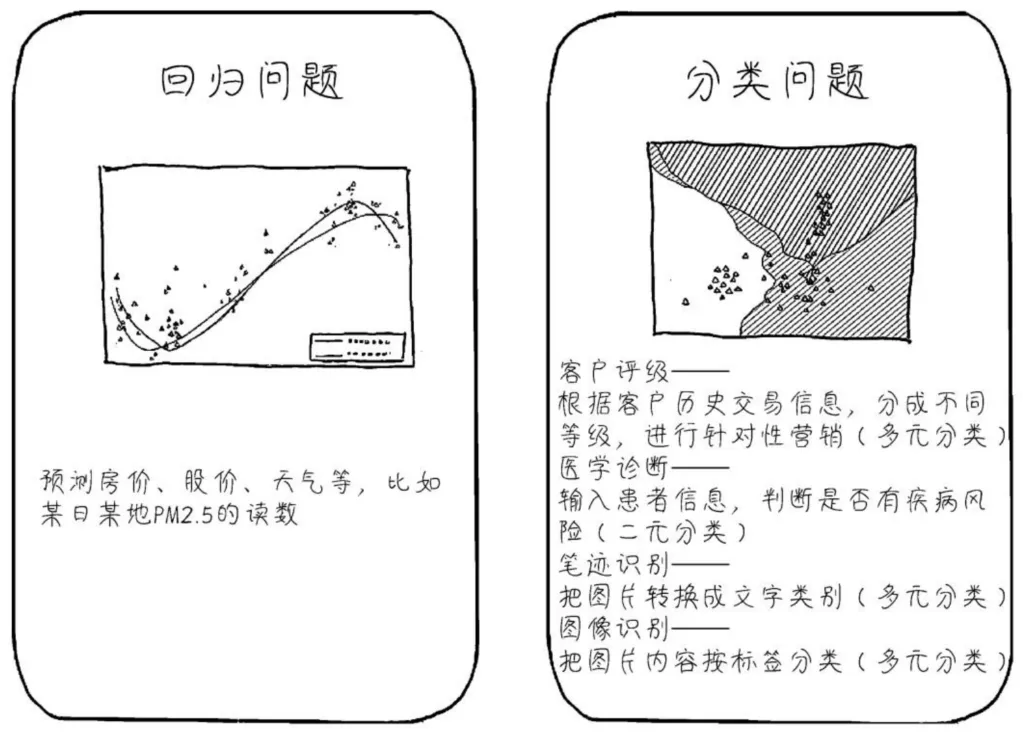
(1)回归任务通常是预测一个连续的数值,例如预测未来的房价、股价、天气等,这些预测结果都是一个数值。
(2)分类任务通常是预测一个离散的标签,是以一个概率形式呈现的离散标签,换句话说就是这个东西出现的可能性有多大,比如识别图片出来是猫还是狗,这就是分类问题。分类任务比回归任务的业务场景通常来说要多一些,比如给客户评级(L1 L2 L3 L4等不同的等级)、医学诊断某个病人是得病还是没有得病(二元分类)等。
小结
本文快速温习了AI相关的必备基础理论,下一篇我们要搭建机器学习的开发环境。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。



![NSSCTF--Crypto--[强网拟态 2021]ONLYRSA](https://img2024.cnblogs.com/blog/3522845/202412/3522845-20241216182614744-1666929494.png)